-
- Objectives
- to explain the purpose and scope of architectural analysis
- to describe different quality attributes that provide a focus for analysis
- to describe some techniques for supporting an analysis.
-
Introduction
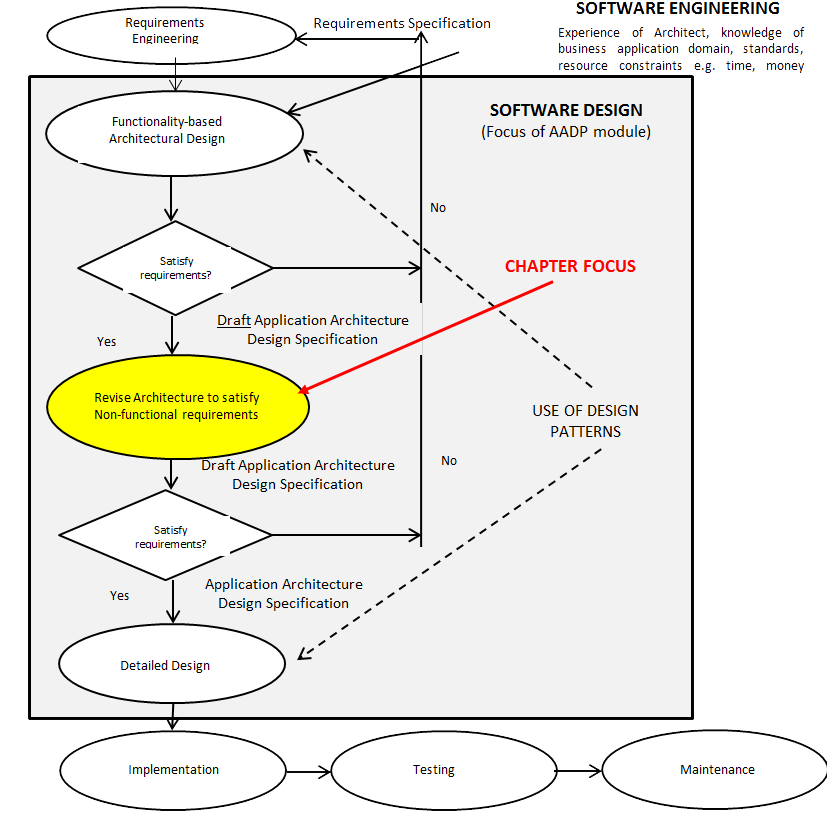
Figure 1: Focus of AADP module within Software Engineering Context Figure 1 shows that software design is reached through an iterative process in which a functionality-based architectural design is revised after architectural analysis to ensure that it satisfies quality attributes. Architectural Analysis should be seen as part of a software project’s quality assurance processes that are concerned with the selection and deployment of appropriate software engineering methods and tools, technical review tasks, testing strategies, change control procedures, and compliance mechanisms against legislative and technical standards. The goal is to assure the sponsor that the product built will be what they want (validation – the “right product”) and satisfy the system requirements (verification – the “product right”). The goals of architectural analysis are principally to check (i) whether the right architectural decisions have been made (ii) whether appropriate an appropriate trade-off has been made between competing needs. This chapter focuses on the practicalities of Architectural Analysis.
- The focus of Architectural Analysis is both on the functionality and the desired levels of various quality attributes. Focusing on both is essential because normally these quality attributes have a significant impact on the architectural and detailed design functionality. For example, specifying a requirement to have all parts of a system available 24-7-365 has a significant impact on
- the architectural design and the detailed design measures needed to be put in place to avoid single points of failure
- the change management measures needed to be put in place to be able to undertake maintenance and provide upgrades without service disruption
- the initial capital cost and ongoing operational costs.
- In the rest of this chapter we will discuss
- the scope of Architectural Analysis
- architectural analysis techniques
- designing for quality
- dependability
- performance
- architectural reviews.
-
Designing for Quality
The foundations of designing dependable and high-performance systems lie in rigorous well-defined software engineering processes, sound project planning, adherence to a small number of good architectural and detailed design principles and the deployment of tried and tested design patterns and coding techniques, followed by rigorous analysis and testing of both functionality and quality attributes. There are a range of overlapping quality attributes e.g. integrity, usability, traceability, interoperability, availability, reliability, security, safety, resilience, complexity, flexibility, maintainability, scalability, trustworthiness, survivability (see 🔗 https://en.wikipedia.org/wiki/List_of_system_quality_attributes). It is difficult to offer a set of specific guidelines for any individual system that is required to be built because both system functionality and the desired balance of quality attributes are unique, and the design and implementation constructs used to address one quality attribute may compromise another. So, there can only be broad guidelines. Appendix 1 sets out some guidelines for different types of quality attributes.
For example, the need for high availability, reliability and resilience will drive architectural design toward using redundancy and diversity. Redundancy means that spare capacity is included in a system that can be used if part of that system fails, e.g. replicating data on back-up database servers. Diversity means that redundant components of the system are made of different types, thus increasing the likelihood that they will not fail in the same way. The need for security will drive architectural design toward a layered architecture with the most critical assets protected in the innermost layers and a high level of security applied to those layers. The need for safety will drive architectural design toward confining safety-related operations to a small number of components, which can be better protected and contain damage limitation in the case of failure. The need for high performance will drive architectural design towards localising critical operations within a small number of larger components with each of these components deployed on the same computer to minimise network connections. However, the larger a component becomes the less likely will be its cohesion and any future changes to that component are likely to have a larger, less transparent, less manageable impact. Amid this complexity, be guided by three key ideas: high cohesion, low coupling and minimise resources utilisation.
The interconnection between components is a good place to focus attention in design (and bug fixing). There are several different techniques that components can use to connect to each other including using parameters, using shared memory, using procedural interfaces i.e. one component encapsulates a set of procedures that can be used by another component, and using message passing interfaces i.e. one component requests a service from another component by passing a message to it, and the return message can include the results of executing the service. Each technique used by two or more principal components should be reviewed to ensure that each component is making the same assumptions and executing the data sharing using the technique correctly.
- Interface errors fall into three categories:
- misuse i.e. a component is called incorrectly
- misunderstanding i.e. the designer has misunderstood what component being called is expecting or what it will provide (so choose names that reflect the role of the element or behaviour of a function, spelling mistakes, using similar but different naming conventions)
- timing i.e. typically in real-time systems when the calling component and called component make unchecked (and hence not fault tolerant) assumptions about when data is going to be provided and received, without considering other software processes or hardware performance that may influence their relationship.
Minimising resource utilisation means minimising usage of and access times to processors, disk memory, RAM, and the network. When it becomes important to discover where performance bottlenecks are, and which events or transactions consume what level of resources, often dynamic analysis can be a useful tool to find out.
-
Scope of Architectural Analysis
In Chapter 2 we made the point that architectural design and hence architectural analysis is an ongoing activity throughout the lifecycle because changes can be made to an architectural design beyond an architectural design stage of a software engineering process. For example, when the architectural design reaches an agreed level of stability the design process moves to detailed design. Detailed design is also iterative to ensure that as the design is elaborated it continues to satisfy the same quality attributes. Unforeseen complexities can arise during detailed design, implementation, testing, and integration with other systems, and during deployment, all of which can cause architectural change. The further downstream in the software engineering process that changes must be made to the upstream architectural design, with all the subsequent redesign and retesting that accompanies that change, the more serious the effect on the project budget and estimated completion date, and hence sponsors’ confidence in the architect and the design team.
More generally and more importantly, all software systems need to be adapted if they are to remain useful. Strategic business objectives, user needs, standards, technology, legislation are just some of the drivers for such change. Anticipating some of these changes and constructing flexibility during design to minimise the disruption of change at some point later in time, is another aspect of architectural analysis. The caveat is that designing, implementing and testing flexibility costs time and money and there is usually a budget for initial capital development and a budget for ongoing maintenance.
📖 Read Ch 9 Software evolution Sommerville, I., Tenth editionChange, whether emergent, as initial architectural design is developed and elaborated, or whether as a reaction to an external change driver, leads competent software development organisations to schedule regular systematic approaches to analyse all or some parts of the architecture and detailed design into their software development and maintenance project plans. In addition, there will be efforts to maintain documentation so that the actual architecture and the code structure and behaviour are consistent. Without this, maintenance is reliant on the memories of those who were involved in the original designs and additional changes, if they are still at the organisation, or a hopeful interpretation of those designs and changes by people who were not originally involved. Both are often flawed, leading to (i) architectural drift, where the current architecture has been developed piecemeal and has functionality that is now ill-fitted to the original architectural design patterns, and the resultant code is no longer meeting some of its desired quality attributes; and then on to (ii) architectural erosion where no-one has a full understanding of what the system does, or how it works or what the full impact of any subsequent change may be.
The focus of this module has been the development of software using design patterns. However, when it comes to evaluating the architectural and detail designs both against desired functional requirements and quality attributes (see section 5), a software architect must be alive to the possibility that potential problems may occur in different parts of the application development stack. Table 1 shows that typically an application under construction fits into a broader enterprise architecture, that it may be constructed using an existing platform architecture and that it may interface with other systems in the enterprise architecture. In addition, the application itself may use a variety of existing (third-party libraries at different stack levels. Over the years many designers and programmers have been caught out making assumptions about, but not checking, the volume, type and periodicity of data they are receiving from, or the data they are supplying to, the systems they are relying on.
Table 1: Application Stack Enterprise Architecture of which the Application is a part Platform or Domain Reference Architecture used by the Application Other systems in the Enterprise that the Application needs to interface with Application Middleware e.g. CORBA, Eclipse Operating Systems Compilers, Network and Hardware Table 2 shows that there are four architectural properties to examine in considering whether architectural goals have been achieved: completeness, consistency, compatibility, correctness. In the next section we will explore some techniques that can be used to understand the extent to which these goals are achieved.
Table 2: Analysis Objectives Completeness Checking for external completeness means establishing whether or not all the functional and quality requirements have been addressed. Checking for internal completeness means establishing whether or not all the system’s archetypes and principal components have been appropriately captured and modelled i.e. whether each component and each component interaction have been fully specified. Consistency Checking for consistency means establishing whether or not different elements of the model contradict each other. Compatibility Checking for compatibility means establishing that the architectural models adhere to any previously defined accepted constraints imposed by external legal and technical standards and to the elements of selected architectural patterns. There may also be a reference architecture with which the architecture of the new system must conform e.g. the architecture for a new frequency convertor product to convert AC to DC may have to conform with the architectural style of platform architectures used to create other frequency convertors in the same product line Correctness Checking for correctness means that as detailed design evolves that the overall design is still correct and satisfying the system requirements that were in the architecture. -
Analysis Techniques
Architectural analysis uses a range of estimation techniques to arrive at a judgement on an architectural design. Clearly, without having built a system yet it is impossible to measure system properties and fully evaluate all the quality requirements. On the other hand, it is not financially or politically tenable to build an entire system and then discover that not only does it not meet the quality requirements but needs a significant re-design to do so. So, a range of different architecture estimation techniques have evolved that draw on different architectural descriptions. The choice of estimation techniques should be fitted to the type of computer-based system being built and be complementary to each other. Each has a value, a cost and a duration which needs to be factored into project planning and budget management.
Peer Reviews (see also Section 6)
One particularly good discipline is to have a step in the project plan to conduct a formal architectural design review, using many stakeholders, to analyse the full architecture. Common stakeholders include software architect, business/product manager, customer, implementation team, testing and evaluation team, maintenance and production team. The meeting should be structured with a clear agenda, chaired and minuted. Types of questions that one might ask in a review are set out in 🔗 https://pubs.opengroup.org/architecture/togaf7-doc/arch/p4/comp/clists/syseng.htm.
- The structure of the review will typically be:
- A summary of the business problem and motivation
- What the project will achieve on completion.
- An overview of the architecture using architectural patterns as shorthand for explanation
- A summary of the critical software attributes
- Any architectural significant requirements
- The hardware and software technology platform
- The reliance on existing internal or external systems.
- However to
However, there are some practical challenges. Undertaking a full analysis and assessment of all aspects of software architecture can be lengthy, costly and difficult to arrange depending on the number of people required, their availability and the quality of necessary remote connections. Secondly, people become tired in meetings that run beyond 2 hours, and usually this is only enough time to get through a limited about of detail for each of these stages. An alternative is to running a single review is to have more reviews each with reduced scope e.g. focus on principal components, focus on the technology platform.
Scenarios
Scenarios are effectively high level tests which can be helpful to walk through as an architecture is being designed. They can also form the basis for integration and system testing when a system is built. A scenario is typical and/or atypical set of events which you think is likely to happen under which it is important to be confident that desired quality attributes will be met. It can be helpful to break down a scenario into component processing steps. For each scenario, a set of key variables is identified, called the workload profile. Typically, the workload profile consists of representative combinations of the variables under that scenario. Then a set of performance objectives is defined for the scenario, in which the precise meaning of each quality requirement has to defined for that scenario. The architectural design team then sets out to review the draft architecture to assess the extent to which the performance objectives can be achieved for the different workload profiles in that scenario.
For example, consider a new financial share transaction management system. One scenario might be when the expected maximum number of users, drawn from the business plan, is using the system simultaneously. Let’s colloquially call this scenario Top of The Range. The variables in the workload profile would be the number of users, the transaction type, and the specific share that is being transacted upon. Let say’s the number of users is 100000, 50% are buying, 50% are selling, and it’s all the same share. A performance objective for this scenario might be that the quality attribute Responsiveness is defined as Each user shall wait no more than 2 seconds for a system response to their transaction request. Other performance objectives might concern resource utilization constraints e.g. peak processor utilization shall be limited to 75 percent and memory consumption shall not exceed 20 GB.
Now when we review the architectural design we can identify several processing steps. It may be that one or more of these steps might involve the use of another analysis technique, and clearly this effects the cost and duration of the review.
Processing Steps
1. An order is submitted by client.
2. The client authentication token is validated.
3. Order input is validated.
4. Business rules validate the order.
5. The order is sent to a database server.
6. The order is processed.
7. A response is sent to the client.We are looking to assess whether all transaction requests are trying to use the same gateway which could lead to a delay or timeout, whether messages back to users are all using the same communication channel which could mean a delay, whether transaction requests are being properly prioritised, whether the share price access control mechanism will guarantee integrity, and whether the available processor and network connection speeds between a remote client and the database will be sufficiently quick.
Another scenario might be colloquially called Denial of Service Attack in which many different simultaneous illegitimate requests are made that cause a request handler to wait indefinitely or wait for prolonged period e.g. when the request handler seeks to authenticate the request sender but the sender’s email address is false.
Table 3 shows a quality attribute modelling process.
Table 3: Quality Modelling Process Step Description Identify key scenarios These can cover all or some part of the system to be built. It can help to name the scenarios like we did above. Choices might include - the expected normal working scenario e.g. buying a product/service online
- frequently executed scenarios
- those that account for a high percentage of system use, or consume significant system resources
- those that can lead to entire system failure
- those that are covered by service level agreements
- those in which there is a reliance on third party systems
- those that run in parallel
Identify processing steps Break down key scenarios into component processing steps. Identify workload profile For each scenario, identify the key variables and which combinations are going to evaluated. Typical variables include the number of users, concurrent active users, data volumes, and transaction volumes. Identify performance objectives Define performance objectives for each scenario. Performance objectives are usually specified in terms of response time, throughput and resource utilisation under different workloads in different scenarios. Allocate budget. Spread your available budget across your processing steps to meet design objectives. Evaluate. Evaluate your design against objectives and budget. Simulation
Building a simulation of the principal components of the draft architecture is useful for understanding the architecturally significant requirements e.g. the performance of data flows under certain conditions, the robustness of the system when faulty data is input, and even the maintenance of the system when structural changes need to be made. Deciding to build a simulation though requires careful thought because it is costly to define the behaviour and interactions of the principal architectural components precisely enough to get value from the simulation, even if it is just only part of the overall system.
Model Checkers
Model-driven engineering is the term used when architect and detailed designer use modelling toolsets that allow high level abstractions to be transformed into lower level abstractions and then into code. Allowing this task to be automated lowers the risk of the design being incorrect.
Prototyping
Prototyping means coding up a skeletal version of some aspects of the draft architecture to explore its feasibility. Like simulation, deciding to build a prototype requires careful thought because it takes time and hence costs money. A prototype is developed (without much documentation) normally to manage risk of failure or manage customer expectations e.g. to understand architecturally significant requirements or to clarify the detail of user-interface requirements. The challenge is how far to develop the prototype bearing in mind the available budgetary and time constraints in the project plan. Prototypes are often thrown away. However, stakeholder expectations about requirements, schedules and costs can all change when good prototypes are presented, and a risk is that the poorly documented prototype becomes the foundation for the actual solution.
In-Line Instrumentation as part of Testing
Static and dynamic analysis tools are used to uncover coding implementation issues such as memory leaks, buffer overflows, concurrency issues, timing analysis and complex runtime behaviour. Static analysis is the examination of source code (or object code after compilation). Dynamic analysis is the examination of a program during run time. Whilst these techniques are principally used during implementation phases of software development, they can also be used in the context of an architectural analysis when developing prototypes to explore a specific aspect of the architecture e.g. complex behaviour, timing analysis.
Static analysis works by scanning one or more source files and creating a representation of the scanned source to analyse it. Dynamic analysis works by either integrating introspective code into an application at build time (the most common approach) or providing a form of platform emulation to understand the internal behaviour of an application during execution. A requirement for any dynamic analysis technique is that it does not interfere with of the system it is monitoring, so desirable features include low overhead, low cost, accuracy, survivability (the ability to continue monitoring despite the failure of parts of the system), and high resolution.
-
Quality Attributes
In Chapter 1 we made the point that in all countries, many aspects of life rely to a greater or lesser extent on complex computer-based systems (CBS), which are designed and situated within some organisational, community or other environmental context to deliver a set of services to a set of users (or another system). Our dependence on CBS is such to the extent that we feel vulnerable, physically, materially and emotionally when they are not available, or they fail, or they do not behave as expected and they put people’s lives or livelihoods at serious risk. Over the last twenty years, improvements in materials technology of computer hardware building blocks i.e. processors, memory, network cabling, combined with advances in computer architecture and network architecture designs have enabled processing power and speed to be transformed. This in turn has significantly changed people’s expectations about response times and performance. So, in this section we focus on two principle quality attributes, dependability and performance.
Dependability
Sidebar – Sustainability The global population’s concern with climate change is increasingly causing systems and software architects to consider a system’s energy consumption. Sustainability concerns design choices that can reduce CPU processing time, memory and disk accesses, network transmissions between clients and servers, back-ups; and considers the impact of placing devices in lower power mode. Sustainability is a tradeoff between the other desired quality attributes. See [6].In 1995 Laprie [1] used the term dependability to cover availability, reliability, security, safety, resilience (Table 4). In principle, you want high dependability for every system. In practice the extent to which you demand more of each quality will also increase the cost and duration of development.
Table 4: Dependability Dependability Availability The ability to deliver services when requested Reliability The ability to deliver services as specified Resilience The ability to resist and recover from damaging events Security The ability to protect itself against deliberate or accidental intrusion Safety The ability to operate without catastrophic failure Designing for Dependability
The avoidance of, reaction to, containment of and the recovery from failure is often what sets outstanding systems apart from others. Figure 2 shows that to achieve a high level of dependability relies on a combination of (i) fault anticipation (ii) fault-avoidance (iii) fault-detection, and (iv) fault tolerance. Fault anticipation is the continuous monitoring of potential external threats to the current effectiveness and efficiency of a system. These may be security related e.g. new viruses but may also be changes to legislation (see sidebar below on GDPR) or technical standards. Fault Avoidance is concerned with putting design constructs in place to counter anticipated faults. Fault Detection is concerned with being able to detect a problem during runtime. Fault Tolerance is the design and execution of different mitigation strategies in response to different types of fault detected.
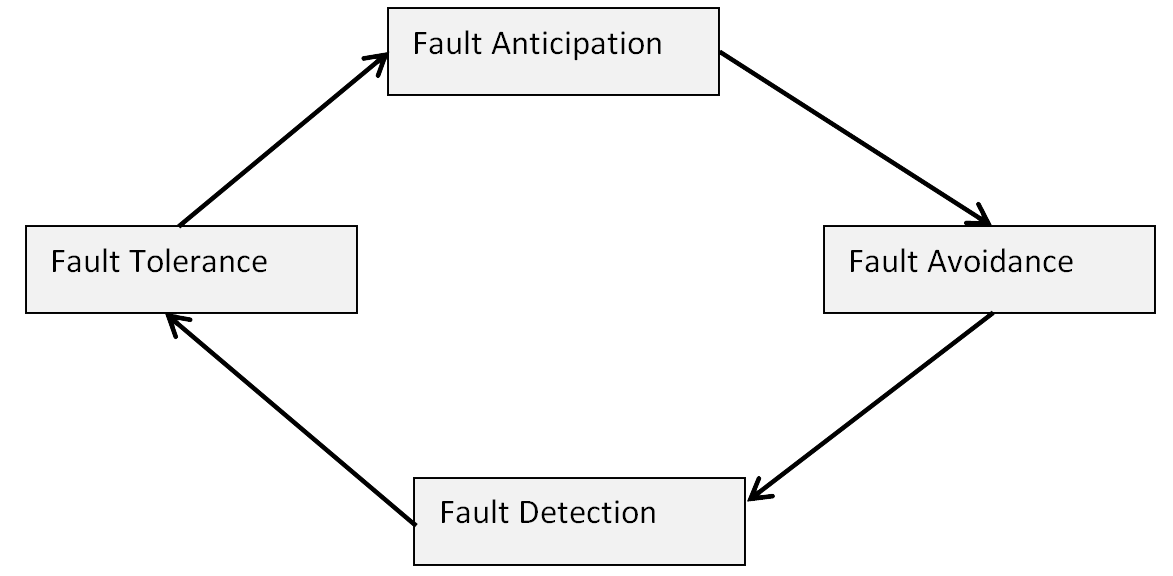
Figure 2: Fault Management The term “failure” normally assumes that the system does not do what it was specified to do. However, be aware that often people also refer to a system feature as a “failure” because it no longer does what they expect it to do, even when it is doing what was specified. Once again this is the difference between the right product and the product right. The challenge for software engineers is that expectations change over time. For example, let’s say an ATM system was first built 20 years ago. Response times of 15-20 seconds to retrieve money might have been acceptable, perhaps because that was all that was feasible. Today, although the functionality has largely remained the same, customer expectations around response times have changed significantly, with response times of anything more than 10 seconds being regarded as “slow”.
- When designing a dependable system, it is important to assume failures will happen and to execute well thought through mitigation strategies when they do. Failures can be:
- hardware failure
- software failures in specification, design, reviewing, implementation, and testing
- operational failures i.e. operators using the system in ways not intended.
- Mitigation strategies tend to fall into three categories:
- full continuation of service by another unaffected route
- continuation of a degraded service but explaining this and when the normal service will be resumed
- discontinuation of service but explaining when the normal service will be resumed.
- A typical relationship between cost and dependability is shown in Figure 3. So, in planning for dependability across the full range of services that a system has to offer, two sensible questions to address are:
- to what extent the highest dependability characteristics are really required?
- Is it sensible or practical to have different dependability requirements for different services within the same system?
There are many different scenarios and each one will require a different consideration and treatment. For example in some scenarios there may not even be a choice of offering service continuity; in others the safety risk of even a degraded service may be too high; and in others managing the dissatisfaction of the customer might actually be better achieved with service discontinuation but a quick recovery back to a full service (e.g. turn everything on/off!) rather than offering a degraded service but slow recovery back to a full service (e.g. wait until the normal downtime period).
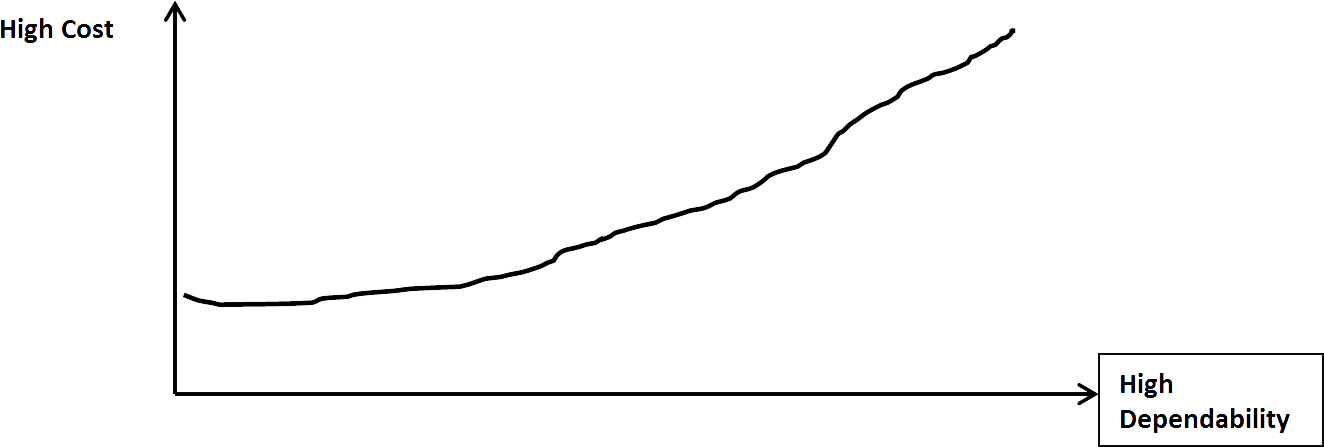
Figure 3: Cost versus Dependability Availability, Reliability and Resilience
Availability, reliability and resilience are different but closely related. They are also affected by the any security measures that are required to be put in place to protect the system. Let us consider an example.
Telecommunications systems use a variety of networked switching components to enable audio and video calls to be made and route calls through the most efficient pathway through the network. Customers expect to make a call at any time or place i.e. high availability. However, the reliability of the call, represented by the quality and latency of the sound and vision, depends on the scope, scale and quality of the network infrastructure and the demand being placed on it at the point individual call is made. When the demand is high, and the network infrastructure is not well developed then different scenarios can unfold. Sometimes the video call and/or the audio call is dropped and then reconnected automatically; sometimes the video call is dropped but the audio call is fine; sometimes there are short delays between acts of speech being made and being received, and sometimes there is echoing on the line. For certain types of call, e.g. personal call that offers audio but not video, people are less demanding about reliability.
Resilience is a judgement about the combined availability and reliability of core services over a sustained period of time when they are disrupted by a variety of different events e.g. there is a hardware failure at one of the network nodes, or secondary power generators producing insufficient power to operate all the network servers are being used because the primary power supply has been affected by the weather, or there is a cyberattack on one or more of the network nodes. In designing resilient systems, the key factor is to identify the critical or core services and focusing design attention on fault detection, fault avoidance and fault tolerance for these services.
The probability of availability and reliability can be calculated. For example, in an ATM system if the withdraw cash transaction is unavailable for selection for say N seconds in a 24-hour period then the probability that the system is always available is 1 – N/86400 (24 hours in 86400 seconds). If you also measure the number of times (M say) a withdraw cash transaction fails in every 100,000 instances of that transaction, then the probability if the system always being reliable is 1- M/100,000.
Security
- Over the last 40 years the widespread availability of computer networks, driven on by the Internet and more recently the Internet of Things has introduced significant challenges for software engineers and enterprise architects. Network structural complexity and the threat of malicious attacks by selfish dishonest people have made networked systems difficult to develop and keep secure. Maintaining a secure information system has three main dimensions concerned with the data being held:
- confidentiality
- Integrity i.e. the data held is correct and has not been corrupted either by a hardware or software failure or by a malicious attack
- availability of data i.e. the system is up and running as normal and not unavailable becau
The terms 'privacy' and 'confidentiality' are often used interchangeably. However, they are not identical concepts. Privacy normally refers to the right to control access to oneself and includes physical privacy. Privacy may also relate to information about oneself, and information privacy laws regulate the handling of personal information through enforceable privacy principles. Confidentiality normally relates to data and information only. For example, medical patients have a right to privacy about their condition which places a legal duty of confidentiality upon the holding of their data about that condition. From an information management system perspective i.e. the design of data structures and data processing, privacy can be thought of what data it is permissible to hold whereas confidentiality is concerned with authenticated controlled access.
Legislation around the world is constantly changing around information management security as we balance our desire to have personalised service provision wherever we are in the world with our desire to retain privacy and hence data confidentiality, all set against different perspectives on privacy and confidentiality enshrined in different nation state laws (see sidebar). Enterprise and software architects need to keep up to speed with these developments.
Collectively they are known as the Enterprise Information Architecture.
- In Chapter 1, Tutorial 1 we saw that the term Enterprise Architecture is used to describe the set comprising the business strategy, the business processes and corresponding IT assets and governance principles that help to execute the business strategy. From a security perspective there are three sets of resources to be managed, each requiring its own security measures:
- Infrastructure (physical buildings, services, equipment)
- Computer network and applications (software applications, databases)
- Operational (behaviour of people).
In larger organisations these responsibilities are distributed to different divisions: Estates Management, IT and Human Resources.
The term “cybersecurity” is commonly used to efforts to protect security of enterprise information architecture. In general cybersecurity is about adhering to a set of general design principles at all three levels e.g. two-layer user authentication, attack monitoring, detection and recovery, access control based on user context, network and host segmentation to shrink attack surfaces, centralisation and encryption of applications, secure file sharing. Many organisations now offer a range of cybersecurity advice, services and tools e.g. 🔗 https://www.cisecurity.org/cybersecurity-best-practices/.
Designing for security inevitably involves some compromises. A very simple example is that the more user authentication layers there are at each service level the longer it takes for a user to do what they want. For example, in stock trading where speed of trade can be important this can be a source of frustration. Then, some users try to find work arounds (e.g. borrowing the passwords of users with higher privileges). Similarly, running anti-virus software can help to protect integrity but may slow down performance.
📖 An excellent source for building secure systems is Security Engineering by Ross Anderson
http://www.cl.cam.ac.uk/~rja14/book.htmlSidebar:
UK Banking: In January 2018 UK Banking laws changed. You now can give permission to certain third party providers (TPPs), authorised by the FCA or other European regulators, to access information and to make payments from current accounts and instant access savings accounts (this doesn’t include cash ISAs, Fixed Term Bonds and Regular eSaver), so long as you can access these accounts through online and mobile banking services. You can instruct a TPP to tell your bank to make a payment on your behalf and they will treat any instruction from a TPP as if it was from you. You cannot stop a payment once you have authorised a TPP to make it. You can also instruct a TPP to obtain and hold data about your account. Once a TPP has your permission and has obtained your data, they will be responsible for the security of this data. See 🔗 https://www.openbanking.org.uk/. GDPR: On 25 May 2018 new data protection laws (known as the General Data protection Regulation - GDPR) come into effect came into force across the European Union (🔗 http://www.eugdpr.org/ and 🔗 https://ico.org.uk/for-organisations/data-protection-reform/overview-of-the-gdpr/ ). Data subject rights are detailed, and include the right to: be informed about use of data, have access to their data – fee for Subject Access Requests removed, rectification of notified errors in data set, including at any third parties using data, erasure of data – right to be forgotten, restrict further processing of data, data portability – for example between Institutions, object to processing pending rectification of errors etc., restrict automated decision making. The definition of personal data will be expanded to include IP address, biometric data, mobile device ID and genetic data, if they can be linked back to an identifiable individual.📖 Read this short blogpost (Oct 2018) on Resilience in BankingSafety
A system can be considered safe if it operates without catastrophic failure i.e. failure that causes or may cause death or injury to people. Software often plays direct (primary) and/or indirect (secondary) roles in monitoring safety. In a direct role it makes safety-related decisions e.g. the navigational software in an aircraft. In an indirect role it might monitor the performance of hardware components looking for early warning failures e.g. brake discs need replacing. The notions of fault-avoidance, fault-detection and fault tolerance are upgraded to be known as hazard analysis, hazard detection and hazard severity assessment, damage limitation and hazard removal. Risk-based assessment is the general approach used in safety critical engineering where risks faced by the system are identified and requirements to mitigate these risks are identified.
In developing safety critical systems there is often an emphasis on specifying “The system shall not…” requirements as there is on the normal functional requirements “The system shall….”. Such “shall not” requirements then must be unpacked into behaviours and constraints placed on functional requirements such as minimum and maximum thresholds, constraining behaviour options, limited component interactions and data sharing, and time-bounded processing.
Many safety-critical systems are regulated i.e. a government organisation not only has a significant influence on their development but also issues a licence governing whether they can be deployed or not, where, when and how. Governments take a keen interest when such systems pose a threat to the general public or the environment or to the national economy. Regulators specify requirements about what such systems can and cannot do. Developers of safety-critical systems must produce a set of documented safety cases that their system is safe. This normally takes the form of a body of evidence that provides a convincing and valid argument that the system or each service being analysed is safe. The evidence will include documented detail of the rigorous processes used to develop the system including all sign offs, and for each safety case a hazard analysis, mitigation strategies and test results, static and dynamic analysis, and records of review meetings.
Often systems must certified by law (e.g. software that runs machines must adhere to the safety levels set out in the EU Machinery Directive 2006 ). Certification is a formal assurance that the system has met relevant technical standards designed to ensure it will not unduly endanger the public and can be depended upon to deliver its intended service safely and securely. Other systems set out to demonstrate that they are free from unreasonable risk as it is defined in one of the best practice standards (IEC61508, 2010 ). Some of these standards are harmonized with the directives and regulations, meaning that if you comply with a standard you automatically comply with a regulation.
-
Performance
Performance is concerned with achieving response times, throughput, and resource utilization levels that meet performance objectives. Table 5 shows a definition for each of these parameters. Scalability refers to the ability to handle additional workload e.g. more users or more sensor providing more data, without adversely affecting performance.
Table 5: Performance Parameters Performance Parameters Description Response Time Response time is the time it takes to respond to a request. It may be the time required for a single transaction, or the end-to-end time for a user task. For example, we may require that an online system provide a result within one-half second after the user presses the "enter" key. In a networked client-server system, client latency is the time that it takes for a request to reach a server and for the response to travel back, and server latency is the time the server takes to complete the execution of a request. Server latency does not include network latency. Network latency is the additional time that it takes for a request and a response to cross a network. Throughput Throughput is the number of requests that can be served by your application per unit time. For example, a telephony switch may be required to process 100,000 calls per hour. Resource Utilisation Resource utilization is the cost in terms of system resources. The primary resources are CPU, memory, disk I/O, and network I/O. - Software performance engineering is a systematic, quantitative approach to constructing software systems that meet performance objectives. It focuses on balancing the trade-offs between performance and other quality of service (QoS) attributes (e.g., security, reliability or availability). The consequences of perceived performance failure include
- damaged reputation
- Lost business i.e. neither repeat business nor new business are secured
- additional project costs to retune or redesign
- project failure when it is not possible to demonstrate the system will meet performance objectives.
Performance models can help predict performance during the architectural and early design phases of the project. Managing performance from the beginning of the software development process can reduce the overall project time by eliminating the need for time-consuming redesign and tuning. However, the level of effort devoted to performance management depends on the level of risk. If there is little or no risk of a performance failure, then there is no need for an elaborate performance management program. If the risk of performance failure is high, then a higher level of effort is needed. Simple models can provide the information required to identify performance problems and evaluate alternatives for correcting them. Such models are often inexpensive to construct and evaluate. If necessary and as more details of the software are known, you can construct and solve more realistic and complex models.
Designing for Performance Improvement
Designing for performance improvement is to minimise resource utilisation i.e. processor, disk i/o, memory i/o, network i/o. Table 6 shows some design principles for improving performance that have been abstracted from architectures that have scaled and performed well over time. The message for Software Architects is to continue to develop their knowledge of how the hardware resources of a computer architecture are being utilised when a system is running, as well as find someone on the team who has expertise in this area.
Table 6: Principles for Designing for Performance Improvement Principle Description Design coarse-grained services Coarse-grained services minimize the number of client-service interactions and help you design cohesive units of work. If you already have fine-grained services, consider wrapping them with a facade layer to help achieve the benefits of a coarse-grained service. Minimise round trips across resources. Minimise round trips across resources a network or a set of processors by batching work. Acquire late and release early. Minimise the duration that you hold shared and limited resources such as network and database connections. Evaluate affinity between software and hardware resources. When some software resources are only available from certain hardware resources e.g. servers or processors, there is an affinity between the software resource and hardware resource. Affinity can improve performance but can impact scalability. Put the processing closer to the resources it needs. Pool shared resources. Reduce contention Blocking software access to hardware resources can be caused by unintentional long-running tasks such as expensive i/o operations or perhaps at “hotspots” of concentrated access to certain data that everyone needs. Blocking causes requests to be queued. Techniques for reducing contention include the efficient use of shared threads and minimizing the amount of time your code retains locks. For example, when only a portion of a composite data structure data needs to change, process the changed portion and not all the data. Also consider rendering output progressively. Do not block on the entire result set when you can give the user an initial portion and some interactivity earlier. Similarly, when you need to process multiple independent tasks, look to perform them concurrently. 📖 Look at the role of a DBA https://www.prospects.ac.uk/job-profiles/database-administratorAnother aspect of performance analysis is concerned with the infrastructure the application is to be deployed on. Frequently, the target environment has existing constraints within which the deployment design must fit. It must also consider and trade off against other QoS attributes e.g. security.
Normally there are a range of possible deployment models, each having its strengths and weaknesses. For example, Figure 4 shows a non-distributed architecture, in which a set of conceptual presentation, business and data layers are separated but are physically located in a single Web server process on a Web server. Table 7 shows some strengths and weaknesses.

Figure 4: Non-distributed application architecture: logical layers on a single physical tier Table 7: Strengths and Weaknesses of Non-distributed Architecture Strengths Weaknesses Straightforward to understand Difficult to share business logic with other applications Performance advantage from local calls Server resources are shared across layers. This can be good or bad — layers may work well together and result in optimized usage because one of them is always busy. However, if one layer requires disproportionately more resources, you starve resources from another layer. Figure 5 shows an alternative deployment model, a distributed architecture, in which the presentation logic communicates remotely to the business logic located on a middle-tier application server. Table 8 shows some strengths and weaknesses.
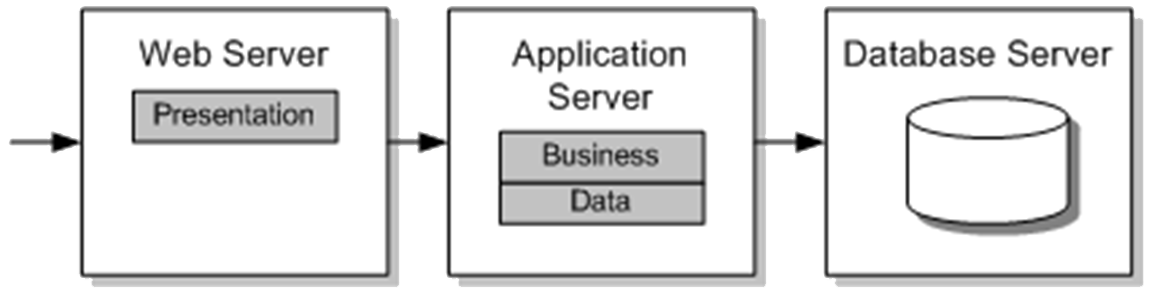
Figure 5: Distributed architecture: logical layers on multiple physical tiers Strengths Weaknesses Can scale out and load balance business logic independently Additional serialization and network latency overheads due to remote calls Has separate server resources that are available for separate layers Potentially more complex and more expensive in terms of total cost of ownership Flexible You often achieve optimum performance by locating your business logic on the Web server in your Web application process. If you avoid or exploit server affinity in your application design, this approach supports scaling up and scaling out.
- However, you might need to physically separate your business layer, as in the following scenarios:
- You might want to co-locate business gateway servers with key partners.
- You might need to add a Web front end to an existing set of business logic.
- You might want to share your business logic among multiple client applications.
- The security policy of your organisation might prohibit you from installing business logic on your front-end Web servers.
- You might want to offload the processing to a separate server because your business logic might be computationally intensive./dd>
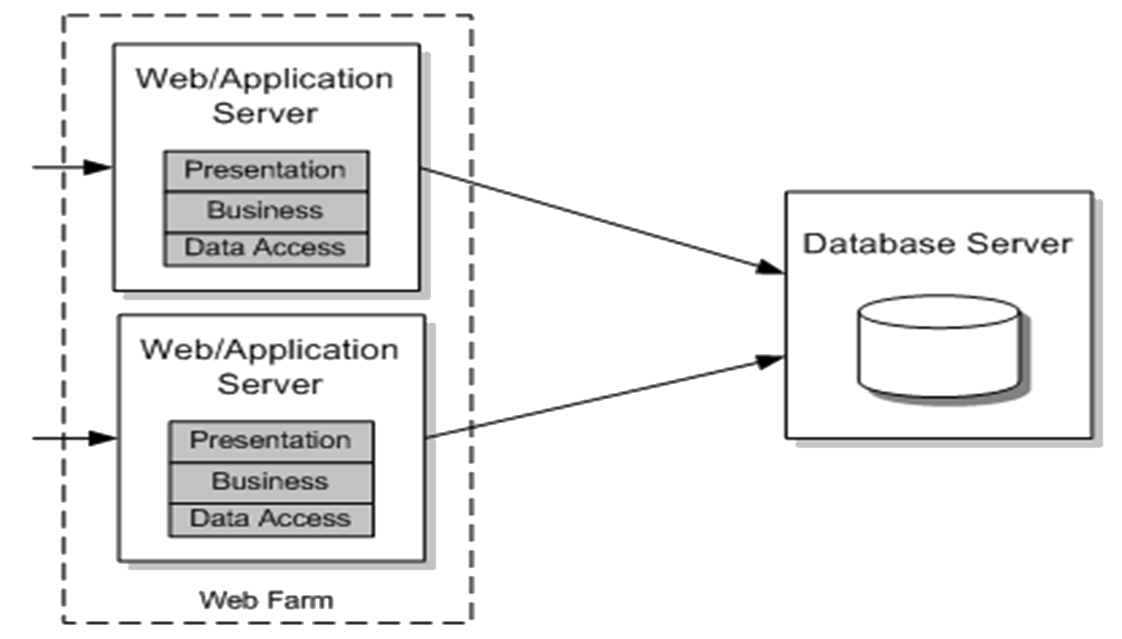
Figure 6: Distributed Architecture with Web Farm 1http://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A32006L0042
2http://www.iec.ch/functionalsafety/standards/page2.htm Functional safety of electrical/electronic/programmable electronic safety-related systems - Part 1: General requirements -
Scalability
Your approach to scaling is a critical design consideration because whether you plan to scale out your solution through a Web Farm (📷 Figure 6), a load-balanced middle tier, or a partitioned database, you need to ensure that your design supports this. There are two principal choices: (i) scale up i.e. increase the capability of the existing hardware (“get bigger boxes”) (ii) scale out i.e. increase the capacity of the hardware (“get more boxes”).
Scale Up: In this approach, add hardware such as processors, RAM, and network interface cards to the existing servers to support increased capacity. This is a simple option and one that can be cost effective. It does not introduce additional maintenance and support costs. However, any single points of failure remain, which is a risk. Beyond a certain threshold, adding more hardware to the existing servers may not produce the desired results. For an application to scale up effectively, the underlying framework, runtime, and computer architecture must scale up as well. When scaling up, consider which resources the application is bound by. If it is memory-bound or network-bound, adding CPU resources will not help.
Sidebar: Load Balancing: Load balancing means is dividing the amount of processing that is required between two or more computers so that it is more effective (i.e. the processing gets completed but is also more resilient to a hardware or software failure in a replica) and more efficient (quicker). A load balancer receives requests and distributes them to two or more machines. However, the more replicas the greater the overall communication processing time in the system, the grater the complexity of the system and the greater the cost.Scale out: To scale out, add more servers and use load balancing (see Sidebar) and clustering solutions. In addition to handling additional load, this scenario also protects against hardware failures. If one server fails, there are additional servers in the cluster that can take over the load. For example, you might host multiple Web servers in a Web farm that hosts presentation and business layers, or you might physically partition your application's business logic and use a separately load-balanced middle tier along with a load-balanced front tier hosting the presentation layer. If the application is i/o-constrained and there is a need to support an extremely large database, partition the database across multiple database servers. In general, the ability of an application to scale out depends more on its architecture than on underlying infrastructure. To ensure that your application can be scaled out successfully, ensure that there is the ability to scale out bottlenecks. If the bottlenecks are on a shared resource that cannot be scaled, this is a real problem which is likely to require reshaping the architectural design.
You should look at scale-up options first and conduct performance tests to see whether scaling up your solution meets your defined scalability criteria and supports the necessary number of concurrent users at an acceptable level of performance. You should have a scaling plan for your system that tracks its observed growth. If scaling up your solution does not provide adequate scalability because you reach CPU, disk/memory/network i/o thresholds, you must scale out and introduce additional servers.
If the application uses a very large database and an I/O bottleneck is anticipated, design for database partitioning up front. Moving to a partitioned database later usually results in a significant amount of costly rework and often a complete database redesign. Partitioning enables the ability to restrict queries to a single partition , thereby limiting the resource usage to only a fraction of the data, and the ability to engage multiple partitions, thereby getting more parallelism and superior performance because you can have more disks working to retrieve your data. Be aware that in some situations, multiple partitions may not be appropriate and could have a negative impact. For example, some operations that use multiple disks could be performed more efficiently with concentrated data. So, when you partition, consider the benefits together with alternate approaches.
X
Figure 6: Distributed Architecture with Web Farm -
Architectural Reviews
An architectural review is a structured meeting to analyse a draft architectural design and the set of assumptions and accompanying decisions that have been made to form that design. This type of peer review is a common method of evaluating different outputs of the software engineering process. Whilst peer review is subjective, often experienced architects and designers can recognise patterns and decisions that may cause difficulties downstream whether that is in detailed design or implementation. They draw upon the experience of building similar systems.
The aims of the review are to reach a formal agreement that the architectural design provides a firm basis upon which to carry out a detailed design and to build the product; and to ensure that the expectations of the sponsors are managed and met about the outputs of the review. Often there can be a tension between these two aims because of the different stakeholder interests. It is the project manager’s role to resolve these tensions. However, managing expectations within a project plan is also an essential capability within the role of a software architect (see Chapter 6).
First, agreeing at what point into the project an architectural review should be conducted will depend on an agreement on where the boundary lies between what is architectural design and what is detailed design. This is a judgement, made by the project manager and software architect, in consultation with the other designers, and after considering different scoping options. A scoping option here means an outline of what will be in the architectural design and how long it will take to complete. Discussing architectural design scoping options with the project manager is essential because their perspective will be to choose a scoping option that balances giving sponsors a design as early as possible but is of sufficient breadth and depth to show that good progress is being made and is technically good to give confidence to sponsors that the design team is capable.
Second, despite the project plan, sometimes sponsors and hence project managers can become anxious to see architectural designs as quickly as possible. This may be because of commercial pressures such as being first-to-market just to stay afloat, or political pressures e.g. a national or local government (the project sponsor) under pressure from political representative (MPs or Counsellors) wanting to see progress being made when millions are being spent on a large IT infrastructure project. Architects and designers on the other hand are often keen to resist formal review until they are confident that the architectural design has reached a level of stability in providing all the elements of the scoping option agreed in the project plan and has a clean design.
Third, the outcome of an architectural review will often be a trigger for a review of the project plan. If an architectural design meets or exceeds expectations, sponsors and project managers will immediately start to enquire with the architect whether this will mean that the project completion date can be bought forward or whether it will cost less than anticipated. Architects will be resistant to this, borne out of experience that there are usually unforeseen problems downstream and cutting the budget or the duration time at this point will give them less flexibility to resolve such problems if they occur. If an architectural design does not meet expectations, this will affect the confidence and anxiety of the sponsor and then in turn the project manager whose managerial behaviour may alter.
- Architectural reviews consume time and money in so far as they require many different people to attend one or more meetings to complete the review and they require even longer preparation time by all stakeholders (writing and reading papers) to make sure the meetings are effective. However, the benefits are significant and can include:
- a shared understanding of the architectural design and the assumptions and decisions affecting it
- a collegiate formal documented signed off agreement on what the design is at that point in time
- a confidence and strengthening of the reputation of the design team and their work to date
- a confidence to all parties to proceed to detailed design
- the receipt of a staged payment where this is built into the contract.
Although on most projects one might expect to conduct just one significant architectural review, if any architecturally significant requirements are modified or new ones introduced after the review then another architectural review should be scheduled. However, the availability of resources needed to do this often governs whether this happens or not. In addition, even if the resources are available it may be politically expedient to find an alternative name for the activity to convey that it is of smaller scale e.g. “architectural viewpoint assessment”, especially if a stage payment has already been made or Parliament has been told that the architectural review has been completed!
A Review Method
The Architectural TradeOff Analysis Method (ATAM) [2,3] is a method for detecting potential risks of a complex software intensive system. It should be conducted ideally by an architecture evaluation team who are independent from the development team. It is important to prioritise what the focus of the review is, largely because getting all the relevant stakeholders together is often very difficult and concentration levels tend to dip after 2-3 hours. The ATAM method has several different steps:
i. Review and sense-check the business goals, requirements, technical, economic or political constraints, application context and the key quality attributes that have shaped the architecture.
ii. Use one or more diagrams e.g. context diagrams, architectural patterns, use cases etc., to discuss that part of the architecture that is under scrutiny for the purposes of understanding if the functional requirements have been addressed- iii. Collect some scenarios (see Scenarios) that will drive the review of the architecturally significant functional requirements and the quality attributes. Different scenario categories include:
- Use-case scenarios describing how the users envisage the system being used
- Use-case scenarios describing how the users envisage the system being used
- Threat scenarios which describe anticipated security attacks
- Performance under load scenarios
iv. For each scenario evaluate the impact on different architectural options and variation sensitivity
v. Critique architectural options against the most likely combination of scenarios.
vi. Reach a decision on next steps.📹 Watch this experienced Australian Software Architect discuss software architecture reviews (57m)
3This is another example of the design principle “separation of concerns”.
4In practice a review meeting can also be a vehicle to consider different alternatives
5An organisation that does not conduct structured architectural reviews is more likely to struggle to build well designed products on time and within budget -
Summary
This chapter describes the value of software architectural analysis and when to undertake it. It recognises the complexity of architectural analysis but describes processes and techniques to manage that complexity. In practice organisational approaches to architectural analysis vary considerably. The quality and frequency of such analyses is often indicative of the budget available, the organisation’s understanding of the value of software architecture, and its cultural attitude toward software development rigour, rather than being a function of the complexity and scale of the system being built.
-
References
1. Laprie, J-C., (1995) Dependable computing: concepts, limits, challenges, Proceedings of the 25th Int’l Conference on Fault-Tolerant Computing, Pasadena, California, Jun 27-30, pp42-54 SBN:0-8186-7146-7
2. Bass, L., Clements, P., Kazman, R., (2013) Software Architecture in Practice, Addison-Wesley, ISBN 9780321815736
3. Kazman et al. (2000) ATAM: Method for Architecture Evaluation, Technical report CMU/SEI-2000-TR-004
4. Taylor, R., Medvidovic, N., Dashofy E.M (2010) Software Architecture: Foundations, Theory, and Practice, Wiley, ISBN 9780470167748
5. Kazman, R., Haziyev, S., Yakuba, A., Tamburri, D., Managing Energy Consumption as an Architectural Quality Attribute, IEEE Software, Sept/Oct 2018, pp102-107.
-
Appendix 1: Design Guidelines from Chapter 12 [4] Efficiency Keep Components Small Keep Component Interfaces Simple and Compact Separate Processing from Data Separate Data from Meta-Data Carefully Select Connectors Use Broadcast Connectors with Caution Make Use of Asynchronous Interaction whenever possible Use Location Transparency Judiciously Keep Frequently Interacting Components Close Carefully Place Connectors in the Architecture Consider the Efficiency Impact of Selected Architectural Styles and Patterns Complexity Separate Concerns into Different Components Keep Only Functionality Inside Components – Not Interaction Keep Components Cohesive Be Aware of the Impact of Off-the-Shelf Components on Complexity Insulate Processing Components from Changes in Data Format Treat Connectors Explicitly Keep Only Interaction Facilities Inside Components Separate Interaction Concerns into Different Connectors Restrict Interactions Facilitated by Each Connector Eliminate Unnecessary Dependencies Manage All Dependencies Explicitly Use Hierarchical (De) Composition Scalability Give Each Component a Single Clearly Defined Purpose Give each Component a Simple Understandable Interface Do Not Burden Components with Interaction Responsibilities Avoid Unnecessary Heterogeneity Distribute the Data Sources Replicate Data When Necessary Use Explicit Connectors Give Each Connector a Clearly Defined Responsibility Choose the Simplest Connector for the Task Be Aware of Differences Between Direct and Indirect Dependencies Be Aware of Differences Between Direct and Indirect Dependencies Leverage Explicit Connectors to Support Data Scalability Avoid System Bottlenecks Make Use of Parallel Processing Capabilities Place the Data Sources Close to the Data Consumers Try to Make Distribution Transparent Use Appropriate Architectural Styles Adaptability Give Each Component a Clearly Defined Purpose Minimise Component Interdependencies Avoid Burdening Components with Interaction Responsibilities Separate Processing from Data Separate Data from Metadata Give Each Connector a Clearly Defined Responsibility Make the Connectors Flexible Support Connector Composability Be Aware of Differences Between Direct and Indirect Dependencies Leverage Explicit Connectors Try to Make Distribution Transparent Use Appropriate Architectural Styles Dependability Carefully Control External Component Interdependencies Provide Reflection Capabilities in Components Provide Suitable Exception Handling Mechanisms Specify the Components’ State Invariants Employ Connectors that Strictly Control Component Dependencies Provide Appropriate Component Interaction Guarantees Support Dependability Techniques via Advanced Connectors Avoid Single Points of Failure Provide Backups of Critical Functionality Support Non-intrusive System Health Monitoring Support Dynamic Adaptation Security Give Just Sufficient Access Privileges to a Requester to Complete the Task Deny Access to an Object unless the Requester has permission Keep Security Mechanisms as Simple Check the Access Privileges of All Requestors The Security of a Mechanism