-
File Systems and Users & Security
In this week, we will cover the following topics:
- File Systems:
- Basic Concepts
- File System Types and Implementation
- inodes, Files and Directories
- Hard and Symbolic Links
- Devices and Terminals
- Mounting, File Descriptors and Virtualised File Systems
- Users and Security
- root, su and sudo
- Discretionary Access Control
- Users and Groups
- The Password File
- Access Control Lists
- Permissions for Directories
- Special Permission Bits
- umask
- Process Hierarchy, Booting and Run Levels
-
4.1 Prerequisites
- You must have worked through Shott’s online tutorial “Learning the Shell” (see lab material), in particular have a working knowledge of:
- basic Linux file system commands and navigation
- “A Guided Tour”
- “I/O redirection”
- i.e. Sections 1 through 7
-
4.1.1 Disk drives
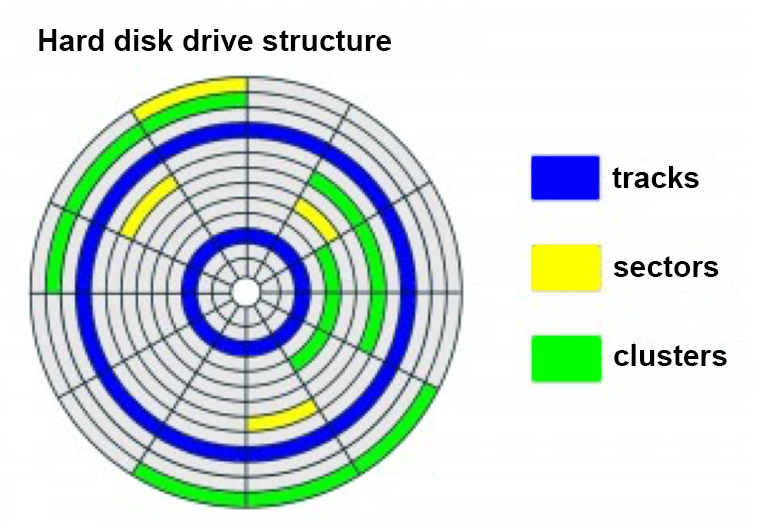
Figure 2: Facts about hard disk drives. - Here are some facts about Hard Disk Drives (HDD):
- Hard disks are constant angular velocity devices.
- Formatting lays out the disk into concentric tracks containing equal sized sectors (usually of 512 bytes)
- file contents will be made up of a sequence of blocks (MS clusters)
- each block will map to n contiguous sectors
- where n is dependent on the volume size and fixed
- a hard disk has multiple identical 2-sided platters
- the same track across the platters form a cylinder
- you want to keep the sectors of a file all in the same cylinder/track as much as possible (or at least contiguous) so as to minimise disk head movement
- in other words increase their locality
- otherwise the file system is said to suffer fragmentation
- file access becomes slow
- you need to periodically defragment the file system by moving sector data around (itself slow)
- File systems lay out a roadmap to find the sequence of blocks for a given file.
Solid State Drives: The world is moving (moved?) to solid state drives (SSDs). On a SSD there are no moving parts, but file sector locality can increase the size of each transfer request while reducing the total number of requests. This locality may also have the effect of concentrating writes on a single erase block, which can speed up file rewrites significantly. Therefore, it is useful to reduce fragmentation even on SSDs whenever possible.
-
4.1.2 File Systems
Modern systems allocate disk space on an "as needed" basis, dividing a file into fixed sized pieces: called dynamic allocation or fixed block allocation (FBA), what (Microsoft) file systems call clusters but in UNIX/Linux are called (logical) disk blocks. With FBA, half of the last block is unused on average, called slack space or cluster overhang
- There are two general FBA implementation techniques:
- table of all blocks: First block for a given file points to the next entry for next block and so on i.e. chaining (a linked list). This single table must be large enough to map all disk's blocks (FAT). No direct access to middle of file i.e. must follow chain
- data structure for each file: Data structure points directly to all blocks for a given file (UNIX inode and NTFS). Hard to have large files (table size fixed). Needs modification.
In file systems, files are accessed through a stream abstraction; even though a file is split into blocks on the disk, processes see the file as a stream of bytes – the operating system hides the blocks. File systems maintain state information i.e. information about open files, which includes the value of the file pointer i.e. a variable which holds the current position within an open file to which reading (or writing) has got to. These are known as stateful operations, and are typical in non-distributed systems.
Files are unstructured sequences of bytes: there is no record structure imposed on files or any complex organisations (e.g. random files, indexed sequential files…) by the operating system.
if an application wants this it must implement it (or use an API library which implements it) - this simplifies file system implementation
- Some facts about files:
- File use characteristics have a direct bearing on file system design. Most files are small, so any implementation is optimised for small files but some files can be huge and this needs to be catered for (transparently)...
- Random access is rare; most accesses to files involve processing the entire file sequentially
- The majority of files are opened for reading only, and rarely for writing.
- Most files have a short lifetime.
- Few files are concurrently shared.
- locking is required however
- either shared or exclusive
- either on a file basis or on specific areas within a file
- Last writer wins is also a common access use case.
- consider 2 instances of gedit editing the same file
- the file is completely read into memory to edit and then written back later
-
4.1.3 Partitions and Volumes
- Physical disks (or physical volumes) will consist of one or more partitions (or (logical) volumes)
- each partition contains files, directories and file system data for that partition. In the simplest case there will be one partition on each physical disk.
- it is also possible for partitions to span physical volumes
- Partitions may be used to support different file system technologies
- alternatively partitioning is used to place a first level logical structuring on files to increase operational efficiency or to allow secure sharing of particular partitions over a network.
-
4.1.4 Journaling File Systems
Many operations on file systems are composite in nature - e.g. deleting a file typically requires its entry in a directory to be deleted and its data blocks freed up. Should a problem occur, e.g. a system crash in the middle of such an operation, it can leave the file system in an inconsistent state. In this example, it would require the entire volume to be checked and fixed on reboot, a potentially slow process as today’s file systems can be large.
MS NTFS and the native Linux ext4 (and ext3) are examples of robust journaling file systems. i.e. current generation file systems. A journaling file system keeps a journal or log of the changes that are being made to the file system during disk writing that can be used to rapidly fix corruptions that may occur due to an event such as a system crash. Update information is maintained in a journal log area on the disk during each write. After a crash the file system can very quickly be brought back on-line with any necessary fixes using the journal log.
- Why does this work as the journal log is on the disk too and may itself get corrupted?
- writing a journal transaction is generally much faster (and the volume layout is optimised so it is) than the data operations it describes
- as it is quicker the chances of something going wrong are reduced
- however ultimately there are no guarantees even with journaling.
Copy-on-write: an alternative to journaling in which new disk blocks are allocated on a write and the system updated if a problem occurs the old data still exists.
-
4.1.5 Linux File Systems
- Current Linux versions will support:-
- ext4 (the Linux native file system implementation i.e. inodes)
- ext2 and ext3 (earlier versions of ext4)
- tmpfs (for swap space, shared memory segments – not persistent)
- FAT (16 and 32 bit for USB keys etc – old MS file system technology)
- NTFS (for mounting Windows volumes – current MS file system technology)
- virtual file systems e.g. proc and pipefs
- various others
Virtual File System (VFS): Linux’s VFS implements a layer which makes other file system technologies look like a traditional native Linux inode file system, i.e., it makes all supported file systems appear like an ext2 file system
-
4.1.6 Native Linux File System Structure
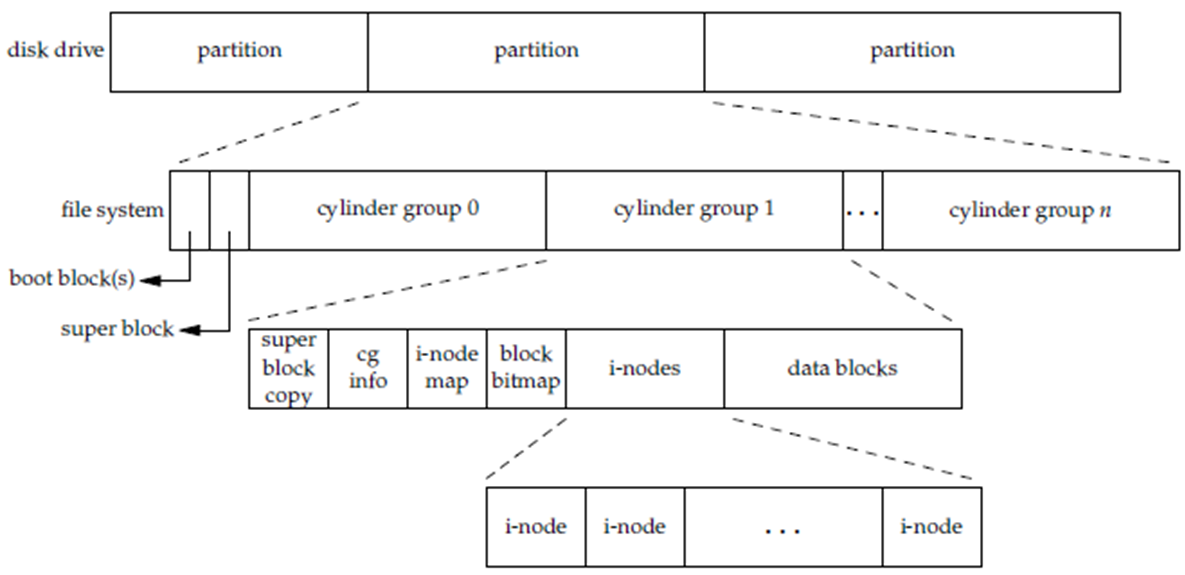
Figure 3: Native Linux File System - Superblock:
- The superblock contains meta-data about the partition.
- Multiple redundant backup copies. Includes:-
- size of other areas on partition
- cluster size
- mount status
- volume label
- volume encryption algorithms
- etc. etc.
- Each partition is split into (cylinder) block groups.
- this aids locality by keeping inodes physically close to their file data blocks
- the cg info (or block group descriptor) holds the location of the inode table for that block group
- however the inode numbering space is the whole partition
- i-nodes:
- The native Linux ext2, ext3, ext4 and VFS file systems are inode-based systems.
- There is one inode (“index node” but always pronounced “eye-node”) per file and a reserved area containing the inodes called an inode table.
- you will also see i-node which is the same thing
- each file therefore has an inode number or inode pointer
- An inode contains the meta-data for a file (not its name/path though) and roadmap of where the file’s data blocks can be found in the group.
- size, timestamps, mode/permission bits, owner ID, group ID...
- access is optimised (i.e. quicker) for small files
- try: stat <file> to print inode details</file>
- ls –i will display file inode numbers
- ls -s the number of data blocks allocated to each file/dir in current directory
- the summed block count is the “total XX” at the top of ls -l etc.
- inode Table and Bitmaps
- A modern implementation of an inode table reserves several inodes at the beginning at well known locations. Includes inodes for the:-
- root directory
- journal file
- undelete directory
- A separate block bitmap tracks the usage of data blocks for the group.
- each bit in the block bitmap indicates whether a specific data block in the group is used or free
- a single block
- Similarly an inode map (or inode allocation bitmap) tracks the usage of inodes for the group.
- each bit in the inode map indicates whether a specific inode in the group is used or free
- a single block
-
4.1.7 Directories
- A directory is implemented in the same way as files are implemented. However, its contents have a special format - a list of directory entries, which is a sequence of records, one for each file in the directory, each containing:-
- file name (or name of subdirectory if that’s what it is)
- inode number from which the metadata/contents are found
Path name lookup involves traversing each component of a path, ensuring it is valid, and following it to the next component. This means traversing each inode for each directory in turn, getting and processing its contents and so on until we get to the actual file. Each path component (including the file) is often called a dentry. Such traversal is heavily cached as it can be expensive.
-
4.1.8 Directories and links
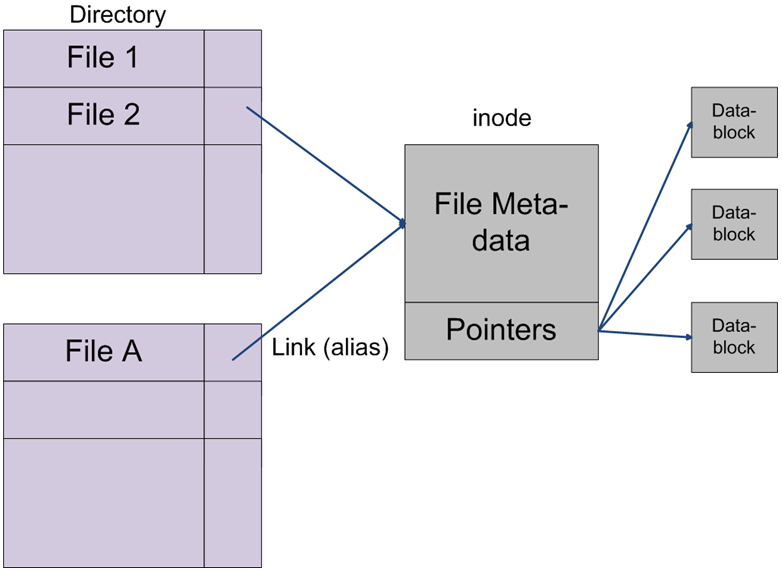
Figure 4: Directories and Links. - Links:
- Multiple directory entries may link to the same inode.
- a kind of “alias” mechanism
- sometimes these are called hard links
- think of the consequences of this if you change a file’s contents or delete a file...
- the file is not removed until all hard links to the file are removed
- ls –l second field shows number of links associated with the inode
- ln command manages links e.g. creates a new file system entry pointing to an already extisting file/inode and will still work if moved
- not for directories – files only
See exercise in Lab 2.
However hard links cannot span partitions…
- Symbolic Links:
- the scope of inode numbers is limited to a single partition so hard links cannot span partitions
- introduce symbolic links (sometimes called soft links or symlinks)
- rather than holding an inode number these hold the textual path of the mapped location where the object actually is
- a separate inode is used for each symbolic link
- transparent to applications - often used to kid-on that installed software is at a particular file system location but it is in fact somewhere else i.e. used if short on space in a partition
- can be used with directories
- become useless when you remove the target file
- ls –l will display a'l' in first field and show mapped location
- ls -ali is useful...
- ln –s to create symbolic links
-
4.1.9 Key Linux philosophy: everything is a file
- The “everything is a file” phrase means is that every device has an entry in the file system:
- in /dev and subdirectories
- in fact not just devices but also symbolic links, pipes and sockets
- devices like the terminal can be treated like files
- this simplifies redirection as no code changes are required
- it also reduces the number of programming interfaces that need to be implemented and learnt
- The kernel makes the distinction between: character devices, which are low volume sequential-access devices e.g. the terminal; block devices, which are high volume random-access block-oriented devices e.g. disks, optical storage devices...
- character devices, and block devices types are (very) likely to be buffered, even the terminal keyboard (e.g., so you can edit text before hitting <RETURN>)
How things look in a terminal:
wolfgang@meitner> ls - l /dev/sd(a,b) /dev/ttyS(0,1) brw-r----- 1 root disk 8, 0 2008-02-21 21:06 /dev/sda brw-r----- 1 root disk 8, 16 2008-02-21 21:06 /dev/sdb crw-rw---- 1 root uucp 4, 64 2007-09-21 21:12 ttyS0 crw-rw---- 1 root uucp 4, 65 2007-09-21 21:12 ttyS1
- The 'b' and 'c' in the first field indicate block or character device.
- The numbers "8, 0" are the major and minor numbers.
- the major number is the device driver (here a SATA hard disk)
- the minor number differentiates the devices (2 disks in this case sharing the same device driver)
- tty etc. refers to terminals (see later).
- /dev/null is a data-sink used to suppress output.
In summary, three types of file system entry on UNIX/Linux:-
Ordinary Files: Contain either text or binary information. Text files are human readable. Binary files are machine readable and often contain executable code.
Directories: Contain information to allow access to all types of files but do not contain any data. Each entry in a directory represents either a file or another directory.
Special Files: Usually represent devices available on the system. They are typically located in the /dev directory or its subdirectories. Also includes named pipes, sockets and links (both types).
-
4.1.10 Terminals
- As we know multiple terminals can be created, each associated with a shell process. There is, however, a bit more to this. Originally, each terminal would have been a physical teletype terminal (a "dumb terminal") connected to a central mini-computer through a serial cable. A lot of the original terminology remains as a legacy; a Linux implementation on a workstation will still support several virtual terminals which act just like this:
- present a login dialogue
- no X Window environment – text only
- <ctrl>+<alt>+<F1> etc. to access
- <ctrl>+<alt>+<F7> to return to the graphical desktop
- With X Windows installed and active (and a desktop e.g. Xfce as in the labs) we create pseudo terminals.
- see:- 🔗 http://www.linusakesson.net/programming/tty/
- non-login terminals
- In both cases escape characters etc. usually adhere to some standard on how they are interpreted or displayed.
- see:- 🔗 https://en.wikipedia.org/wiki/Terminal_emulator
- the terminfo database details the escape characters and capabilities of different terminal types, see: /lib/terminfo
- $TERM holds your current terminal type
- Pseudo terminals are implemented using terminal emulators. Standard Linux desktops (including Xfce) provide their own terminal emulator implementation (e.g. xfce4-terminal). In general virtual and pseudo terminals:-
- are character devices
- see tty command usage
- for each virtual terminal a tty device exists as/dev/ttyN etc.
- manage connection of shell process to stdin, stdout and stderr
- convert key strokes and combinations into control commands (including to signals)
- keyboard buffer and editing
- handle display formatting (e.g. changing colour)
- copy and paste
- manage connection to other drivers for the keyboard, mouse (via USB if necessary) and display window etc.
Pseudo Terminals:
For each pseudo terminal a pseudo terminal slave device is created as /dev/pts/N which is (usually) connected to a shell process and exactly emulates a classic serial terminal.There is also a pseudo terminal master device which is connected to a terminal emulator process. Data written to the slave is presented to the master device as input. Data written to the master is presented to the slave as input. ssh (or telnet) works the same way:-i.e. for each ssh or telnet connection a pseudo terminal slave device is created as /dev/pts/N.
-
4.1.11 Mounting File Systems
UNIX/Linux type operating systems have no drive descriptors and all mounted partitions share the one file system tree. There are no drive descriptors a la MS Windows. Partitions must be explicitly mounted and unmounted to the desired mount points (including removable media). The mount command and see df –T cd’ing and paths etc. spanning partition boundaries are transparent partitions to be mounted at boot-time are listed in /etc/fstab partitions currently mounted are listed in /etc/mtab equivalent to executing mount on its own there is also now a hot-swap daemon, udev, for modern devices e.g. mp3 players.
-
4.1.12 File Descriptors
File descriptors are small non-negative integers that the kernel uses to identify the files opened by a process, and so are kept on a per-process basis – integer usage is quicker (in C). Opening/creating files returns a new file descriptor number used for subsequent file access.
- 3 file descriptors are reserved by convention in the shell (and C etc.) by default all attached to the terminal:-
- standard input (stdin)
- standard output (stdout)
- standard error (stderr)
- Of course, a program is not restricted to these and may open other files directly (with kernel allocated file descriptors numbers):
- try: ls –l /proc/$$/fd
-
4.1.13 Virtualised File Systems
- The most common ones are:-
- proc which is mounted at /proc
- pipefs which is used to implement (anonymous) pipes
In fact, both are emulated file systems inside the kernel.
- proc allows kernel information to be exposed in a file system format. Includes:-
- kernel information
- CPU information
- information about the running system e.g. uptime
- detailed information about running processes
- in directories named by pid
- look in subdirectory fd to see file descriptors
- i.e. in /proc/<pid>/fd
-
4.2 Users and security
4.2.1 Multi-User Linux and access control
- Linux is a multi-user OS and default there are two on a workstation. For example:
- a standard user (e.g., “student” on the Mint version used in the labs). Standard users have restricted access. Standard users can be easily created.
- the root user or superuser or su with unrestricted access to everything
The root user (root/su) can do anything and you can easily wreck a Linux installation logged in as root, e.g. you could delete everything or you could do something by mistake which isn’t easily reversible. Additionally, direct root access is now viewed as a key security vulnerability. Access to root is locked by default in modern Linux distributions and is now normally provided through sudo, one command at a time, rather than by logging in directly as root or using the old su command.
Therefore, there is a need for a security mechanism to be provided...
Access Control (DAC)
Discretionary access control (DAC): is the standard model used in most operating systems. Users can protect what they own and the owner may grant access to others, and define the type of access (read/write/execute) given to others.
Mandatory Access Control (MAC): is alternative model not we will not discuss below, although it is worth noting its characteristics: multiple levels of security for users and documents defined by the system administrator with strict control. MAC is especially used for high security deployments and is, e.g., used for government or military deployments. An example of a linux OS with this kind of access control is SELinux (Security Enhanced Linux).
-
4.2.2 User identity
UIDs: Linux/UNIX for efficiency allocates to all users a unique positive integer user id, UID, rather than having to deal with string usernames internally. The mapping of username to UID is in the text file:
/etc/passwd
On Ubuntu/Mint UIDs start at 1000 for created regular users. The actual value allocated is arbitrary; the UID space for regular users is unique and will most likely differ from host to host. Your UID can be shown by typing:
id or id –u or $UID
… on the command line.
system users include root (UID=0) and unique accounts created for system daemon processes UIDs < 1000.
Other identity related commands for finding users include: who, who –a, whoami, who am i etc.
GIDs: positive integer group ids, GIDs are also integer values, for the same reasons as above. The mapping of username to default group GID is in the text file:
/etc/group
A user can be a member of many groups, only one active at a time. Your group membership details are shown by groups or id or id –G $USER. Your current active group shown by id –g –n, can be switched by executing newgrp, and usermod can be used to edit group membership.
As users are created a new default group is created for them with the same name as the username. File group ownership can be subsequently changed with chgrp. Again, the GID space may differ from host to host. You may have to use chgrp to change group ownership when transferring files need su permissions.
-
4.2.3 System Files: adding users, managing passwords
- Regular users are added using useradd and modified with usermod:-
- 🔗 https://www.digitalocean.com/community/tutorials/how-to-add-and-delete-users-on-ubuntu-12-04-and-centos-6
- Password file (/etc/passwd)
- example below – see man 5 passwd for detailed field usage
- contains account information for users on a per-user basis
- username, UID, GID, real name, home dir, login shell
- note (ironically) the (hashed) passwords are no longer actually kept here and are now in a more secure file...
- an ‘x’ marks the second field where they once were for backwards compatibility
- it’s a readable textfile with a predictable structure so it can be pulled apart...
- hash values of actual passwords and expiry information are now in /etc/shadow with tighter permissions
- the password file can also be searched with getent e.g.
- getent passwd student
-
4.2.4 Access Control
An access control list (ACL) for a resource (e.g. a file or directory) is a sorted list of zero or more access control entries (ACEs). An ACE specifies that a certain set of accesses to the resources is allowed or denied for a user or group. A UNIX/Linux file system object has an ACL with 3 ACEs for owner, group and other, respectively, each marking read, write and execute permission, i.e. the three sets of rwx permission bits manipulated by chmod, getfacl and setfacl.
Linux ACL’ have allow-only ACEs; access to a file depends on ACL of file and of all its ancestor directories in its path. Each directory must have execute (cd) permission and different paths to same file not equivalent. A file’s ACL must allow requested access.
- Other points include:
- file permissions do not restrict root
- only root can create and modify groups
- chgrp and chown have a –R (recursive) option to include (nested) subdirectories - use with care as no way back easily!!
- octal equivalents of the bits can be used e.g.
- chmod 755 myshellscript.sh
More Sophisticated ACL Control: …beyond module scope, but be aware of:
getfacl and setfacl commands which allow more control over ACLs
upper bounds on permissions can be set
default permissions can be set (setfacl and umask)
extended ACLs exist which allow permissions to be set on a per-user basis (again using setfacl).Permissions for Directories: Permission bits are interpreted differently for directories. The read bit allows listing names of files in directory, but not their properties like size and permissions. The write bit allows creating and deleting files within the directory. The execute bit allows entering the directory and getting properties of files in the directory.
* The final exercise in Lab2 is about groups and other users in a multiuser Linux environment.
-
4.2.5 Special permission bits
- Three other (special permission) bits exist:
- Set-user-ID (“suid” or “setuid”) bit
- Set-group-ID (“sgid” or “setgid”) bit
- Sticky bit
… which we will now cover
- Set-user-ID: The ‘Set-user-ID’ (“suid” or “setuid”) bit on executable files, causes the program to run as file owner regardless of who runs it e.g. the password command runs as root (this is the command, the password file /etc/passwd is something different...)
- ls -l /usr/bin/passwd
ignored for everything else.
- in 10-character display, replaces the 4th character (x or -) with s (or S if not also executable)
- rwxr-xr-x: executable by all, but setuid unset.
- rwsr-xr-x: setuid, executable by all.
- chmod u+s file.
- rwSr--r--: setuid, but not executable.
- Set-group-ID: The ‘Set-group-ID’ (“sgid” or “setgid”) bit on executable files, causes the program to run with the file’s group, regardless of whether the user who runs it is in that group on directories, causes files created within the directory to have the same group as the directory, useful for directories shared by multiple users with different default groups ignored for everything else in 10-character display, replaces 7th character (x or -) with s (or S if not also executable).
- rwxr-sr-x: setgid file, executable by all.
- drwxrwsr-x: setgid directory; files within will have group of directory.
- -rw-r-Sr--: setgid file, but not executable.
- Sticky Bit: On directories, the ‘Sticky Bit’ prevents users from deleting or renaming files they do not own ignored for everything else in 10-character display, replaces 10th character (x or -) with t (or T if not also executable):
- drwxrwxrwt: sticky bit set, full access for everyone
- chmod +t file
- drwxrwx--T: sticky bit set, full access by user/group
- drwxr--r-T: sticky, full owner access, others can read (useless)
Default Permissions for Files and Directories
- For a new file the default permissions are 0666 (octal). The leading digit is for the special permission bits (here not to be set); if it’s 0 you can in fact drop this digit in command usage:
- e.g. chmod 777 myscript.sh etc.
For a new directory the default permissions are 0777. In order to avoid files being created with insecure or undesired permissions a umask permission value is subtracted from the default permissions for a file or a directory. umask allows the current umask value to be displayed or modified usually 0022 effective file creation permissions 0644 effective file creation permissions 0755.
Process Hierarchy
- UNIX/LINUX has a tree-like hierarchy containing all processes which is linked by parent-child relationships. As an abstraction this can be viewed as similar to the file system tree with particular processes being owned by users. Note:-
- see: pstree
- users can only signal processes they own (i.e. kill them!) unless logged in as root
- orphan processes can exist if their parent process dies first. These processes are adopted by init automatically.
- when a child process dies its parent must accept its exit code (wait() system call) - if it doesn't the child releases its resources but still uses an entry in the process table and is termed a zombie.
-
4.2.6 Booting
Linux Boot Sequence: GRUB2 (Grand Unified Bootloader) is the default OS loader for Linux. In the master boot record on the boot partition specified in the BIOS boot order GRUB will load an installed Linux kernel off the disk or present menu choices as appropriate. Traditionally once the kernel is loaded it passes control to the master init process (pid always 1); in a modern Linux distro this could be init and/or one of its more modern replacements e.g. upstart or system all processes ultimately have “init” as their root ancestor try: pstree –h “init” will start up services (daemons) as specified in scripts in /etc/rc. For virtual terminals a login process will be forked, which ultimately forks the correct shell process as specified in the password file. With a X Windows based desktop this is more complex but ultimately the graphical environment is started.
- Runlevels: A system can be booted into one of several runlevels, each of which is represented by a single digit integer. Each runlevel designates a different system configuration. This allows a different combination of services to be started as appropriate for the current deployment
- try: who –r or runlevel
- Again the following are historic, but of use:
- 5: multi-user, X Windows, desktops
- 3: multi-user, command line only, servers
- 2: sometimes seen on Linux - multi-user, X Windows, desktops
- 1: single user – really used if password file etc. corrupted and need system recovery
telinit allows runlevels to be changed but handle with care...