-
Big Data workloads
Big data workload can be grouped into two different types: Operational Workloads (also referred to as real-time, interactive workloads) and Analytical Workloads (also referred to as offline workload). Different type of workloads presents different challenges and need different classes of technology to support, although both types of the workloads tend to operate over many servers operating in a cluster, managing tens or hundreds of terabytes of data across billions of records.
Operational workloads
Operational workloads usually imply Online Transaction Processing (OLTP), where data is created, ingested, transformed, managed and/or analysed in real-time to support operational applications and their users. Latency for these applications must be very low and availability must be high.
Operational workloads typically touch specific parts of a data set in predictable ways, and normally include large number of short, discrete, atomic transactions. This type of workloads emphasis on high throughput (transactions per second), concurrency, and maintaining data integrity in multi-user environments.
- Example operational workloads include:
- serving content and product catalogues from a web site
- real-time analytics of sensor data
- personalising user experiences in e-Commerce applications
Analytical workloads
Analytical workloads usually imply applications that ingest, transform, manage and/or analyse data in a batch or interactive processing. This type of workloads involves retrospective, complex analysis that may touch most or all of the data, may use data from many parts of a data set and work in ad-hoc manner, and typically do not create new data.
Comparing to operational applications, analytical applications normally have fewer users submitting fewer requests, but those queries can be very complex and resource intensive. Response time of analytical application is frequently measured in tens to hundreds of seconds.
- Example analytical workloads include:
- Modelling
- Forecasting
- Decision Support
- Forensics
- ad hoc analysis
Operational vs. Analytical
Main features of operational and analytical workloads are listed comparatively in the table below:
Operational Analytical Latency 1 ms - 100 ms 1 min - 100 min Concurrency 1000 - 100,000 1 - 10 Access Pattern Writes and Reads Reads Queries Selective Unselective Data Scope Operational Retrospective End User Customer Data Scientist Technology NoSQL MapReduce,
MPP Database -
NoSQL Big Data System
NoSQL Big Data systems have emerged to address a broad set of operational Big Data workloads. NoSQL Big Data systems are designed to take advantage of new cloud computing architectures to allow massive computations to be run inexpensively and efficiently. This makes operational Big Data workloads much easier to manage, and cheaper and faster to implement.
NoSQL technologies, which were developed to address the shortcomings of relational databases in the modern computing environment, are faster and scale much more quickly and inexpensively than relational databases.
In addition to user interactions with data, most operational systems need to provide some degree of real-time intelligence about the active data in the system. Some NoSQL systems can provide insights into patterns and trends based on real-time data with minimal coding and without the need for data scientists and additional infrastructure.
-
Data scaling
With the exponential increases in the volume of data being produced and processed, many company’s databases are being overwhelmed with the deluge of data they are facing. Data scaling is necessary to accommodate performance issues arisen in the growth of data, either in traffic or volume.
- There are three common performance bottlenecks which could be properly resolved with data scaling:
- High CPU Usage
Slowing and erratic performance is a key indicator of high CPU usage, and can often be a harbinger of other issues. - Low Memory
Systems without enough memory to handle an application load can slow the application completely. - High Disk Usage
This is often caused by maxed out disks, and is a huge indicator of the need for a data scale.
Scaling up or Scaling out
- In order to address the need for more processor capacity, memory and other resources, there are two commonly used types of data scaling: scaling up and scaling out.
- Scaling up
Also known as vertical scaling. This type of scaling use more powerful processors, more memory, but does not significantly change architecture. For example, when a project’s demands start to reach the limits of an individual server, a scaling up approach would be to buy more capable server with more processing capacity and memory.
Scaling up approach may only provide a short-term fix, especially if continued growth is expected. - Scaling out
Also known as horizontal scaling. This scaling approach adds lots of lower-performance machines in a cluster for parallel computing. This approach provides a long-term solution, as more and more machines may be added when needed. It is an extremely effective solution, but going from one monolithic system to this type of cluster may be a difficult.
Scaling up architectures are rarely used in the big data processing field and scaling out architectures are the de facto standard. While, if your problem space involves data workloads with strong internal cross-references and a need for transactional integrity, big iron scaling up relational databases are still likely to be a great option.
Sharding
Sharding is a technique to distribute large amounts of data across a number of nodes in a cluster. It is a common way to implement horizontal scaling (i.e., scaling out).
Sharding distributes different data on distinct nodes and tries to keep data that belongs together on same node in a cluster, each of those nodes does its own reads and writes.
- Sharding may be required for any number of reasons:
- The total amount of data is too large to fit within the constraints of a single database
- The transaction throughput of the overall workload exceeds the capabilities of a single database
- Customers may require physical isolation from each other, so separate databases are needed for each customer.
- Different sections of a database may need to reside in different geographies for compliance, performance, or geopolitical reasons.
Scaling and relational databases
Traditional cluster-aware RDBMS (relational database management system) use a shared disk subsystem. In this kind of system, although data is distributed and highly available, there is a single point of failure. Concept of sharding does not sit well with relational databases. All the sharding has to be controlled by the application which has to keep track of which database server to talk to for each bit of data.
Relational databases provide solid, mature services according to the ACID (Atomocity, Consistency, Isolation, Durability) properties. When data are scaling out, ACID turns out to be difficult to satisfy, and so lose many of the benefits of the relational model.
Features of relational databases
- Relational databases are designed for fast storage and retrieval of structured data. Here are some features of relational databases.
- Persistence
Relational databases store large amounts of data in a way that allows an application program to get at small bits of that information quickly and easily - Concurrency
Relational databases allow many concurrent accesses, controlled using transactions. - Referential integrity
Relational databases use primary and foreign keys to maintain relationships between tables and ensure data is consistent. - Integration
Traditional enterprise approach to integration of different applications within the organisation is to use shared database with concurrency control. - Standard model
Relational databases provide these capabilities using a (mostly) standard data model and SQL
Limitations of RDBMS
- RDBMS has many advantages but amongst the disadvantageous are:
- They have a fixed scheme. For unstructured data, it may have its own internal structure, but does not conform neatly into a spreadsheet or relational database.
- It becomes a real challenge for RDBMS to provide the cost effective and fast CRUD (Create, Read, Update and Delete) operation as it has to deal with the overhead of joins and maintaining relationships amongst various data.
Origins of “NoSQL”
The name “NoSQL” was in fact first used by Carlo Strozzi in 1998 as the name of file-based database he was developing. Ironically it’s relational database just one without a SQL interface. The term re-surfaced in 2009 when Eric Evans used it to name the current surge in non-relational databases.
NoSQL stands for “Not Only SQL”.
NoSQL databases do not use SQL as their primary query language. They provide access by means of Application Programming Interfaces (APIs).
Many different NoSQL database systems exist or have existed. More than 225 NoSQL databases are currently listed on 🔗 http://nosql-database.org/.
-
Data Modelling
- Data modelling is the process of creating a data model for the data to be stored in a Database. There are three major components of a data model: structures, operations and constraints. A data model is characterized by the structure of the data that it admits, the operations on that structure, and a way to specify constraints.
- Data Model Structures
The structure of data includes three types: structured, semi-structured and unstructured.
Structured data can be stored in relational databases in tables with rows and columns. They have relational key and can be easily mapped into pre-designed fields. Structured data are the most processed in development and the simplest way to manage information. But structured data represent only 5 to 10% of all informatics data. The figure below presents an example of structured data.
Semi-structured data is information that doesn’t reside in a relational database but that does have some organizational properties that make it easier to analyse. With some process you can store them in relation database (while, it could be very hard for some kind of semi structured data). NoSQL databases are considered as semi structured. An example of semi-structured document is given in the figure below.
Unstructured data represent around 80% of data. It often includes text and multimedia content. Examples include word processing documents, videos, photos, audio files, presentations, webpages and many other kinds of business documents. Note that while these sorts of files may have an internal structure, they are still considered “unstructured” because the data they contain doesn’t fit neatly in a database. - Data Model Operations
Operations in a data model specify the methods to manipulate the data. Different data models are typically associated with different structures, and the operations on them will be different.
Some types of operations are usually performed across all data models:
Selection - extract a part of a collection based on the condition
Projection - retrieving a part of a structure that is specified
Union - combining two collections into a larger one
Join - combining collections have different data content but have some common elements - Data Model Constraints
Data Model Constraints are used to verify that the data conforms to a basic level of data consistency and correctness, preventing the introduction of dirty data.
Data Model constraints can specify the meaning of the data, e.g., data type, value, and structural constraints.
Relational Data Model
Relational Data Model is one of the simplest and most frequently used data models. The primary data structure for a relational model is a table, which is also called a relation. A table actually represents a set of tuples (rows). A relational tuple implies that unless otherwise stated, the elements of it are atomic: represent one unit of information and cannot be decomposed further.
The schema in a relational table can also specify constraints.
-
Types of NoSQL database
A lot of NoSQL databases have existed. There are significant variety among NoSQL databases, particularly in terms of the data model used.
- NoSQL databases can be grouped into four main types. Each with its own data model, although boundaries among them are blurred:
- Key/value database
- Document database
- Wide column stores database
- Graph database
Key-value Database
A key-value Database is a data storage paradigm designed for storing, retrieving, and managing associative arrays, which is a data structure more commonly known today as a dictionary or hash. It manages a simple value or row, indexed by a key. Key-value Databases are the simplest and most flexible type of NoSQL database. There is no schema and the value of the data is opaque.
The client can either get the value for the key, put a value for a key, or delete a key from the data store.
The value is a blob (binary large object) that the data store just stores, without caring or knowing what’s inside. It is the responsibility of the application to understand what was stored.
Key-value Database generally have good performance and can be easily scaled. Examples of key-value Database include DynamoDB, Voldemort, Riak, Redis, Azure Table Storage.
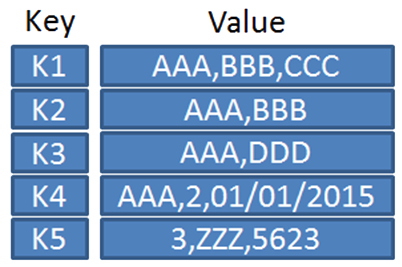
Illustration of the key-value concept Key-value Databases are suitable to store session information, user profiles and preferences, and shopping cart data etc. While generally it is not a good choice to save data with relationships, transactions with multiple operations, querying based on content of data, or operations on sets of data in a Key-value Database.
Document-oriented Database
A document-oriented database is a specific kind of database that works on the principle of dealing with 'documents’ rather than strictly defined tables of information. Documents are self-describing, hierarchical tree data structures which can consist of lists/arrays (sequential collections of values), maps (key/value collections), and scalar values. Documents stored are generally similar to each other but do not have to be exactly the same (i.e., schema-less data). In general, document-oriented databases all assume documents encapsulate and encode data in some standard format or encoding. Encodings in use include XML, YAML, JSON, and BSON, as well as binary forms like PDF and Microsoft Office documents (MS Word, Excel, and so on).
{ _id: ObjectId(5fd976a0902d), title:'MongoDB in Action', description: 'MongoDB is NoSQL database', tags: ['MongoDB', 'database', 'NoSQL'], likes: 100 }Example of a JSON document Document-oriented databases aggregate data from documents and getting them into a searchable, organized form. A document-oriented database is able to ‘parse’ data from documents that store that data certain ‘keys’, with sophisticated support for retrieval.
Document-oriented databases are inherently a subclass of the key-value store. The difference exists in the way the data is processed: in a key-value store, the data is considered to be inherently opaque to the database; whereas a document-oriented system relies on internal structure in the document in order to extract metadata that the database engine uses for further optimization. Examples of document-oriented database include: MongoDB, RavenDB, CouchDB.
Document-oriented databases are suitable to be used in the cases of: event logs, content management systems/blogging platforms, analytics, eCommerce applications, etc. And not suitable to be used for complex cross-document transactions or queries that rely on fixed schema.
Wide column stores
Wide column stores are a type of NoSQL database that inspired by the Google Bigtable paper (🔗 https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf). Google describes their BigTable as “A sparse, distributed, persistent multidimensional sorted map”. A wide column store uses tables, rows, and columns, but unlike a relational database, the names and format of the columns can vary from row to row in the same table. A wide column store can be interpreted as a two-dimensional key-value store.
In a wide column store, a column consists of a name-value pair where the name also behaves as the key - each of these key-value pairs is a single column and is always stored with a timestamp value; a row is a collection of columns attached or linked to a key - a collection of similar rows makes a column family. Each column family can be compared to a container of rows in an RDBMS table where the key identifies the row and the row consists of multiple columns, except that various rows do not have to have the same columns - columns can be added to any row at any time without having to add it to other rows. A column can consist of a map of columns and is named as super column family.
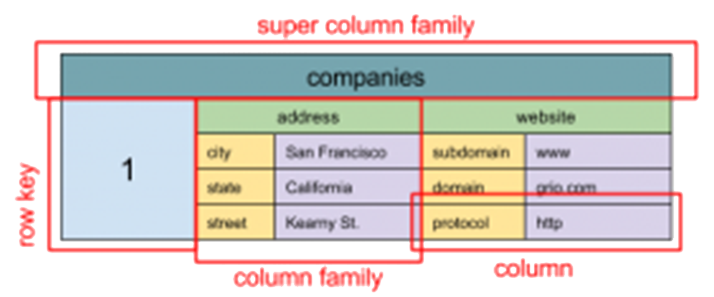
A super column family Popular wide column stores would include Google BigTable, Hbase, HyperTable, Cassandra, Amazon SimpleDB. The description above mostly based on Cassandra, but others have similar concepts.
Wide column stores are suitable in the use cases of: event logs, content management systems/blogging platforms, social network messaging systems (e.g. Facebook uses Hbase), and analytics on large data sets (e.g. Hbase & Hadoop), etc. While it should be avoided to use wide column store in the cases of complex cross-document transactions or queries that rely on fixed schema.
Graph databases
- A graph is composed of two elements:
- Node - represents an entity, e.g., a person, place, thing, category or other piece of data
- Relationship (edge) - represents how two nodes are associated
A graph database is a database management system with Create, Read, Update and Delete (CRUD) operations working on a graph data model. Graph databases usually come with a flexible data model, which means there is no need to define the types of edges and vertices. Relationships (edges) take first priority in graph databases. Edges have directional significance and allow you to find interesting patterns between the nodes.
Different from a relational database which stores entities with relationships defined by values of their properties, in graph databases, the relationships are stored explicitly as database objects.
Graph databases are optimized for traversing through connected data using specialised graph traversal languages, e.g. traversing through a list of contacts on your social network to find out the degree of connections.
Some of the popular graph databases are Neo4j, OrientDB, Titan. Some graph databases use other NoSQL types as backed storage, e.g Titan DB can be configured to use Cassandra or HBase
Typical use cases for graph databases would include social networking site, recommendation engine, Security analysis. Do not use graph databases in applications with operations on sets of data.
-
New types of databases
Multi-model databases
Most database management systems are organized around a single data model that determines how data can be organized, stored, and manipulated. In contrast, multi-model databases combine different types of database models into one integrated database engine. They provide a single back end and support multiple data models depending on the applications they support. Such databases can accommodate various data models including relational, object-oriented, key-value, document, wide-column, and graph models.
For example, ArangoDB combines key/value, document and graph models with one database core and a unified query language AQL (ArangoDB Query Language). This database uses JSON as a default storage format. Document is just key/value where the value is a JSON document. Graph nodes and edges stored as JSON documents. The AQL query language allows graph-oriented or document-oriented queries to be defined, or combinations of these
Multi-model databases are useful in situations where the same data needs to be retrieved using different access patterns.
Schema-less databases
Most NoSQL databases are considered to be schema-less databases. Contrast to fixed schemas defined in relational databases, no fixed schema defined at database level for NoSQL databases. E.g. documents stored in a document store can have varying sets of fields and field types.
While, in practice, there needs to be some kind of schema, as the application needs to understand what is in the database in order to use it. For data stored in scheme-less databases, the “Schema” is defined in the application, not the database.
NewSQL databases
NewSQL is a class of modern relational database management systems that seek to provide the same scalable performance of NoSQL systems for operational read-write workloads and maintain the consistency guarantees of a traditional relational database system. NewSQL databases are typically used in-memory architecture.
NewSQL databases differ in terms of their internal design, but all of them are relational DBMSs that run on SQL. They use SQL to ingest new information, execute many transactions at the same time, and modify the contents of the database. NewSQL databases support richer analytics making use of SQL and extensions. Many NewSQL databases offer NoSQL-style clustering with more traditional data and query models.
Top NewSQL databases include VoltDB, MemSQL, Starcounter, NuoDB.
-
Further reading
- Seven NoSQL Databases in a Week, Packt Publishing Ltd, Mar 2018
- Seven Databases in Seven Weeks: A Guide to Modern Databases and the NoSQL Movement, Pragmatic Bookshelf, Apr 2018
“Never expect to be an expert in any database just by reading this kind of books but it will give you understanding of various developments in this field, comparative analysis of those databases that helps you to decide which way to go. It will provide you a jump start for each database!”