-
Introduction
Document-oriented databases, also known as document store databases, aggregate databases, or simply document stores or document databases, are databases that use a document-oriented model to store data.
Document–oriented databases store each record and its associated data within a single document. Each document contains semi-structured data that can be queried against using various query and analytics tools.
Main implementations of document–oriented databases include: MongoDB, Apache CouchDB, Amazon DynamoDB, Azure DocumentDB, IBM Cloudant, and RavenDB.
Each document-oriented database implementation differs on the details of definition of document. In general, they all assume documents encapsulate and encode data (or information) in some standard format or encoding. Encodings generally in use include XML, JSON, and BSON.
We will look a specifical document-oriented database: MongoDB. MongoDB stores data records as BSON documents. BSON is a binary representation of JSON documents.
-
JSON Introduction
JSON (JavaScript Object Notation, 🔗 http://www.json.org/) is a text format based on a subset of JavaScript Programming Language. It is a lightweight data-interchange format.
- JSON is built on two structures:
- A collection of name/value pairs.
In various languages, this is realized as an object, record, struct, dictionary, hash table, keyed list, or associative array. - An ordered list of values.
In most languages, this is realized as an array, vector, list, or sequence.
These are universal data structures. Virtually all modern programming languages support them in one form or another.
In JSON, an object is an unordered set of name/value pairs.
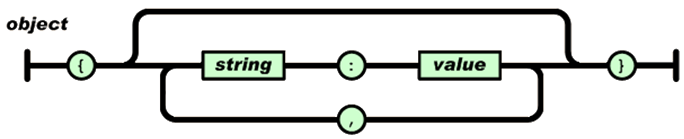
An object begins with { (left curly brace) and ends with } (right curly brace). Each name is followed by : (colon) and the name/value pairs are separated by , (comma).
An array is an ordered collection of values.

An array begins with [ (left square bracket) and ends with ] (right square bracket). Values are separated by , (comma).
A value can be a string in double quotes, or a number, or true or false or null, or an object or an array. These structures can be nested.
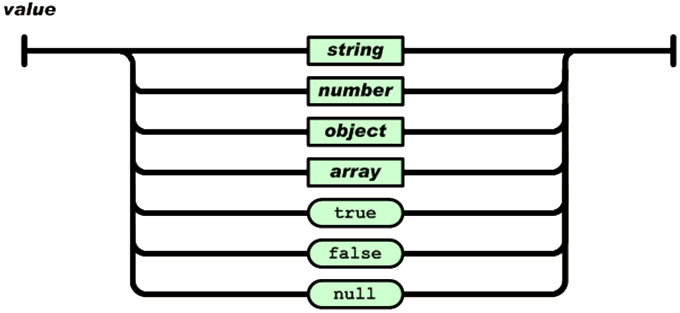
A string is a sequence of zero or more Unicode characters, wrapped in double quotes, using backslash escapes. A character is represented as a single character string. A string is very much like a C or Java string.
Below is a JSON example:
{"menu": { "id": "file", "value": "File", "popup": { "menuitem": [ {"value": "New", "onclick": "CreateNewDoc()"}, {"value": "Open", "onclick": "OpenDoc()"}, {"value": "Close", "onclick": "CloseDoc()"} ] } }}In this JSON example, there are six objects:
1. The first object named “menu” has an object value
2. The second object includes three sets of name/value pairs
3. The third object is named as “menuitem”
4. The other three objects form the array value of the “menuitem” object
-
MongoDB Document Structure
MongoDB documents are composed of field-value pairs and have the following structure:
{ field1: value1, field2: value2, field3: value3, ... fieldN: valueN }The field names are strings. The value of a field can be any of the BSON data types (as listed in the table below), including other documents, arrays, and arrays of documents.
BSON data types Data type Description String text values, e.g. “Glasgow” Boolean either TRUE or FALSE. Integer (32b and 64b): numerical value, e.g. 5 Boolean TRUE or FALSE Double floating point values, e.g. 5.24 Min/Max keys values which will always compare lower / higher than any other type Timestamp used to store a timestamp, 64-bit integer Null used for a Null value Date used to store the current date or time in UNIX time format (POSIX time), 64-bit integer Object ID used to store the document’s ID, generated by database Binary data used to store binary data. Regular expression JavaScript Code An example MongoDB document:
{ _id: ObjectId("5099803df3f4948bd2f98391"), name: {first: "Alan", last: "Turing"}, birth: new date('Jun 23 1912'), death: new date('Jun 07, 1954), contribs: ["Turing machine", "Turing test", "Turingery"], views : NumberLong(1250000) }Restrictions on field name and value
- MongoDB documents have the following restrictions on field names:
- The field name _id is reserved for use as a primary key; its value must be unique in the collection, is immutable, and may be of any type other than an array.
- The field names cannot start with the dollar sign ($) character.
- The field names cannot contain the dot (.) character.
- The field names cannot contain the null character.
The limitation on field value is: for indexed collections, the values for the indexed fields have a Maximum Index Key Length limit.
-
MongoDB vs Relational Database
The following table presents the various relational DBMS terminology and concepts and the corresponding MongoDB terminology and concepts.
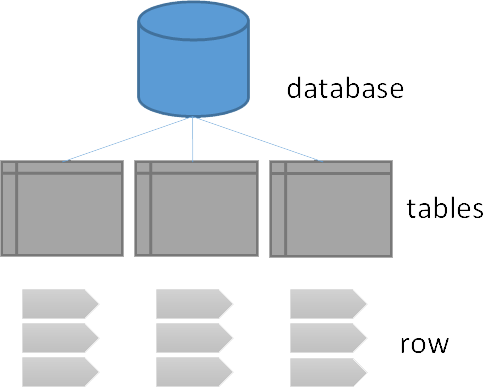
RDBMS MongoDB Database Database Table Collection Tuple/Row Document Column Field Table Join Embedded Documents Primary Key Primary Key (Default key_id provided by MongoDB itself) Database Server and Client Mysqld/Oracle MongoDB mysql/sqlplus Mongo Data models on MongoDB and RDBMS are illustrated below.
Relational data model used in RDBMS 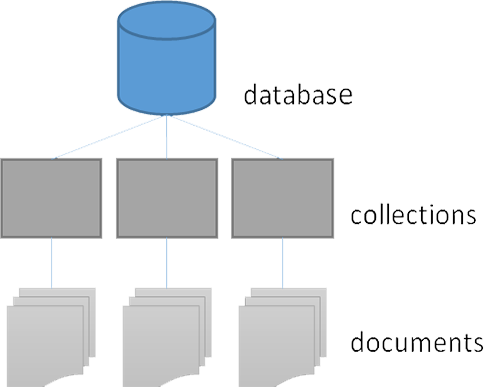
Document data model used in MongoDB In a relational database, the meaning of data items in each row is defined by the design of the table that contains the row; each column has its name, type, and constraint specified. A relational database has a well-defined structure, or schema, for the data it can store. It will reject data that doesn’t conform to the schema.
In a MongoDB database, the meaning of data items in a document is contained in the document itself, i.e., the name part of name/value pairs. Database/collections have no knowledge of meaning of data. A MongoDB database (like many NoSQL stores) is schemaless. It will allow documents with any structure to be stored. MongoDB databases can store unstructured data where the content is not known apriori and can vary from document to document.
-
Getting start with MongoDB
Install MongoDB
MongoDB is released as two editions: Community and Enterprise. Community is the open source release of MongoDB. MongoDB Community edition can be downloaded from: 🔗 https://www.mongodb.com/download-center?initial=true#community.
MongoDB supports various platforms including: windows, Linux and macOS. Instructions on how to install MongoDB Community Edition can be found at: 🔗 https://docs.mongodb.com/manual/administration/install-community/.
After installation, the following tools should be found in bin folder:
|-- bin ||-- mongo (the database shell) ||-- mongod (the core database server) ||-- mongos (auto-sharding process) ||-- mongodump (dump/export utility) ||-- mongorestore (restore/import utility)
Run MongoDB Community Edition
MongoDB requires a data folder to store its files. MongoDB will not start if a data directory doesn’t exist. The default data directory is:
/data/db (Linux, MacOS) c:\data\db (Windows)
It may needed to set permissions to allow user to read & write the data directory.
Start MongoDB server
To start a MongoDB server, execute the following command at system command prompt:
mongod --dbpath data/db
-dbpath option allows you to specify data directory, can omit if using the default location, example here assumes data directory is data/db in the current working directory
Assuming here that MongoDB bin folder is in path, may need to specify full path otherwise.
You should see startup messages including something like below, tells you the server is alive and what TCP port number is being used (27017).
2018-09-31T14:36:40.701+0000 I NETWORK [thread1] waiting for connections on port 27017
Now you need to keep the terminal window open. Server will shut down if you close the terminal window.
You can also install and run MongoDB as a service, detached from any terminal window.
Run mongo shell client
Once the MongoDB server is started, from another terminal on the same computer, enter the following command to run mongo shell client:
mongod
This assumes that there is no security configured in the database, which is OK for learning. But in a “real” installation, username/password would need to specify – see documentation
This will look for server instance running on localhost at default port (27017)
You should see the following message and the > shell prompt (may see other messages also):
MongoDB shell version v3.4.0 connecting to: mongodb://127.0.0.1:27017 MongoDB server version: 3.4.0 >
MongoDB server can also be accessed from a remote machine with mongo client installed, e.g.
mongo --host 192.168.231.127 --port 27017
Mongo shell provides a way to interact with MongoDB database through commands. The shell client is always available if MongoDB is installed.
Separate tools are available that provide a GUI or web interface, e.g. MongoClient, interact with the database. (🔗 https://docs.mongodb.com/ecosystem/tools/)
-
MongoDB CRUD Operations
In this subsection, MongoDB’s create, update and delete operations will be introduced. The read operation will be covered in next week’s material.
The use command
MongoDB use DATABASE_NAME is used to create database. The command will create a new database if it doesn't exist, otherwise it will return the existing database. Basic syntax of use DATABASE_NAME statement is as follows:
use DATABASE_NAME
If you want to use a database with name ‘myDatabase’, then use DATABASE statement would be:
>use myDatabase switched to db myDatabase
To check your currently selected database, use the command db:
>db myDatabase
You can insert a document in the specified collection in the current database, collection will be created if it doesn’t exist, as follows:
>db.myCollection.insert( {"country":"Scotland"})Since version 3.2, MongoDB provides the insertOne() and insertMany() methods to insert documents into a collection:
db.myCollection.insertOne() db.myCollection.insertMany()
You can check that the document has been stored using the find function:
>db.myCollection.find() {"_id" : ObjectId("59e01dd19400bbe099b3b35d"), "country" : "Scotland"} {"_id" : ObjectId("59e01ea59400bbe099b3b35e"), "country" : "England", "city" : "London"} {"_id" : ObjectId("59e0200d9400bbe099b3b35f"), "city" : "Washington", "sport" : "Basketball", "country" : "USA"}You didn’t have to specify what properties a document can have, and different documents can have different fields.
MongoDB adds an _id property to each document, if you do not specify the _id value manually, then the type will be set to a special BSON datatype that consists of a 12-byte binary value:
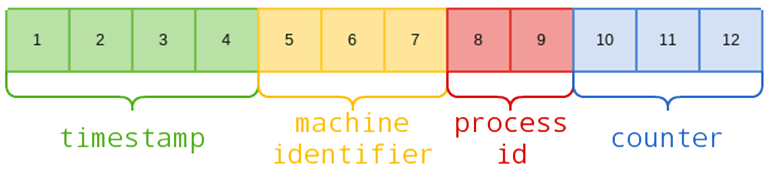
Update and delete operations
MongoDB’s updateOne() method is used to update a single document within the existing document based on the filter.
The example below updates an existing document by adding a new property:
db.myCollection.updateOne ( {"country" : "USA"}, {$set : {"city" : "New York"}})MongoDB’s remove() method deletes documents from a collection. For example:
db.myCollection.remove({"city" : "London"})Using the drop() method, a whole collection will be deleted from the database. In the following example, ‘myCollection’ is removed from current database.
db.myCollection.drop()
For further details on MongoDB CRUD operations, please refer to: 🔗 https://docs.mongodb.com/manual/crud/
-
Data modelling
With a relational database, you need to define schema before you can load data into the database. With a NoSQL system, data modelling is strictly optional - at least during the ingest phase. However, even though you do not specify a data model when you bring information into a NOSQL system, the process of making sense of that information and producing something useful from it actually yields a model as a byproduct even if you do not realize it. A data model is the basis of a lot of things that we do in data management and analytics. E.g., if you want to query the data, first you have to know what is there.
Relational database modelling is typically driven by the structure of available data. The main design theme is “What answers do I have?”. Relational database modelling focuses on how to organise the data with an emphasis on referential integrity.
NoSQL data modelling is typically driven by application-specific access patterns, i.e. how the data in the database is going to be queried. The main design theme is “What questions do I want to ask of my database?”. This exercise of finding out what questions one would like to ask of the NoSQL database serves to define the entities and the relationship amongst those entities. Once you have a list of questions, you then need to design a model that will answer those questions via the NoSQL database.
Data in MongoDB has a flexible schema. Unlike SQL databases, where you must determine and declare a table’s schema before inserting data, MongoDB’s collections do not enforce document structure. Documents in the same collection do not need to have the same set of fields or structure, and common fields in a collection’s documents may hold different types of data. However, effective data models support your application needs. The key consideration for the structure of your MongoDB documents is the decision to embed or to use references. Relationships in MongoDB represent how various documents are logically related to each other. Relationships can be modelled via Embedded and Referenced approaches. Such relationships can be either 1:1, 1:N, N:1 or N:N.
Embedded Data Models
You may embed related data in a single structure or document, these schema are generally known as “denormalized” models.

Embedded data models allow applications to store related pieces of information in the same database record. As a result, applications may need to issue fewer queries and updates to complete common operations. In general, embedding provides better performance for read operations, as well as the ability to request and retrieve related data in a single database operation.
However, embedding related data in documents may lead to situations where documents grow after creation. With the MMAPv1 storage engine, document growth can impact write performance and lead to data fragmentation.
Normalized Data Models
Normalized data models describe relationships among documents using references.
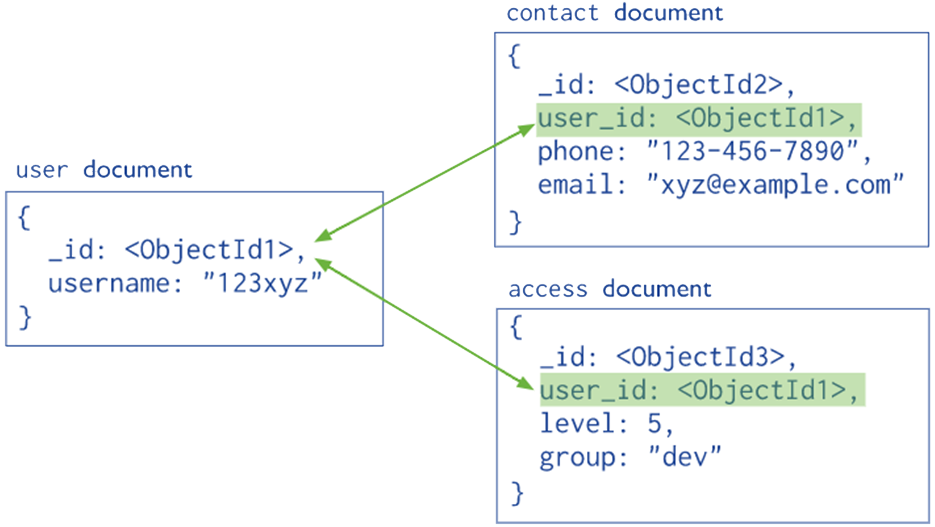
In general, we use normalized data models when embedding would result in duplication of data but would not provide sufficient read performance advantages to outweigh the implications of the duplication, or trying to represent more complex many-to-many relationships, or to model large hierarchical data sets.
References provides more flexibility than embedding. However, client-side applications must issue follow-up queries to resolve the references. In other words, normalized data models can require more round trips to the server.
- Below are some general considerations for designing Schema in MongoDB:
- Design your schema according to user requirements.
- Combine objects into one document if you will use them together. Otherwise separate them (but make sure there should not be need of joins).
- Duplicate the data (but limited) because disk space is cheap as compare to compute time.
- Do joins while write, not on read.
- Optimize your schema for most frequent use cases.
- Do complex aggregation in the schema.
-
Database References
As mentioned in last section, referenced relationships (also referred to as Manual References, where the referenced document's id is manually stored inside other document) are used to implement a normalized data structure in MongoDB. While, if a document contains references from different collections, this can be implemented using MongoDB DBRefs.
Manual references save the _id field of one document in another document as a reference, as shown in the example in the last section. Application can run a second query to return the related data
With DBRefs, references from one document to another using the value of the first document’s _id field ($id), collection name ($ref), and, optionally, its database name ($db). To resolve DBRefs, an application must perform additional queries to return the referenced documents – some language drivers have helper methods that form the query for the DBRef automatically.
{ "_id" : ObjectId("5126bbf64aed4daf9e2ab771"), // .. application fields "creator" : { "$ref" : "creators", "$id" : ObjectId("5126bc054aed4daf9e2ab772"), "$db" : "users" } } -
Indexes
Indexes support the efficient execution of queries in MongoDB. Without indexes, MongoDB must scan every document of a collection to select those that match the query statement, which is very inefficient. An index is a data structure that stores information about the values of specified fields in the documents of a collection
Indexes are used by MongoDB’s query optimizer to quickly sort through and order documents. The index stores the value of a specific field or set of fields, ordered by the value of the field. The ordering of the index entries supports efficient equality matches and range-based query operations. MongoDB can return sorted results by using the ordering in the index
- MongoDB supports three types of index:
- Single field index
- Compound index - can support queries that match on multiple fields
- Multikey index – to index elements in an array field
MongoDB creates a default index on the _id field during the creation of a collection. The _id index prevents clients from inserting two documents with the same value for the _id field. You cannot drop this index on the _id field.
Creating indexes
In this subsection, two MongoDB collections are used in the index creations: “products” and “inventory”. Example documents from these two collections are illustrated below.
{ "_id" : ObjectId(...), "item" : "Banana", "category" : ["food", "produce", "grocery"], "location" : "4th Street Store", "stock" : 4, "type" : "cases", "ratings" : [ 5, 8, 9 ] }An example document from the “products” collection
{ _id: 1, item: "abc", stock: [ { size: "S", color: "red", quantity: 25}, { size: "S", color: "blue", quantity: 10}, { size: "M", color: "blue", quantity: 50} ] }An example document from the “inventory” collection
In addition to the default _id index, MongoDB supports the creation of user-defined ascending/descending indexes on a single field of a document. The example below will create a single field index on field “item” of “products” collection in descending order:
db.products.createIndex({"item": -1})For a single field index, the sort order (i.e. ascending or descending) of the index key does not really matter, because MongoDB can traverse the index in either direction.
In the following example, a compound index is created on fields “item” and “stock” of “products” collection in ascending order:
db.products.createIndex({ "item": 1, "stock": 1 } )The order of fields listed in a compound index has significance. In the example above, the index sorts by “item” first and then, within each “item” value, sorts by stock.
MongoDB uses multikey indexes to index the content stored in arrays. If you index a field that holds an array value, MongoDB can create separate index entries for every element of the array. These multikey indexes allow queries to select documents that contain arrays by matching on element or elements of the arrays. In the example below, a multikey index is create on the array field “ratings” of “products” collection in ascending order:
db. products.createIndex({ "ratings": 1 } )Note: in older versions of MongoDB, ensureIndex is used to create index instead of createIndex
Different types of index can be combined together. For example, below a compound multikey index on “size” and “quantity” fields of array of embedded objects, where array is “stock” field of the parent object in the “inventory” collection, is created.
db.inventory.createIndex( { "stock.size": 1, "stock.quantity": 1 } ) -
Replication and Sharding
MongoDB can be installed as a standalone database on a single computer. However, MongoDB production installations typically involve clusters of computers. There are two important processes directly relevant to the cluster based installation: Replication and Sharding.
These two techniques are used for two different, complementary purposes. Replication provides redundancy and high data availability. Sharding distributes a large set of data across multiple nodes, each with its own subset of the data. These techniques are usually used together within a cluster, which can have clusters with 1000+ nodes.
Replication
Replication is the process of synchronizing data across multiple servers. Replication provides a level of fault tolerance against the loss of a single database server. MongoDB achieves replication by the use of replica set. A replica set in MongoDB is a group of mongod processes that maintain the same data set. Replica sets provide redundancy and increases data availability.
A replica set (as illustrated below) contains several data bearing nodes and optionally one arbiter node.
Of the data bearing nodes, one and only one member is deemed the primary node, while the other nodes are deemed secondary nodes. Primary node receives all write operations. Secondary nodes replicate operations from the primary node to maintain an identical data set. If primary is unavailable, secondaries hold election to select a replacement primary. Arbiter node does not keep a copy of the data, but play a role in elections.
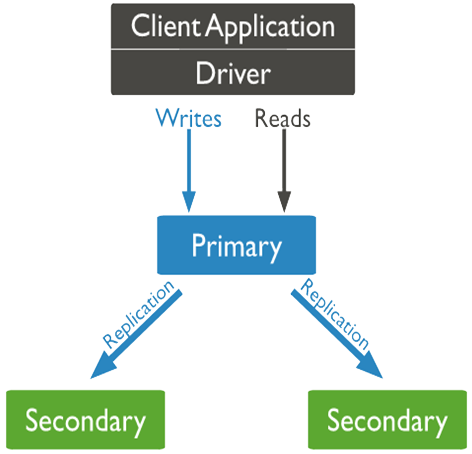
The minimum recommended configuration for a replica set is a three member replica set with three data-bearing members: one primary and two secondaries.
Sharding
Sharding is a method for distributing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations.
- A MongoDB sharded cluster consists of:
- shard: Each shard contains a subset of the sharded data. Each shard can be deployed as a replica set.
- mongos: The mongos acts as a query router, providing an interface between client applications and the sharded cluster.
- config servers: Config servers store metadata and configuration settings for the cluster. As of MongoDB 3.4, config servers must be deployed as a replica set (CSRS).
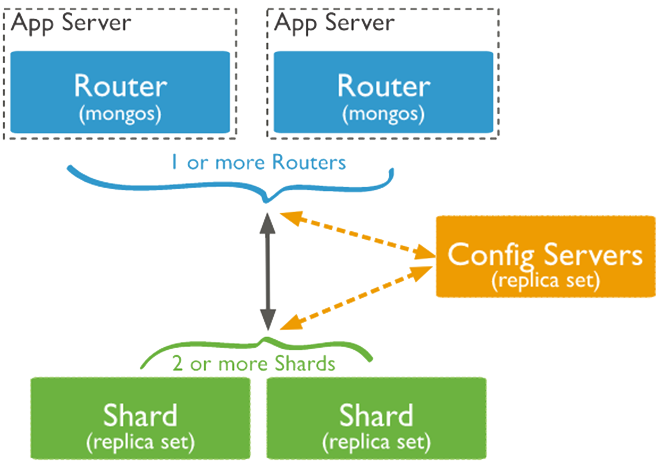
MongoDB uses shard keys to determine the distribution of the collection’s documents among the cluster’s shards. The shard key consists of an immutable field or fields that exist in every document in the target collection. MongoDB partitions data in the collection using ranges of shard key values. Each range is associated with a chunk. MongoDB attempts to distribute chunks evenly among the shards in the cluster
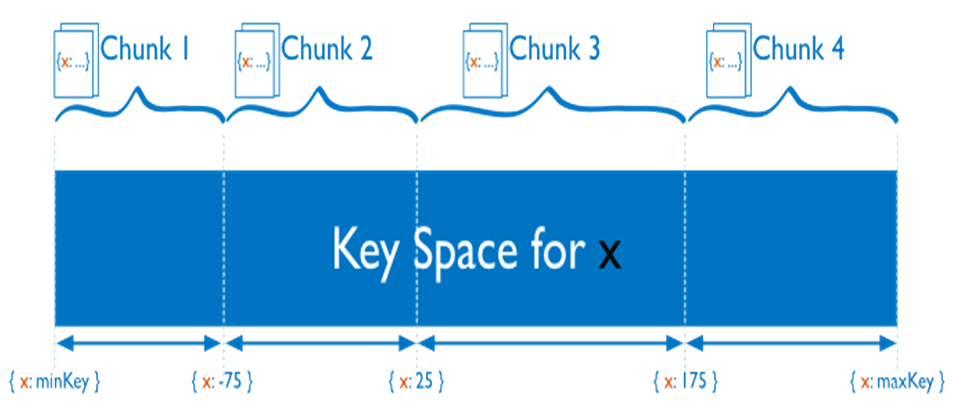
The choice of shard key affects how the sharded cluster balancer creates and distributes chunks across the available shards. The ideal shard key allows MongoDB to distribute documents evenly throughout the cluster
- To choose the shard key, here are some considerations:
- Cardinality – the number of possible values, and hence the largest number of chunks
- Frequency – how often a given value occurs in the data, key where a subset of values occur often can lead to uneven distribution and bottlenecks
- Rate of change – if shard keys are monotonically increasing inserted data may be always routed to chunk with maxKey as upper bound, leading to bottlenecks
-
Further reading
🔗 https://docs.mongodb.com/manual/administration/install-community/
🔗 https://docs.mongodb.com/getting-started/shell/
🔗 https://docs.mongodb.com/manual/crud/
🔗 https://docs.mongodb.com/manual/core/data-modeling-introduction/