-
Inserting Documents - a recap
In previous lab sessions, you have practiced different methods to insert documents into a collection, and here is a summary of those methods.
The insertOne() method
To insert a single document into a MongoDB collection, use MongoDB’s insertOne() method. The basic syntax of insertOne() command is as follows:
db.collection.insertOne ( )
For example, to insert a JSON document to the ‘movie’ collection:
db.collection.insertOne ({ imdb : "tt0084726", title: : "Star Trek II: The Wrath of Khan", year: 1982, type : "movie" })run this command, a document like below will be returned,
{ "acknowledged" : true, "insertedId" : ObjectId("59e92ad38eeffc9227a4a82") }which contains:
A boolean ‘acknowledged’ as true if the operation ran with write concern or false if write concern was disabled.
A field ‘insertedId’ with the _id value of the inserted document.
If the collection does not exist, then the insertOne() method creates the collection.
The insertMany() method
To insert a multiple document into a MongoDB collection, use MongoDB’s insertMany() method. The basic syntax of insertMany() command is as follows:
db.collection.insertMany( )
For example, to insert an array of document to the ‘movie’ collection:
db.movie.insertNamy( [ { "imdb" : "tt0796366", "title" : "Star Trek", "year" : 2009, "type" : "movie" }, { "imdb" : "tt1408101", "title" : "Star Trek Into Darkness", "year" : 2013, "type" : "movie" }, { "imdb" : "tt0117731", "title" : "Star Trek: First Contact", "year" : 1996, "type" : "movie" } ] )run this command, a document like below will be returned,
{ "acknowledged" : true. "insertedIds" : [ ObjectId{"59e92e4d8eeffc9227fa4a83"}, ObjectId{"59e92e4d8eeffc9227fa4a84"}, ObjectId{"59e92e4d8eeffc9227fa4a85"} ] } >which contains:
A boolean ‘acknowledged’ as true if the operation ran with write concern or false if write concern was disabled.
A field ‘insertedIds’ with an array of _id values for each successfully inserted documents.
If the collection does not exist, then the insertOne() method creates the collection.
The load() function
To load and run a JavaScript file (.js file) into the current shell environment, using the load() function. The basic syntax of load() command is:
load(file)
For example, there is a JavaScript file named ‘insertMany.js’ as shown below:
db.moviesScratch.insertMany( [ {"imdb" : "tt0084726", "title" : "Star Trek II: the Wrath of Khan", "year" : 1982, "type" : "movie"}, {"imdb" : "tt0796366", "title" : "Star Trek", "year" : 2009, "type" : "movie"}, {"imdb" : "tt1408101", "title" : "Star Trek Into Darkness", "year" : 2013, "type" : "movie"}, {"imdb" : "tt0117731", "title" : "Star Trek: First Contact", "year" : 1996, "type" : "movie"} ] );You can load and run the ‘insertMany.js’ file as:
> load("insertMany.js") true >Filename in this command should be specified with relative or absolute paths.
The mongoimport tool
The mongoimport tool can import content from an extended JSON, CSV, etc.
The mongoimport tool does not run from the mongo shell, it run from the system command line. To use mongoimport, you must run mongoimport against a running mongod or mongos instance as appropriate.
The following mongoimport command will import the content in the ‘primerdataset.json’ file into the ‘restaurant’ collection in the ‘test’ MongoDB database. If the ‘restaurant’ already exist, drop it before importing the data from the input file.
c:\> mongoimport --db test -- collection restaurants --drop --file primerdataset.json
- When using mongoimport to import data, you should ensure that values in your JSON file are in forms that MongoDB can interpret as valid values for its datatypes. For example:
- Dates should be entered as JavaScript Date objects
- Note that months are numbered 0-11 in JavaScript
-
The find() Function
MongoDB does not support a query language such as SQL. To query data from MongoDB collection, you need to use MongoDB's find() method. The basic syntax of find( ) method is:
db.collection.find( )
all the documents in the collection will be displayed in a non-structure way. It corresponds to the following SQL statement:
select * from collection
In order to display the results in a formatted way, you can use the pretty() method. The basic syntax is:
db.collection.find( ).pretty()
documents in the collection will be displayed in a formatted way.
Query document
To build a query on a collection, you should specify a query document with properties you wish the results to match and pass this as a parameter to find(). Query document is a JSON document whose properties are either field names of documents in the collection or MongoDB operators - operators have names that start with $, e.g. $lt, $exists. The table below listed the Relational DMMS Where clause equivalents in MongoDB:
Operation Syntax Example RDBMS Equivalent Equality {<key>:<value>} db.mycol.find({"by":"tutorials point"}) where by = 'tutorials point' Less Than {<key>:{$lt:<value>}} db.mycol.find({"likes":{$lt:50}}) where likes < 50 Less Than Equals {<key>:{$lte:<value>}} db.mycol.find({"likes":{$lte:50}}) where likes <= 50 Greater Than {<key> : {$gt:<value>}} db.mycol.find({"likes":{$gt:50}}) where likes > 50 Greater Than Equals {<key> : {$gte:<value>}} db.mycol.find({"likes":{$gte:50}}) where likes >= 50 Not Equals {<key> : {$ne:<value>}} db.mycol.find({"likes":{$ne:50}}) where likes != 50 Other functions can be chained with find to process the results, e.g. sort, limit, pretty.
Further details on SQL to MongoDB Mapping can be found at:
🔗 https://docs.mongodb.com/manual/reference/sql-comparison/
Query on a single field
The ‘movie’ collection queried in this section’s examples are same as the one you used in the lab.
Example 1: find the movie whose ‘imdb’ value is "tt0084726".
In this example the following query document is used:
{imdb: "tt0084726"}And here is the return:
> db.movie.find{{imdb : "tt0084726"}}.pretty() { "_id" : ObjectId("59e92ad38eeffc9227fa4a82"), "imdb" : "tt0084726", "title" : "Star Trek II: The Wrath of Khan", "year" : 1982, "type" : "movie" }Example 2: Find the movies produced in year “2009”.
In this example the following query document is used:
{year : 2009}And the return is as follow:
> db.movie.find{{year : 2009}}.pretty() { "_id" : ObjectId("59e92e4d8eeffc922fa4a83"), "imdb" : "tt0796366", "title" : "Star Trek", "year" : 2009, "type" : "movie" } { "_id" : ObjectId("59e94bca8eeffc9227fa4a8c"), "imdb" : "tt1401081", "title" : "Ice Age 3: Dawn of the Dinosaurs", "year" : 2009, "type" : "movie" }Example 3: Find the movie produced later than 2005 from the ‘movie’ collection.
db.movie.find{{year : {$gt:2005}}}In this query, the $gt operator (greater than) is used on a field value. And here is the return of this query:
>db.movie.find{{year : {$gt: 2005}}} { "_id" : ObjectId("59e92e4d8eeffc9227a4a83"), "imdb" : "tt0796366", "title" : "Star Trek", "year" : 2009, "type" : "movie"} { "_id" : ObjectId("59e92e4d8eeffc9227a4a84"), "imdb" : "tt1408101", "title" : "Star Trek Into Darkness", "year" : 2013, "type" : "movie"} { "_id" : ObjectId("59e94bca8eeffc9227fa4a8b"), "imdb" : "tt0769366", "title" : "Ice Age 2: the Meltdown", "year" : 2006, "type" : "cartoon"} { "_id" : ObjectId("59e94bca8eeffc9227fa4a8c"), "imdb" : "tt1401081", "title" : "Ice Age 3: Dawn of the Dinosaurs", "year" : 2009, "type" : "cartoon"} { "_id" : ObjectId("59e94bca8eeffc9227fa4a8d"), "imdb" : "tt0171831", "title" : "Ice Age 4: Continental Drift", "year" : 2012, "type" : "cartoon"}Query on multiple fields
In this section, some examples query the ‘restaurant’ collection, and below is a sample document in this collection.
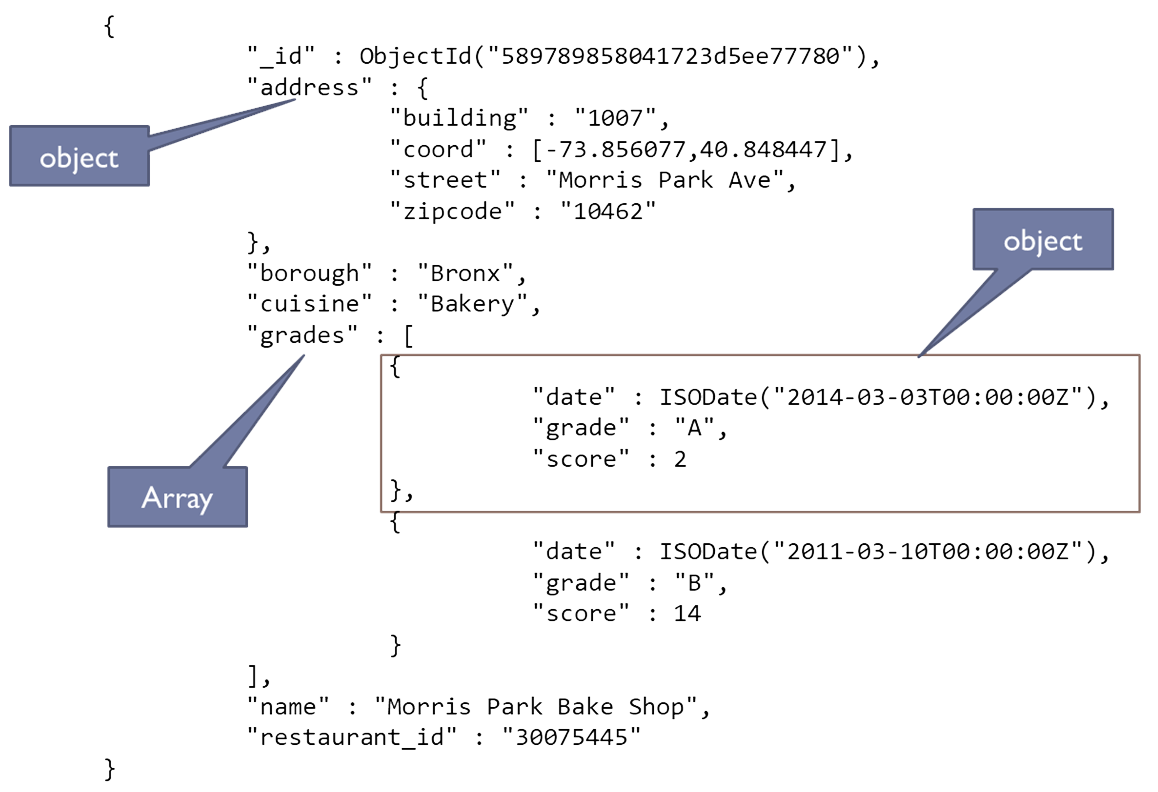
Example 4: Find two “American” restaurants located in “Bronx” borough.
db.restaurants.find({cuisine : "American", borough : "Bronx"}).limit(2)In this find() method, the query document includes two name/value pairs separated by ‘,’, and MongoDB treats it as AND condition. The limit() method limits the number of documents in the result set. In this example, the query returns at most two documents. Run this query and the return is:
> db.restaurants.find({cuisine : "American", borough : "Bronx"}).limit(2) { "_id" : ObjectId("59e565aa8b8edcdd5b7a43c5"), "address" : {"building" : "2300", "coord" : [-73.8796113, 40.8502883], "street" : "Southern Boulevard", "zipcode" : "10460"}, "borough" : "Bronx", "cuisine" : "American", "grades" : [{"date" : "ISODate("2014-05-28T00:00:00Z"), "grade" : "A", "score" : 11}, {"date" : "ISODate("2013-06-19T00:00:00Z"), "grade" : "A", "score" : 4}, {"date" : "ISODate" : ("2012-06-15T00:00:00Z"), "grade" : "A", "score" : 3}], "name" : "Wild Asia", "restaurant_id" : "40357217"} { "_id" : ObjectId("59e565aa8b8edcdd5b7a43f6"), "address" : {"building" : "658", "coord" : [-73.81363999999999, 40.82941100000001], "street" : "Clarence Ave", "zipcode" : "10465"}, "borough" : "Bronx", "cuisine" : "American", "grades" : [{"date" : "ISODate("2014-06-21T00:00:00Z"), "grade" : "A", "score" : 5}, {"date" : "ISODate("2012-07-11T00:00:00Z"), "grade" : "A", "score" : 10}], "name" : "Manhem Club", "restaurant_id" : "40364363"}Example 5: Find restaurants whose id is either ‘30075445’ or ‘30191841’.
db.restaurants.find({$or : [{restaurant_id : "30075445"}, {restaurant_id : "30191841"}]})MongoDB supports boolean OR queries, but you must use a special operator ($or) to achieve it, as used in this example. The basic syntax of OR is:
db.collection.find( { $or : [ {name1 : value1}, {name2: value2} ] } )The return of the example query is:
> db.restaurants.find({$or : [{restaurant_id : "30075445"}, {restaurant_id : "30191841"}]}) { "_id" : ObjectId("59e565aa8b8edcdd5b7a43bb"), "address" : {"building" : "1007", "coord" : [-73.856077, 40.848447], "street" : "Morris Park Ave", "zipcode" : "10462"}, "borough" : "Bronx", "cuisine" : "Bakery", "grades" : [{"date" : "ISODate("2014-03-03T00:00:00Z"), "grade" : "A", "score" : 2}, {"date" : "ISODate("2013-09-11T00:00:00Z"), "grade" : "A", "score" : 6}, {"date" : "ISODate" : ("2013-01-24T00:00:00Z"), "grade" : "A", "score" : 10}], {"date" : "ISODate("2011-11-23T00:00:00Z"), "grade" : "A", "score" : 9}, {"date" : "ISODate("2011-03-10T00:00:00Z"), "grade" : "B", "score" : 14}], "name" : "Morris Park Bake Shop", "restaurant_id" : "30075445"} { "_id" : ObjectId("59e565aa8b8edcdd5b7a43bd"), "address" : {"building" : "351", "coord" : [-73.98513559999999, 40.7676919], "street" : "West 57 Street", "zipcode" : "10019"}, "borough" : "Manhatten", "cuisine" : "Irish", "grades" : [{"date" : "ISODate("2014-09-06T00:00:00Z"), "grade" : "A", "score" : 2}, {"date" : "ISODate("2013-07-22T00:00:00Z"), "grade" : "A", "score" : 11}, {"date" : "ISODate" : ("2012-07-31T00:00:00Z"), "grade" : "A", "score" : 12}], {"date" : "ISODate("2011-12-29T00:00:00Z"), "grade" : "A", "score" : 12}], "name" : "Dj Reynolds Pub And Restaurant", "restaurant_id" : "30191841"}Projection document
In MongoDB, projection means selecting only the necessary data rather than selecting whole of the data of a document. MongoDB’s find() method accepts two optional parameters: one is the query document (or query filter), and the other one is projection document.
db.collection.find(query filter, projection document)
Projection document specifies the fields to return in the documents that match the query filter. If you want to return all fields in the matching documents, omit the ‘projection document’ parameter.
Form of the projection document is:
{field1; <value>, field2: <value> ...}Where the <value> can be any of the following:
1 or true to include the field in the return documents.
0 or false to exclude the field.
In the example 4 above, the query found two “American” restaurants located in “Bronx” borough, and the returned documents include all the fields in it. If we just want to show the ‘borough’ and ‘restaurant_id’ in the return, a project document should be added into the find command:
db.restaurants.find({cuisine : "American", borough : "Bronx" }, {borough :1, restaurant_id: 1}).limit(2).sort({restaurant_id : 1}).pretty()and here is the return:
> db.restaurants.find({cuisine : "American", borough : "Bronx" }, {borough :1, restaurant_id: 1}).limit(2).sort({restaurant_id : 1}).pretty() { "_id" : objectId("59e565aa8b8edcdd5b7a43c5"), "borough" : "Bronx", "restaurant_id" : "40357217" } { "_id" : objectId("59e565aa8b8edcdd5b7a43fb"), "borough" : "Bronx", "restaurant_id" : "40364363" } >As you can see, except the two fields specified in the the projection document, the _id field also returned. In MongoDB, the _id field is included by default. If you don't want it, you need to exclude it explicitly as follow:
db.restaurants.find({cuisine : "American", borough : "Bronx" }, {borough :1, restaurant_id : 1, _id : 0}).limit(2).sort({restaurant_id : 1}).pretty()now, only two fields in the return:
>db.restaurants.find({cuisine : "American", borough : "Bronx" }, {borough :1, restaurant_id : 1, _id : 0}).limit(2).sort({restaurant_id : 1}).pretty() {"borough" : "Bronx", "restaurant_id" : "40357217"} {"borough" : "Bronx", "restaurant_id" : "40364363"} > -
Advanced query
Query on Embedded Documents
When your data model has embedded documents, and you need to query on the values in fields of embedded objects. Then use dot notation:
"field.nestedField"
to specify a query condition on fields in an embedded document. In the following example, we find restaurant located on ‘Flatbush Avenue’ street, and use “address.street” to specify the condition.
> db.restaurants.find({"address.street" : "Flatbush Avenue"}, {"name" : 1, "_id" : 0}).limit(10) {"name" : "Wendy'S"} {"name" : "New Floridian Diner"} {"name" : "Mcdonald'S"} {"name" : "Geido Restaurant"} {"name" : "Frank'S Pizza Restaurant"} {"name" : "Antonio'S Pizza"} {"name" : "La Cabana Restaurant"} {"name" : "Gino'S Pizza"} {"name" : "Crystal Manor"} {"name" : "Family Pizza"} >You can often omit quotes round field names with no error, but embedded field names using dot notation need quotes and you get an error if omitted.
Query Arrays
To specify equality condition on an array, use the query document:
<field>:<value>where <value> is the exact array to match, including the order of the elements.
The example below will find movies with “countries” field’s value exactly same as the array ["Italy","USA"]:
db.movieDetails.find({countries:["Italy","USA"]}, {countries:1})and the return is:
> db.movieDetails.find({countries:["Italy","USA"]}, {countries:1}) { "_id" : ObjectId("59e920f28eeffc9227fa41ce"), "countries" :["Italy", "USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4297"), "countries" :["Italy", "USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4625"), "countries" :["Italy", "USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa49e9"), "countries" :["Italy", "USA"]}In order to find documents with all the specified values in a field, without regard to order or other elements in the array, you should use the $all operator.
For example, run the following find command:
db.movieDetails.find({countries: {$all:["Italy","USA"]}}, {countries:1})It will return:
> db.movieDetails.find({countries: {$all:["Italy","USA"]}}, {countries:1}) { "_id" : ObjectId("59e920f28eeffc9227fa418b"), "countries" :["Italy", "USA", "Spain"]} { "_id" : ObjectId("59e920f28eeffc9227fa41ce"), "countries" :["Italy", "USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa424e"), "countries" :["USA", "France", "Italy", "Germany" ]} { "_id" : ObjectId("59e920f28eeffc9227fa4297"), "countries" :["Italy", "USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4625"), "countries" :["Italy", "USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa49c1"), "countries" :["USA", "Luxembourgh", "France", "Italy"]} { "_id" : ObjectId("59e920f28eeffc9227fa49e9"), "countries" :["Italy", "USA"]}Which include all the documents with “countries” field’s value includes “Italy” and “USA”, no matter what the order these two values is or if there is any other values in the array.
If you want to have documents with any of the specified values in a field, the $in operator should eb used. The query below will find all the documents with “countries” field’s value includes any value in the array ["Italy","USA"]:
db.movieDetails.find({countries: {$in:["Italy","USA"]}}, {countries:1}).limit(10)And this is the return:
> db.movieDetails.find({countries: {$in:["Italy","USA"]}}, {countries:1}).limit(10) { "_id" : ObjectId("59e920f28eeffc9227fa418b"), "countries" :["Italy", "USA", "Spain"]} { "_id" : ObjectId("59e920f28eeffc9227fa418c"), "countries" :["USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa418d"), "countries" :["USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa418e"), "countries" :["USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4190"), "countries" :["USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4191"), "countries" :["USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4192"), "countries" :["USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4194"), "countries" :["New Zealand", "USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4195"), "countries" :["USA"]} { "_id" : ObjectId("59e920f28eeffc9227fa4196"), "countries" :["USA"]}Query Complex Objects
To query documents with complex structures, you need to take care to get exactly the data you want.
The following query finds all restaurants where the grades array contains an object whose score field contains the value 7, and returns only the name field and the score field of all the objects in the grades array.
> db.restaurants.findOne({"grades.score":7},{"name":1, "grades.score":1,"_id":0}) { "grades" : [ { "score" : 5 }, { "score" : 7 }, { "score" : 12 }, { "score" : 12 } ], "name" : "Riveria Caterer" } >Note: findOne instead of find used here, which returns one document only
Querying with Regular Expressions
Regular expression using $regex providing capabilities for pattern matching strings in queries.
This is similar to wildcards in SQL.
For example, the query below finds the names of 5 restaurants starting with ‘cafe’
db.restaurants.find({"name": {$regex: /^cafe/i }},{"name":1, "_id":0}).limit(5)Where you see a regular expression called “prefix expression”, which starts with a caret (^) or a left anchor (\A), followed by a string of simple symbols.
Option i: Case insensitivity to match upper and lower cases.
And here is the return:
> db.restaurants.find({"name": {$regex: /^cafe/i }},{"name":1, "_id":0}).limit(5) {"name" : "Cafe Metro"} {"name" : "Cafe Atelier (Art Students League)"} {"name" : "Cafe Riazor"} {"name" : "Cafe Un Deux Trois"} {"name" : "Cafe Capri"}For further details:
🔗 https://docs.mongodb.com/manual/reference/operator/query/regex/
-
Aggregation
- Aggregation operations group values from multiple documents together, and can perform a variety of operations on the grouped data to return a single result. MongoDB provides three ways to perform aggregation:
- Single purpose aggregation methods
- Aggregation pipeline
- Map-reduce function
Single purpose aggregation methods
MongoDB provides some operations to aggregate documents from a single collection, such as
db.collection.count()
This operation counts the number of documents in a collection or a view. For example, to find the number of movies with year 2009, you can run the following command and get the result:
> db.movie.find({year:2009}).count() 2db.collection.distinct ()
This operation displays the distinct values found for a specified key in a collection or a view. For example, to find the number of distinct director names:
> db.movieDetails.distinct("director").length 1870These operations provide simple access to common aggregation processes, while they lack the flexibility and capabilities of the aggregation pipeline and map-reduce function.
Aggregation Pipeline
Aggregation Pipeline is a framework for data aggregation modelled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into aggregated results.
The MongoDB aggregation pipeline consists of stages. Each stage transforms the documents as they pass through the pipeline. Pipeline stages defined with operators, such as $match, $group, and appear in an array:
>db.collection.aggregate( [ { <stage> }, ... ] )Some commonly used aggregation pipeline stage Operators are listed in the following table:
Name Description $project Reshapes each document in the stream, such as by adding new fields or removing existing fields. For each input document, outputs one document. $match Filters the document stream to allow only matching documents to pass unmodified into the next pipeline stage. $match uses standard MongoDB queries. For each input document, outputs either one document (a match) or zero documents (no match). $group Groups input documents by a specified identifier expression and applies the accumulator expression(s), if specified, to each group. Consumes all input documents and outputs one document per each distinct group. The output documents only contain the identifier field and, if specified, accumulated fields. For further details on Stage Operators, you can follow the link:
Pipeline stages do not need to produce one output document for every input document; e.g., some stages may generate new documents or filter out documents. Pipeline stages can appear multiple times in the pipeline.
Aggregation pipeline example 1: this example uses the $match operator to select documents then the $group operator to aggregate them.
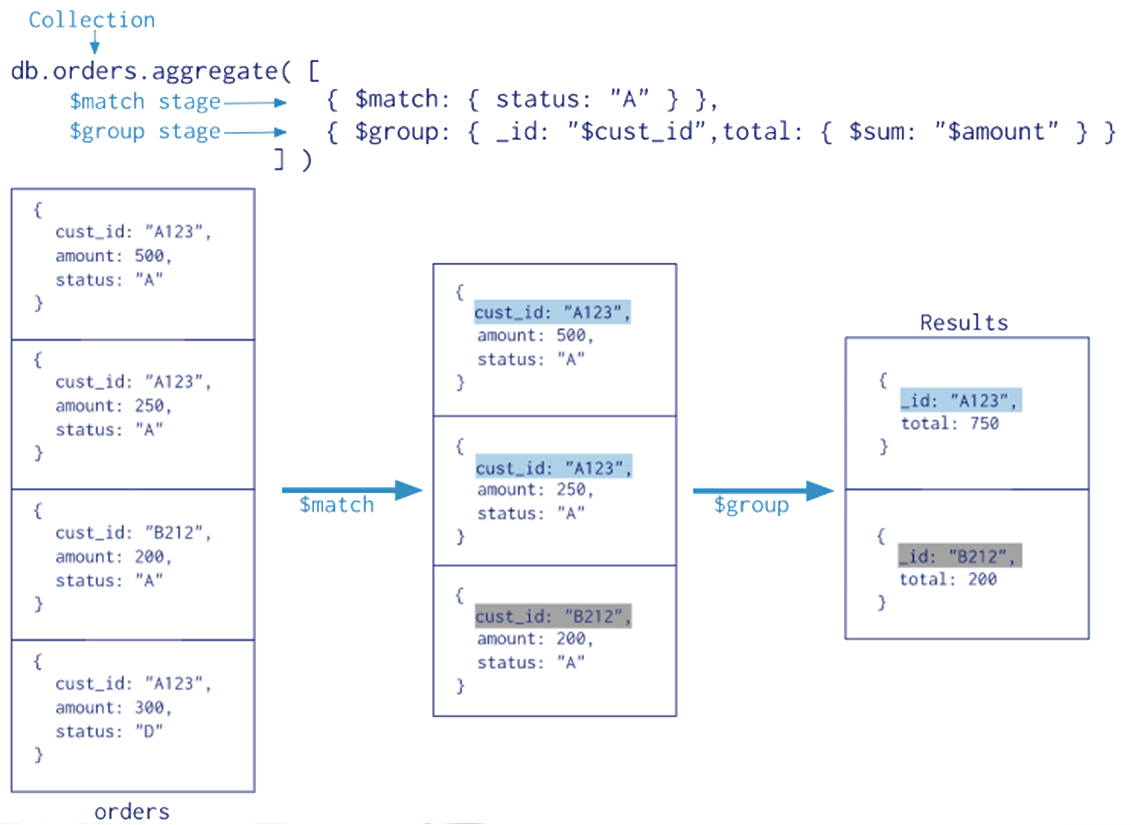
When using $group in an aggregation pipeline, each group must have an _id field. If you want to apply aggregation to all the documents, you should use null for _id.
Let us create some aggregation pipeline examples based on the following “zipcodes” collection:
Each document in the zipcodes collection has the following form:
{ "_id": "10280", "city": "NEW YORK", "state": "NY", "pop": 5574, "loc": [ -74.016323, 40.710537 ] }- The _id field holds the zip code as a string
- The city field holds the city name. A city can have more than one zip code associated with it as different section of the city can each have a different zip code.
- The state field holds the two letter state abbreviation.
- the pop field holds the population
- The loc field holds the location as a latitude longitude pair.
Example 2: An aggregation pipeline to return all states with total population greater than 10 million
db.zipcodes.aggregate( [ { $group: {_id: "$state", totalPop: { $sum: "$pop" }}}, { $match: { totalPop: { $gte: 10*1000*1000}}} ])Run this pipeline, and you will have output like below:
{"_id" : "TX", "totalPop" : 16986510} {"_id" : "IL", "totalPop" : 11430602} {"_id" : "CA", "totalPop" : 29160021} {"_id" : "OH", "totalPop" : 10847115} {"_id" : "FL", "totalPop" : 12937926} {"_id" : "NY", "totalPop" : 17990455} {"_id" : "PA", "totalPop" : 11881643}Example 3: An aggregation operation to return total population of the USA
db.zips.aggregate([ ... { $group: {_id: null, totalPop: { $sum: "$pop" }}} ... ])Execute this operation and below is the output :
{ "_id" : null, "totalPop" : 248706415 }Map-Reduce
MongoDB also provides map-reduce operations to perform aggregation, which is a data processing paradigm for condensing large volumes of data into useful aggregated results. In general, map-reduce operations have two phases: a map stage that processes each document and emits one or more objects for each input document, and reduce phase that combines the output of the map operation. Optionally, map-reduce can have a finalize stage to make final modifications to the result. For map-reduce operations, MongoDB provides the mapReduce database command.
MapReduce can return the results of a map-reduce operation as a document, or may write the results to collections. All map-reduce functions are written in JavaScript and run within the mongod process.
The example below conducts the same aggregation as example 1 in subsection 4.4.2, but using map-reduce operations:
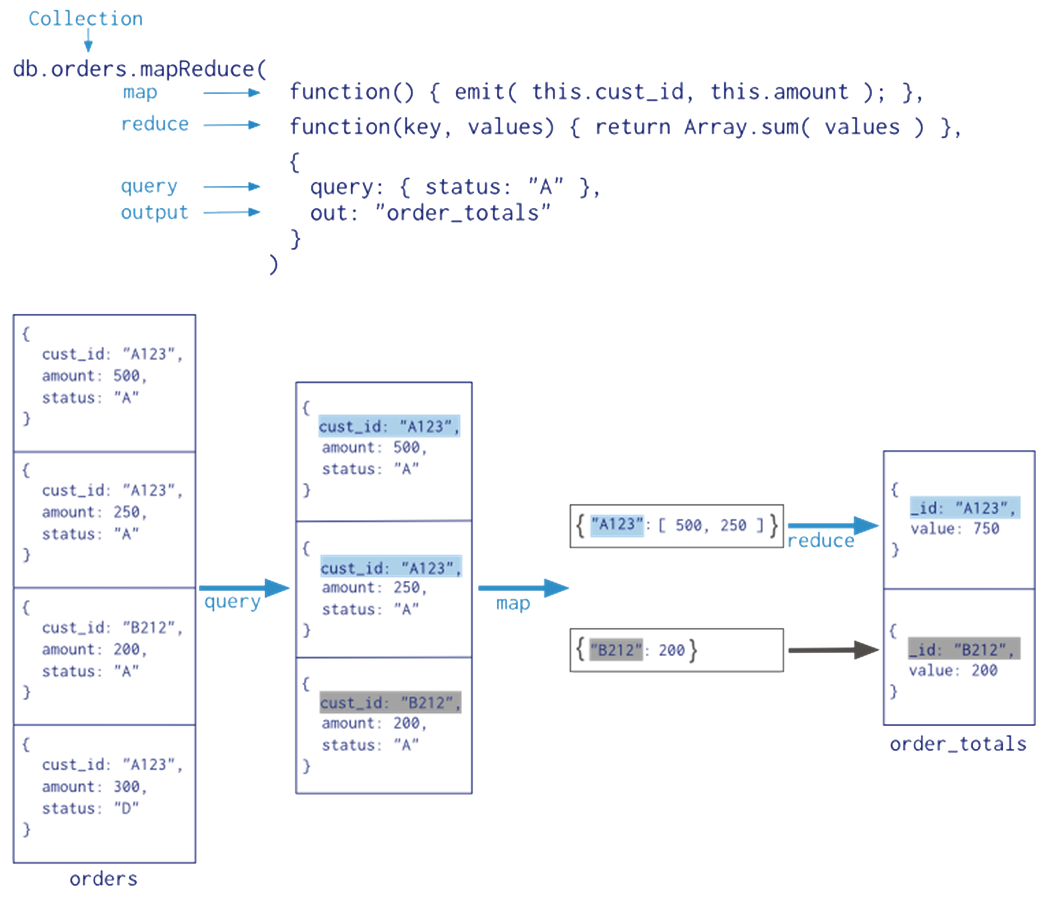
In the map-reduce operation, Query runs first to select documents to map (equivalent to $match), then Map function emits each key with the values for the amount field, finally, Reduce function sums the amounts, passed in as an array, for each key. Map and reduce together equivalent to $group
- Let’s using map-reduce function to create the aggregation operation to return the population of the all states in USA. We can define the map function and reduce function separately:
- Map function
The map function first queries the collections then maps the result documents to emit key-value pairs.
var mapFunction = function() { ... emit(this.state, this.pop); ... }; - Reduce function
These are reduced based on the keys that have multiple values.
var reduceFunction = function(keyId, valuesPops) { ... return Array.sum(valuesPops); ... };
Now we can create the mapReduce command and call the map function and reduce function in it. What listed below is the command with results outputted to the collection map_reduce_example, and its output information.
> db.zips.mapReduce( ... mapFunction, ... reduceFunction, ... { ... out: "map_reduce_example" ... } ... ) { "result" : "map_reduce_example", "timeMillis" : 239, "counts" : { "input" : 29467, "emit" : 29467, "reduce" : 348, "output" : 51 }, "ok" : 1 }As shown in the output information, in this map-reduce job, 29467 documents were emitted (number of zip codes) and 51 output after reduce (number of states).
To see the results outputted to the map_reduce_example collection, you can use find() function. In the mapReduce command below, a further query is defined to give all states with total population greater than 10 million (same as aggregation pipeline example 2 in subsection 4.4.2)
> db.zips.mapReduce( ... mapFunction, ... reduceFunction, ... { ... out: "map_reduce_example" ... } ... ).find({value: {$gt: 10000000}}) { "_id" : "CA", "value" : 29760021 } { "_id" : "FL", "value" : 12937926 } { "_id" : "IL", "value" : 11430602 } { "_id" : "NY", "value" : 17990455 } { "_id" : "OH", "value" : 10847115 } { "_id" : "PA", "value" : 11881643 } { "_id" : "TX", "value" : 16986510 }Map-reduce supports operations on sharded collections, both as an input and as an output. When using sharded collection as the input for a map-reduce operation, mongos automatically dispatch the map-reduce job to each shard in parallel.
MongoDB can shard the output collection using the _id field as the shard key. If the output collection does not exist, MongoDB creates and shards the collection on the _id field. For a new or an empty sharded collection, MongoDB uses the results of the first stage of the map-reduce operation to create the initial chunks to distribute among the shards
Map-reduce vs Aggregation Pipeline
For most aggregation operations, the Aggregation Pipeline provides better performance and more coherent interface. However, map-reduce operations provide some flexibility that is not presently available in the aggregation pipeline.
Map-reduce has high overhead, even a very simple operation on a small dataset can take in the hundreds of milliseconds, so aggregation pipeline likely to be much faster for "small" data sets. While map-reduce likely to be faster for very large data sets as operations can run largely in parallel.
Map-reduce uses JavaScript functions to define operations, so have the full power of the language available. Potentially Map-reduce can perform operations that the aggregation pipeline doesn't have operators for.
-
Further reading
🔗 https://docs.mongodb.com/manual/reference/sql-comparison/
🔗 https://docs.mongodb.com/manual/reference/operator/query/