-
The Era of Big Data
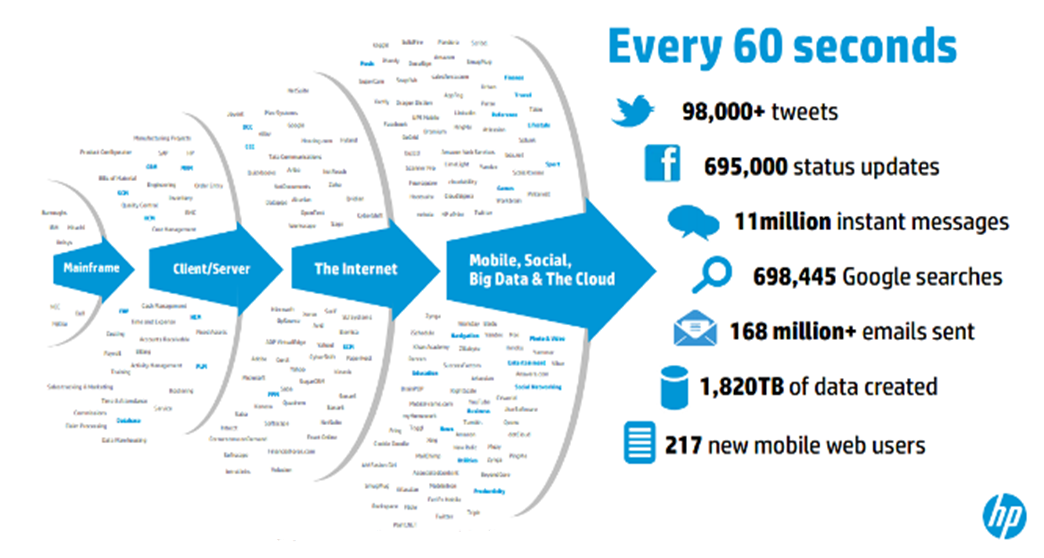
Copyright 2013 Hewlett-Packard Development Company, I.P. The information contained herein is subject to change without notice. You must have realised that how much data we are generating every second, of every minute, of every hour, of every day, of every month, of every year. The phrase that is really popular nowadays and also talks the truth:
- We have generated more than 90% of data in the last two years itself.
- The data is getting generated exponentially day by day with the increasing usage of devices and digitisation across the globe.
- Every 2 days we create as much information as we did from the beginning of time until 2003.
- At a Data Science meetup in 2015, a second statistic that puts the 90% figure in context: the 90% figure has been true over the last 30 years. Every two years we generate 10 times as much data.
- In 2013, an influential report by McKinsey claimed that the area of data science will be the number one catalyst for economic growth.
Below is a list of all the standard units of measurement used for data storage, from the smallest to the largest.
Name Equal to: Size in Bytes Bit 1 bit 1/8 Nibble 4 bits 1/2 (rare) Byte 8 bits 1 Kilobyte 1,024 bytes 1,024 Megabyte 1,024 kilobytes 1,048,576 Gigabyte 1,024 megabyte 1,073,741,824 Terrabyte 1,024 gigabyte 1,099,511,627,776 Petabyte 1,024 terrabytes 1,125,899,906,842,624 Exabyte 1,024 petabytes 1,152,921,504,606,846,976 Zettabyte 1,024 exabytes 1,180,591,620,717,411,303,424 Yottabyte 1,024 zettabytes 1,208,925,819,614,629,174,706,176 The amount of data available on the web in the year 2000 is thought to occupy 8 petabytes (theorised by Roy Williams).
-
Sources of Big Data
- The bulk of big data generated comes from three primary sources:
- Machine-generated Data
- Big Data Generated by People
- Organisation-Generated Data
Machine-generated Data
Machine-generated data can be defined as information which is generated by industrial equipment, sensors that are installed in machinery, and even web logs which track user behaviour. This type of data is expected to grow exponentially as the Internet of Things (IoT) grows ever more pervasive and expands around the world. Sensors such as medical devices, smart meters, road cameras, satellites, games and the rapidly growing.
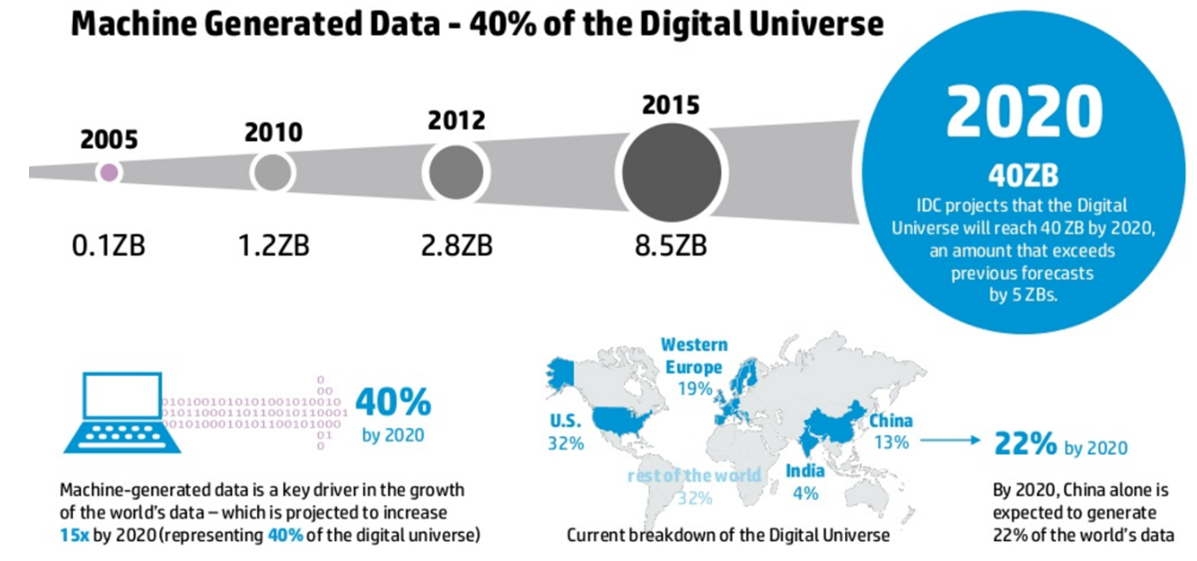
By 2020, the Digital Universe will reach 40ZB. Machine-generated data is a key driver in the growth and it will represent 40% of the Digital Universe.
© Copyright 2014 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.Big Data Generated by People

- People generated massive amounts of data every day through their actives:
- Social media network
- Online photo sharing
- Online video sharing
- Blogging and Commenting
- Email
- etc.
Most of this data is text-heavy and does not conform to a predefined data model, i.e., it is unstructured. Examples of unstructured data generated by people includes texts, images, videos, audio, internet searches, and emails. In addition to it's rapid growth major challenges of unstructured data include multiple data formats, like webpages, images, PDFs, power point, XML, and other formats that were mainly built for human consumption. Think of it, although you can sort your email with date, sender and subject. It would be really difficult to write a program, to categorise all your email messages based on their content and organise them for you. Moreover, confirmation of unstructured data is often time consuming and costly. The costs and time of the process of acquiring, storing, cleaning, retrieving, and processing unstructured data can add up to quite and investment before we can start reaping value from this process.
Organisation-Generated Data
The last type of big data we will discuss is big data generated by organisations. Big data generated by organisations are structured but often siloed.
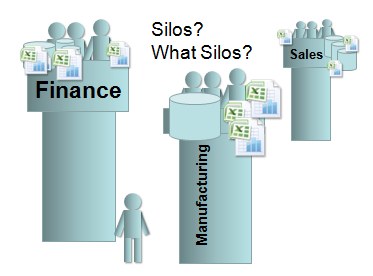
© 2018 nModal Solutions Inc. All Rights Reserved 🔗 http://www.datamartist.com/data-migration-part-5-breaking-down-the-information-silos Many organisations have traditionally captured data at the department level, without proper infrastructure and policy to share and integrate this data. This has hindered the growth of scalable pattern recognition to the benefits of the entire organization. Because no one system has access to all data that the organisation owns.
-
Definitions of Big Data
The first documented use of the term “big data” appeared in a 1997 paper by scientists at NASA, describing the problem they had with visualisation (i.e. computer graphics) which:
“provides an interesting challenge for computer systems: data sets are generally quite large, taxing the capacities of main memory, local disk, and even remote disk. We call this the problem of big data. When data sets do not fit in main memory (in core), or when they do not fit even on local disk, the most common solution is to acquire more resources.”
Later, researchers give definitions for Big Data from very different perspectives, for example:
Big Data Definition Source “Big data is high volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision making, insight discovery and process optimisation” Laney (2001), Manyika et al. (2011) “When the size of the data itself becomes part of the problem and traditional techniques for working with data run out of steam” Loukides (2010) “Big data can mean big volume, big velocity, or big variety” Stonebraker (2012) Big Data is “data whose size forces us to look beyond the tried-and-trusted methods that are prevalent at that time” Jacobs (2009) “Big Data is a term encompassing the use of techniques to capture, process, analyse and visualise potentially large datasets in a reasonable timeframe not accessible to standard IT technologies.” By extension, the platform, tools and software used for this purpose are collectively called “Big Data technologies” INESSI (2012) - There is no single standard definition for Big Data. In the widely-quoted ‘2011 big data study’ by McKinsey, Big Data is defined as data whose:
- scale,
- distribution,
- diversity,
- and/or timeliness
require the use of new technical architectures and analytics to enable insights to unlock new sources of business value.
-
Characteristics of Big Data
- Big data is commonly characterised using a number of Vs. The three main dimensions (3Vs) that characterise big data and describe its challenges are:
- Volume
- Velocity
- Variety
- Some other Vs also been used:
- Veracity
- Valence
- Value
- …
Volume
- Volume refers to the vast amounts of data that is generated continuously in our digitised world. This dimension of big data relates to its size and its exponential growth. A number of challenges rise related to the massive volumes of big data:
- The amount of storage space required to store that data efficiently
- To retrieve that large amount of data fast enough
- To process the data and get results in a timely fashion
Variety
- Variety refers to the ever increasing different forms that data can come in such as text, images, voice, and geospatial data. There are four main axes of data variety:
- Structural variety
Structural variety refers to the difference in the representation of the data. Data could be in different formats and follow different models. For example, a satellite image of wildfires from NASA is very different from tweets sent out by people who are seeing the fire spread. - Media variety
Media variety refers to the medium in which the data gets delivered. The audio of a speech verses the transcript of the speech may represent the same information but in two different media. - Semantic variety
Semantic variety refers to how to interpret and operate on data. We often use different units for quantities we measure. Sometimes we also use qualitative versus quantitative measures. For example, size can be a number or we represent it by terms like small, medium, or large. - Availability variations
For availability, data can be available real time, like sensor data, or it can be stored, like patient records.
Velocity
Velocity refers to the speed at which data is being generated and the increasing speed at which the data needs to be stored and analysed. Processing of data in real-time to match its production rate as it gets generated is a particular goal of big data analytics. For example, personalisation of advertisement on the web pages.
Veracity
Veracity refers to the quality of the data, i.e., biases, noise, and abnormality in data. Big data can be noisy and uncertain. It can be full of biases, abnormalities and it can be imprecise. Data is of no value if it's not accurate. The results of big data analysis are only as good as the data being analysed.
- Data quality can be defined as a function of a couple of different variables:
- Accuracy of the data
- The trustworthiness or reliability of the data source
- Context within analysis
This creates challenges on keeping track of data quality.
-
Getting the Value Out of Big Data
As shown in the Data Pyramid (see below), data is the foundation of information, knowledge and wisdom. The motivation for people to collect and store big volume data is to understand the data, get the value out of the data.
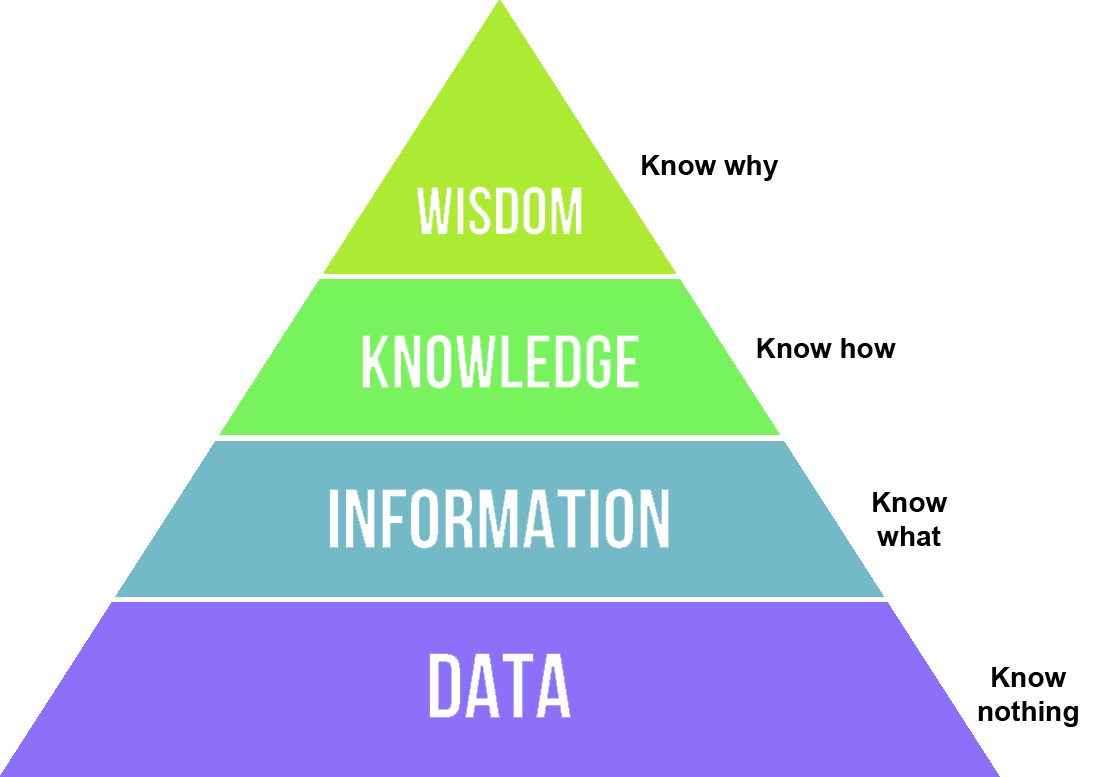
The Data-Information-Knowledge-Wisdom (DIKW) pyramid.
By Longlivetheux [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)], from Wikimedia Commons" https://commons.wikimedia.org/wiki/File:DIKW_Pyramid.svgSkills are needed to help us to understand the data, and can be grouped under some relevant job title:

Five P’s of Data Science
It is said there are five P’s involved in Data Science: People teaming up around application-specific purpose that can be achieved through a process, big data computing platforms, and programmability.
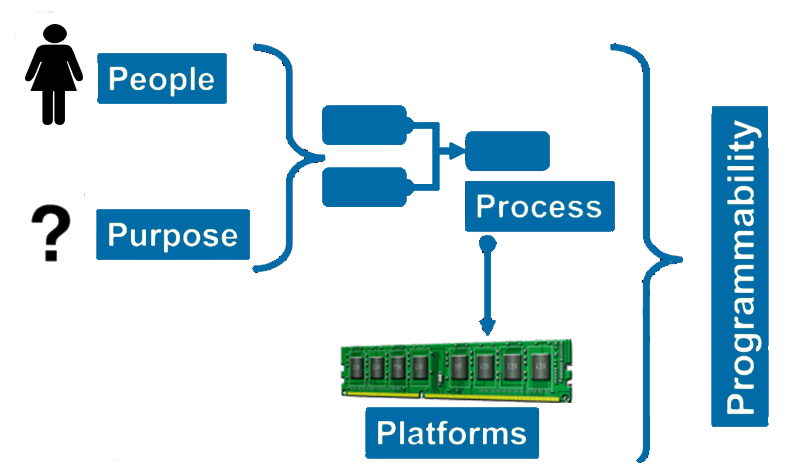
Where, People refers to a data science team or the projects stakeholders. The purpose refers to the challenge or set of challenges defined by your big data strategy, like solving the question related to the rate of spread and direction of the fire perimeter in the wildfire case. Since there's a predefined team with a purpose, a great place for this team to start with is a process they could iterate on. We can simply say, people with purpose will define a process to collaborate and communicate around. The process is conceptual in the beginning and defines the set of steps on how everyone can contribute to it.
The Five P’s defines data science as a multi-disciplinary craft that combines people teaming up around application-specific purpose that can be achieved through a process.
-
Steps in Data Science Process
A simple linear form of data science process

Acquiring data
The first step in acquiring data is to determine what data is available: finding the right data sources.
- Data, comes from, many places, local and remote, in many varieties, structured and un-structured. And, with different velocities. There are many techniques and technologies to access these different types of data.
- For data exists in conventional relational databases, the tool of choice to access data from databases is structured query language or SQL.
- Data can also exist in files such as text files and Excel spreadsheets. Scripting languages (e.g., Java Script, Python, R) are generally used to get data from files.
- An increasingly popular way to get data is from websites. Many websites host web services (e.g. REST) which produce program access to their data.
NoSQL storage systems are increasingly used to manage a variety of data types in big data.
Exploring data
The first step after getting your data is to explore it. Exploring data is a part of the data preparation process.
- Preliminary investigation aims to locate:
- Correlations
- General trends
- Outliers
- And making use of summary statistics, such as,
- Mean
- Median
- Range
- Standard deviation
- Also, various visualization techniques can be applied, e.g,
- Histogram
- Scatter plots
In summary, what you get by exploring your data is a better understanding of the complexity of the data you have to work with.
Pre-process data
- The first aim of data pre-process is to clean the data to address data quality issues, which include:
- Missing values
- Invalid data
- outliers
Domain knowledge is essential to making informed decisions on how to handle incomplete or incorrect data.
- Secondly, data pre-process is needed to transform the raw data to make it suitable for analysis. Common processing methods include:
- Scaling
- Transformation
- Feature selection
- Dimensionality reduction
- Data manipulation
Data preparation is a very important part of the data science process. In fact, this is where you will spend most of your time on any data science effort. It can be a tedious process, but it is a crucial step. Always remember, garbage in, garbage out. If you don't spend the time and effort to create good data for the analysis, you will not get good results no matter how sophisticated the analysis technique you're using is.
Analysing data
- In brief, data analysing builds a model from your data. Different types of analysis techniques are proposed and can be grouped into following types:
- Classification
- Regression
- Clustering
- Association analysis
- Graph analysis
Communication results
Once the data is analysed, the next step is to report the insights gained from our analysis: all our findings must be presented so that informed decisions can be made.
- Visualization is an important tool in presenting your results. Widely used visualization tools are:
- Python
- R
- D3
- Leaflet
- Tableau
Turn insights into action
The last step in the simple linear form of data science process is to determine what action or actions should be taken, based on the insights gained. We may ask questions like:
Is there additional analysis that need to be performed in order to yield even better results?
What data should be revisited?
-
Some concepts
NoSQL (Not Only SQL)
Databases that “move beyond” relational data models (i.e., no tables, limited or no use of SQL)
Data warehouse
constructed by integrating data from multiple heterogeneous sources that support analytical reporting, structured and/or ad hoc queries, and decision-making.
Data Repository
Data Repository Characteristics Spreadsheets and data marts ("Spreadmarts") Spreadsheets and low-volume databases for recordkeeping Analysts depends on data extracts Data Warehouse Centralised data containers in a purpose-built space
Support BI and reporting, but restrict robust analyses.
Analysts dependant on IT and DBAs for data access and schema changes
Analysts must spend significiant time to get aggregated and disaggregated data extracts from multiple sourcesAnalytic sandbox (workspace) Data assets gathered from multiple sources and technologies for analysis
Enable flexible, high-performance analysis in a nonproduction environment; can leverage in-database-processing
reduces costs and risk associated with data replication into "shadow" file systems
"Analyst owned" rather than "DBA owned"Data Lake
A data lake is a large-scale storage repository and processing engine.
A data lake provides "massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs".
Data Mart
Data marts are small slices of the data warehouse.
Whereas data warehouses have an enterprise-wide depth, the information in data marts pertains to a single department.
In some deployments, each department or business unit is considered the owner of its data mart including all the hardware, software and data.
{kind=link}