-
Processes
- In this week, we will cover the following topics:
- Process Creation
- Processes and Structure
- Job Control
- Signals
- Pipes
- Cron
-
3.1 Processes and Threads
In the last lecture we stated that a process is
… is defined as an executing image of a program including its data and register values and stack. It executes in a virtual machine environment and has system resources allocated to it (memory, files, I/O devices...). “The program runs within the process”. To the process it looks like it has the machine to itself.This definition is important – remember it!
A thread is:
… a concept associated with a process. Essentially a thread is an independently schedulable execution path through a process (more later). Consider at the moment that processes have one thread only. -
3.2 Processes
- A program is a passive entity.
- the kernel manages the creation of the corresponding process
- a process is an active entity
- a process is an instance of an executing program
- The process runs within the context of a virtual machine.
- this is a term that can mean different things but here it simply means that the machine the process “sees” is the system call interface and not the hardware directly.
- So when you write a C program and run it, the OS kernel allocates memory to it and creates the corresponding process, giving it a unique process id (pid).
- your program contains calls to system calls
- it accesses I/O devices through device driver code which is in the kernel and accessed through calling these system calls.
- The kernel contains a data-structure called the process table which maintains information about running processes and their allocated resources
- indexed by pid
- where the ps and top commands etc. get their information from
- as it’s in the kernel it can only be accessed in a controlled manner using system calls (so the ps source code calls these)
-
3.3 Processes in modern operating systems
Processes are a fundamental and important concept. You will not understand much of this module unless you understand the fundamentals of processes! Modern Oss, Windows, Linux, Mac OS X… are process-oriented.
3.3.1 Process structure within the OS
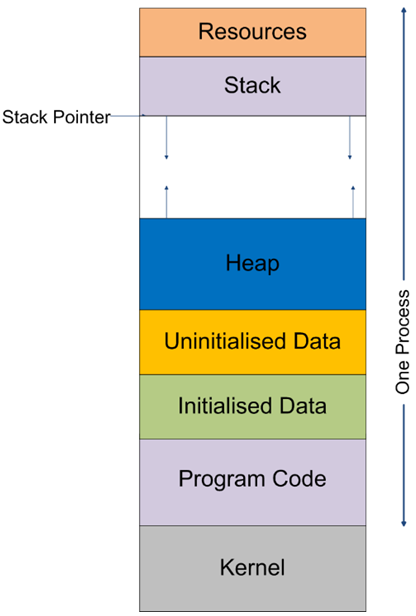
Figure 3: Process Structure. - The structure, presented in Figure 3 of a process within the OS relates to a number of concepts,as follows:
- Program Code: compiled machine code that CPU executes, often read-only.
- Initialised and Uninitialised data: memory areas for variables, the size predictable at compile time from program code.
- Heap: for dynamic data, the size of which is unpredictable at compile time.
- Stack: the run-time stack maintains data associated with calling methods/functions (arbitrarily nested) and local variable values associated with them. The stack pointer is used to find the execution environment of the current executing function.
- Resources: values of the command line arguments and environment variables.
- Shared memory (not shown): areas of memory which can be connected to multiple processes facilitating a form of unstructured inter-process communication. Remember processes are usually sandboxed from one another, i.e. they are kept separate from one another. The kernel is implemented as a special area of shared memory connected to all processes.
More about memory: These coarse areas of memory within a process are sometimes referred to as segments. Segments can be independently protected (some are read only) or shared, e.g. the program code segment can be shared which makes sense if there are many identical processes executing the same program. The process address space is split into fine-grain pages and some pages may be temporarily on disk. The program (and programmer) is not aware of paging a typical page size on desktop Linux is 4KB. At any time, there may be 100s processes so main memory must be used as efficiently as possible.
-
3.4 Process Creating and ending proceses
3.4.1 Process Creation
All UNIX-type OSs follow the same basic mechanism to create a process.
- Normally (but not always) we create a process by running a program from a shell.
- that shell is itself a running process of a shell program (e.g. bash).
- The shell (the parent process) forks an identical copy of itself (the child process) and then the child does an exec to execute (transform itself into) the new program.
- the pid of the child process is returned to the parent
- the parent may be suspended (synchronous) until the child completes or it may continue executing (asynchronous)
- the parent can pass command line arguments to the child on creation
- the child can pick up a copy of the parent’s environment variables and open files etc.
3.4.2 Exit values
- On termination, child processes will return an integer exit status value which can be picked up by the parent.
- this value is sometimes also called the termination status or return status
- By convention 0 indicates success; a non-zero value indicates an issue which can be found usually in the manual page.
- some of these values are fixed by convention:
- 🔗 http://www.faqs.org/docs/abs/HTML/exitcodes.html#EXITCODESREF
- In bash (and other shells) exit values can be:-
- set using exit n at script termination
- subsequently picked up in the parent shell using $?
- this is important as it's used a lot
3.4.3 Zombie Processes
- When a child process exits some housekeeping information sticks around in the process table.
- this is termed a zombie process
- The parent process is supposed to execute the wait() system call to read the dead process’s exit status and other information.
- after wait() is called, the zombie process is completely removed from memory and the process table
- However if the parent process terminates first or is badly written, zombie processes can stick around in the system using up resources and pids. More issues about this are discussed at: 🔗 http://www.howtogeek.com/119815/htg-explains-what-is-a-zombie-process-on-linux/
- notice this article also discusses the top command which is very useful!
-
3.5 Process Relationships and Job Control
The use of “parent” and “child” implies a tree-like representation of related processes can be drawn. Try:
pstree –p –h
ps is used to list running processes with pid. Try these:
ps –u <username>
ps aux
psgrep <executable-name>
psgrep -fl <executable-name>
In fact, what happens usually is that when a terminal is opened it creates a session with a shell process called a controlling process.
- The controlling process creates child process groups or jobs containing 1 or more processes.
- processes connected by pipes form a single process group.
- Jobs can be controlled
- process groups can be suspended and started back up as a unit
- disconnected from the terminal and moved to the background etc.
- see labs
3.5.1 Is the kernel a process?
No. The kernel is best thought of as a secure area of shared memory woken up by system calls and interrupts. Processes run as user-processes i.e. they execute in user-mode and periodically execute kernel code with elevated security. Normally Linux user-processes expect to be connected to a terminal or the input/output is redirected from/to a file.
However, daemon processes run in the background and are not connected to a terminal, to perform a background task e.g. sshd which listens for ssh connections, although there is no other conceptual difference to a user-process. Processes can be permitted to run with elevated privileges see Week 9.
Although this course focuses on Linux, it is worth pointing out that, in Windows, a daemon = a Windows service.
-
3.6 Signals
- Linux abstracts away from hardware interrupts to include these with program and OS generated software interrupts called signals. These can be both generated programmatically and handled in shell and C programs. A number of points are worth noting:
- signals occur asynchronously with respect to program execution
- the “type” of a signal is defined as an integer (or by a corresponding symbolic constant)
- use 9 or SIGKILL to “kill” a process
- SIGKILL cannot be ignored (i.e. masked).
- this is should be the signal sent as the last resort as processes will not exit gracefully e.g. flush data to disk.
- other options to try first on following slide.
- e.g. kill -9 1234
- You can see a list of kill signals by using the following command. Each signal has a different purpose.
- kill -l lists signals.
- Linux also includes 2 shell commands for signals:
- the kill command to send a signal to a process with a given pid (or job number)
- “kill” is a misnomer as it is used to send any signal
- only root (the superuser) can send signals to processes they do not own
- A variant of kill is killall which allows processes to be sent signals by process name.
- the trap command is used to implement a signal handler which is executed on receipt of a particular signal
- this is optional – the default behaviour is often just to exit.
- no trap can be associated with SIGKILL however.
- see Lecture 6 and Lab 2. We will also return to signals in C later because, in a similar way to trap, signal handler functions can be implemented in a C program.
- Other common signals:-
- 2 or SIGINT is generated on receipt of (by default) <ctrl> + c from the keyboard
- 3 or SIGQUIT is generated on receipt of (by default) <ctrl> + \ from the keyboard and generates a core dump for debugging
- 0 or SIGHUP is sent to a process if its parent dies, for example, if you log off when a background process is running
- 15 or SIGTERM is the kill default which is the regular terminate signal to end processes gracefully
- 17 or SIGCHLD tells a parent process to execute the wait() system call and clean up its zombie children.
-
3.7 Pipes
- Pipes or pipelines are a form of inter-process communication with specific characteristics:-
- streamed, unidirectional, large volume communication with synchronisation
- the | (pipe) symbol in the shell
- The output from the first process is used as input to the second and so on.
- e.g. ls –l | wc –l
The processes in a pipeline are created by a common parent process so that the file descriptors are shared and inherited from the parent process. The processes in the pipeline are all in the same process group and can therefore be suspended as a unit.
3.7.1 pipefs
The module pipefs is an example of a virtualised file system, which is discussed more fully in Lecture 7.
- The first process creates a new non-persistent temporary file in pipefs which behaves like a normal file:
- stdout in the first process is redirected to the temporary pipefs file
- stdin in the second process is redirected to the temporary file
- and so on along the pipleline.
Sometimes pipes like this (with the shell |) are called un-named or anonymous pipes as they have no name or file system object associated with them (at least in the normal file system).
Some examples on creating processes and using pipes in C will be in the final C lab; pipefs is mounted but is not directly accessible from shell tools. it is accessible from C
- Synchronisation is implemented to suspend either process should pipefs overflow or there be no data to process as appropriate. Named pipes are an alternative technology with other features allowing unrelated processes to communicate. However, his is beyond the scope of this module.
- see: 🔗 http://www.linuxjournal.com/content/using-named-pipes-fifos-bash
-
3.8 Dates, Times, the cron daemon
- Linux/UNIX/POSIX time is given as the number of seconds that has passed since 00:00:00 Coordinated Universal Time (UTC), Thursday, 1 January 1970, not counting leap seconds.
- this is the start of the epoch
- e.g. date -d "3 PM 12 September 1987" +%s
- gives: 558450000
- The crontab -e command allow commands/scripts and maintenance utilities to be scheduled at specific dates and times:
- this is managed by the cron daemon which you do not deal with directly
- see: 🔗 https://www.marksanborn.net/linux/learning-cron-by-example/