-
Introduction
Big Data solutions often involve a pipeline in which data is transformed at each stage so that its content and form are suitable for the platform that implements the next stage. For example, streams of incoming real-time data may be aggregated and stored in an operational data store for online alerting; Data may be extracted from a relational database, transformed and stored for visualisation/business intelligence.
Big Data analytic platforms, such as Hadoop and Spark, are capable of reading data from and/or storing to a range of data storage platforms. Data storage platforms include two major types: databases and file systems. Databases include relational databases and NoSQL databases, as we discussed previously. According to where files are saved, file systems can be grouped into local, distributed and cloud-based file systems. A number of different file formats are commonly used on those file systems, e.g., Hadoop HDFS, Amazon S3 (Simple Storage Service).
-
Hadoop HDFS
Apache Hadoop
Apache Hadoop is an open source software framework that allows for distributed storage and distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Apache Hadoop software library is designed to detect and handle failures at the application layer, rather than rely on hardware (which may be prone to failure) to deliver high-availability.
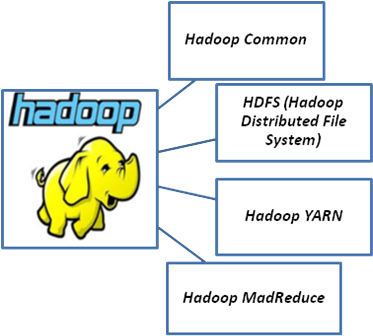
- The Apache Hadoop framework is composed of four main modules:
- Hadoop Common
The common utilities that support the other Hadoop modules. - Hadoop Distributed File System (HDFS)
A distributed file-system that stores data on the commodity machines, providing high-throughput access to application data. - Hadoop YARN
A framework for job scheduling and cluster resource management - Hadoop MapReduce
A YARN-based system for parallel processing of large data sets
Beyond HDFS, YARN and MapReduce, the entire Apache Hadoop platform is now commonly considered to consist of a number of related projects as well: Apache Pig, Apache Hive, Apache HBase, and others.
HDFS introduction
HDFS (Hadoop Distributed File System) is the primary distributed storage used by Hadoop applications. It is structured similarly to a regular Unix file system except that data storage is distributed across several machines (using commodity hardware) in an HDFS cluster. It is not intended as a replacement to a regular file system, but rather as a file system like layer for large distributed systems.
HDFS is highly fault-tolerant. It has built-in mechanisms to handle machine outages. HDFS is optimized for non-real time applications demanding high throughput rather than online applications demanding low latency: it provides high throughput access to application data and is suitable for applications that have large data sets. Using HDFS, throughput scales almost linearly with the number of datanodes in a cluster, so it can handle workloads no single machine would ever be able to.
Data saved in HDFS can be accessed using either the Java API (Hadoop is written in Java), or the Hadoop command line client. Many operations are similar to their Unix counterparts.
HDFS applications need a write-once-read-many access model for files. A file once created, written, and closed need not be changed except for appends and truncates. Appending the content to the end of the files is supported but cannot be updated at arbitrary point. This assumption simplifies data coherency issues and enables high throughput data access.
- HDFS has unique features that make it ideal for distributed systems:
- Highly fault tolerant
- Scalable - read/write capacity scales fairly well with the number of datanodes
- Industry standard - Lots of other distributed applications build on top of HDFS (HBase, Map-Reduce, Spark)
- Pairs well with MapReduce
HDFS Architecture
HDFS follows the master/slave architecture. An HDFS cluster consists of a single NameNode and a number of DataNodes. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes.
A NameNode is a master server that manages the file system namespace and regulates access to files by clients. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes.
Usually there is one DataNode per node in the cluster, which manage storage attached to the nodes that they run on. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
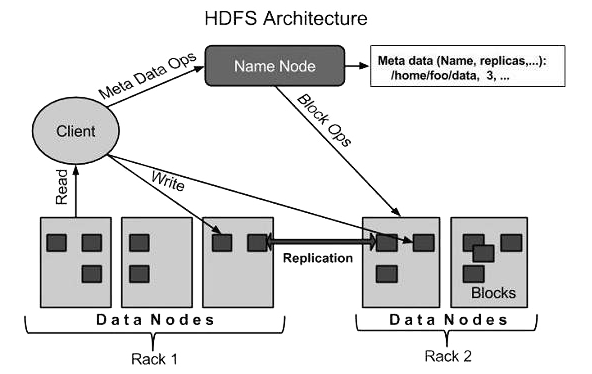
HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories. The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from one directory to another, or rename a file.
The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode. An application can specify the number of replicas of a file that should be maintained by HDFS - the number of copies of a file is called the replication factor of that file and this information is stored by the NameNode.
HDFS Operations
- Starting HDFS
Initially, format the configured HDFS file system, open NameNode (HDFS server), and execute the following command.$ hadoop namenode -format
Then, using the following command to start the NameNode as well as the data nodes as cluster.
$ start-dfs.sh
- List Files in HDFS
After loading the information in the server, we can find the list of files in a directory, status of a file, using ‘ls’ as below:$ hadoop fs -ls <args>
- Inserting Data into HDFS
Assume you have a local data file called Lfile.txt and want to save it in the hdfs file system. First, you need to create an input directory, e.g. /user/input$ hadoop fs -mkdir /user/input
Then, transfer and store your data file from local systems (e.g., /home/Lfile.txt ) to the Hadoop file system using the ‘put’ command.$ hadoop fs -put /home/Lfile.txt /user/input
You can verify the file using ‘ls’ command.$ hadoop fs -ls /user/input
- Retrieving Data from HDFS
Assume you want to retrieve a file in HDFS called Hfile. You can view the data from HDFS using ‘cat’ command.$ hadoop fs -cat /user/output/Hfile
Get the file from HDFS to the local file system using ‘get’ command.$ hadoop fs -get /user/output/ /home/hadoop_tp/
- Shutting Down the HDFS
HDFS can be shut down usng the following command:
$ stop-dfs.sh
-
Amazon S3
Amazon S3 (Simple Storage Service) is a cloud-based object storage accessed through web services interfaces, which can be used to store and retrieve any amount of data, at any time, from anywhere on the web. It gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites.
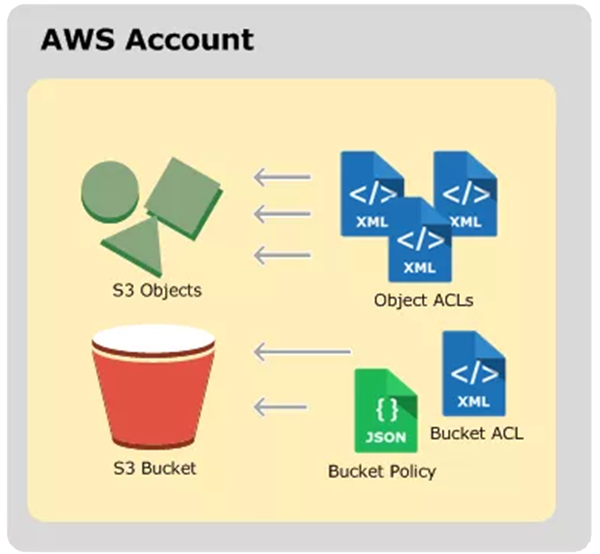
Data in S3 is stored as objects within buckets, and identified within each bucket by a unique, user-assigned key: essentially S3 is a key-value store. A S3 object consists of a file and optionally any metadata that describes that file.
S3 Buckets are the containers for objects. You can have one or more buckets. For each bucket, you can control access to it (who can create, delete, and list objects in the bucket), view access logs for it and its objects, and choose the geographical region where Amazon S3 will store the bucket and its contents.
To use Amazon S3, you need an AWS account. Then you can create a bucket using the AWS Management Console. To store an object in Amazon S3, you upload the file you want to store to a bucket.
Hadoop can use S3 as a file system to store files of any type - S3 Native FileSystem or S3A (a successor to the S3 Native). The advantage of this is that you can access files on S3 that were written with other tools and other tools can access files written using Hadoop.
For example: to access a file on S3 (folder dir1 in bucket1) using Hadoop filesystem shell
hadoop fs -ls s3a://bucket1/dir1
(Note, AWS credentials must be configured in Hadoop)
-
File formats on HDFS
- Theoretically, like other file systems the format of the files you can store on HDFS is entirely up to you. However, unlike a regular file system, HDFS is best used in conjunction with a data processing toolchain like MapReduce or Spark. You need to choose file type and format carefully when using HDFS to take advantage of the distributed nature of the filesystem and analytic processing that runs on top of it. There are three main factors to consider:
- Splittability
It is better to use a file format that is splittable. HDFS stores large files in blocks (and files in Big Data usually are large), and wants to be able to start reading at any point in the file to to take fullest advantage of Hadoop’s distributed processing. - Compression
Compressed files are smaller so better for I/O throughput and storage, but this will bring up processing overhead. Since Hadoop stores large files by splitting them into blocks, its best if the blocks can be independently compressed. Otherwise decompressor will have to start at the beginning of a compressed file to access any block. - Schema evolution
You may want to be able to add a field and still read historical data, therefore, it is better to use file formats that enable flexible and evolving schema.
- Main file formats supported by Hadoop include:
- Text files
- CSV files
- JSON records
- Sequence files
- Apache Avro
- Columnar file storage
- ORC format
- Apache Parquet
Text files - XML, JSON
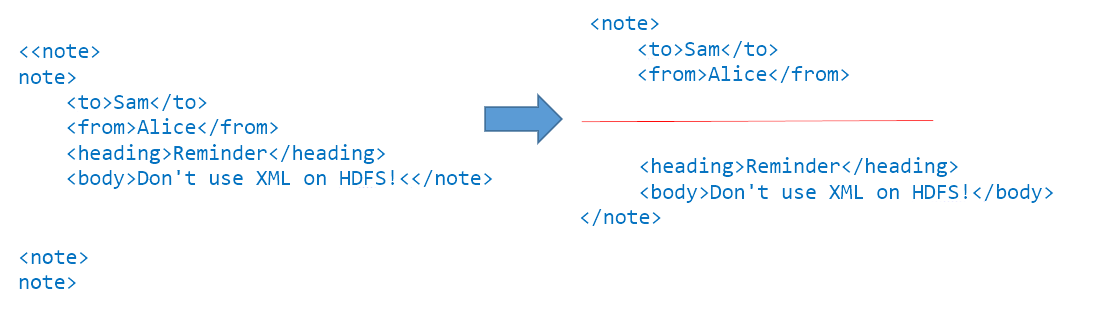
Text files in XML or JSON format are commonly received by Hadoop developer and data scientist to work upon. Those file format should be avoided as these are not splittable. They are structured so that start and finish of an element may be on separate lines. Splitting the file in between would lead to unusable data in each block.
In example below, valid XML document is split into two blocks, but each of these can't be processed as it doesn't contain a valid document.
CSV files
CSV files are useful for exchanging data between systems, e.g. when doing a dump from a database or bulk loading data from HDFS into an analytic database. They are readable and ubiquitously parsable. However, CSV files do not support block compression, thus compressing a CSV file in Hadoop often comes at a significant read performance cost.
To support splittability, when working with CSV files on HDFS, never include header or footer lines, each line of the file should contain a record.
There is no metadata stored with the CSV file, so you must know how the file was written in order to make use of it. CSV file structure is dependent on field order, new fields can only be appended at the end of records while existing fields can never be deleted. Overall, CSV files have limited support for schema evolution.
JSON records
JSON records are different from JSON files in that each line is its own JSON object that is separate from those on other lines, which makes the files splittable. For example:
{'name': 'Alice', 'location': {'city': 'LA', 'state': 'CA'}} {'name': 'Sam', 'location': {'city': 'NYC', 'state': 'NY'}}JSON records store metadata with the data, which fully enabling schema evolution. However, like CSV files, JSON files do not support block compression.
Sequence files
Sequence file format is a Hadoop-specific format. Sequence files store data in a binary format as binary key-value pairs.
Sequence files can be compressed at different levels - record or block. Blocks in a sequence file are marked with sync markers for splittability.
Sequence files do not store metadata with the data, so the only schema evolution option is appending new fields.
There is only a Java API for working with sequence files. Due to the complexity of reading sequence files, they are often only used for “in flight” data such as intermediate data storage used within a sequence of MapReduce jobs.
-
File formats on HDFS cont...
Apache Avro
Apache Avro is a language-neutral data serialisation system, not just a file format. It stores data in a compact, fast, binary data format:
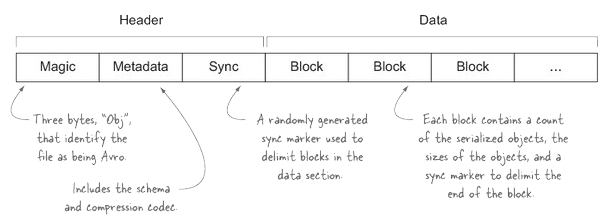
Apache Avro file structure like sequence files, Avro files use sync markers for splittability and support block compression. Avro files store metadata with the data but also allow specification of an independent schema for reading the file.
{ "namespace": "example.avro", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}, {"name": "favorite_color", "type": ["string", "null"]} ] }An example Apache Avro schema
Avro file format provides very good schema evolution support since you can rename, add, delete and change the data types of fields by defining new independent schema. Schema used to read an Avro file need not be same as schema which was used to write the files.
Columnar file storage
Most data storage is row oriented: contents of a row are stored contiguously, followed by the next row, and so on. There may be many columns in a row.
Columnar storage stores contents of a column contiguously. With this kind of data storage, you can get much better read performance if you are only reading from a small number of columns. Writing a Columnar storage requires more memory and computation, and is generally slower than row-oriented storage.
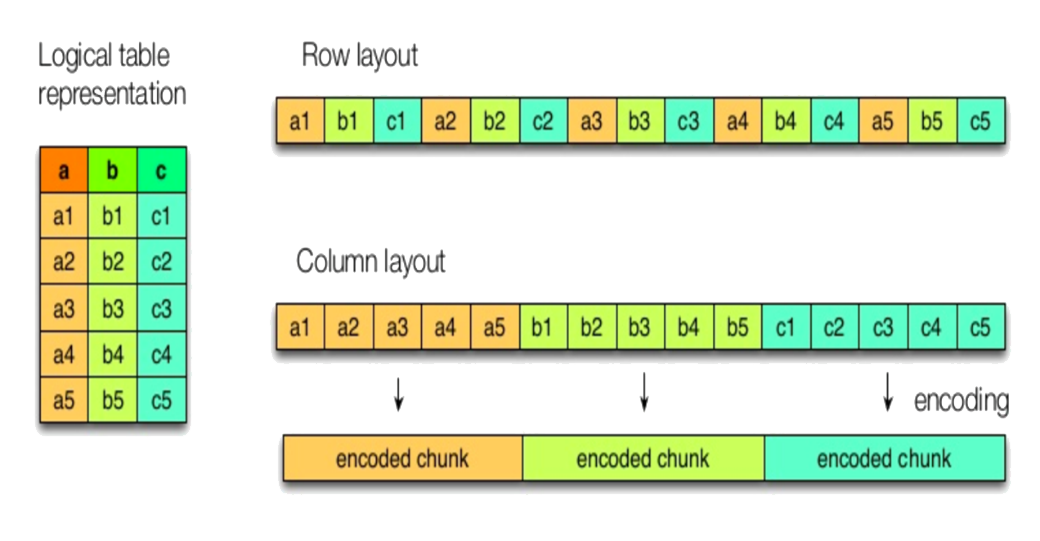
Column-oriented storage is useful for data that has been processed in preparation for analytic workloads.
RC Files (Record Columnar Files) were the first columnar file format adopted in Hadoop.
ORC format
ORC (Optimised RC) format is a successor to the RC (Record Columnar) file format.
RC Files were the first columnar file format adopted in Hadoop. RC file format was developed specifically to provide efficient processing for MapReduce applications; to provide fast data loading, fast query processing, and highly efficient storage space utilization. RC file format breaks files into row splits, then within each split uses column-oriented storage. RC files enjoy significant compression and query performance benefits. However, the current serdes for RC files in Hive and other tools do not support schema evolution.
ORC is the compressed version of RC file and supports all the benefits of RC file with some enhancements like ORC files compress better than RC files, enabling faster queries. However, ORC files still don’t support schema evolution.
ORC File format is not general purpose as it was invented to optimize performance in Hive.
Apache Parquet
Parquet shares many of the same design goals as ORC, but is intended to be a general-purpose storage format for Hadoop. Apache Parquet is another columnar binary file format. Unlike RC/ORC, it supports limited schema evolution. It is designed to support complex nested data structures.
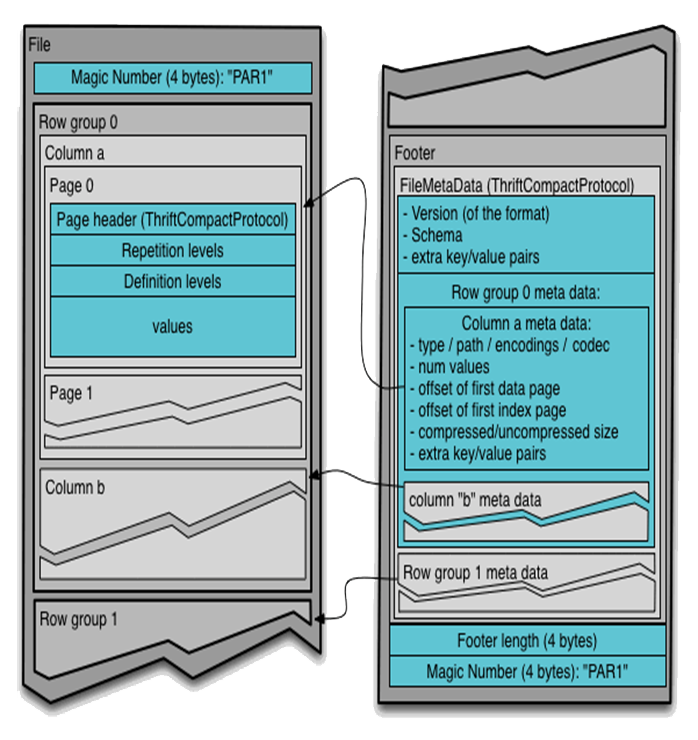
Parquet files are self-documenting via storing full metadata at the end of files. Parquet files can be read and written using Avro APIs and Avro schemas.
An example of reading and writing the Apache Parquet file in Python is given below.
import numpy as np import pandas as pd import pyarrow as pa df = pd.DataFrame({'one': [-1, np.nan, 2.5],... 'two': ['foo', 'bar', 'baz'], ... 'three': [True, False, True]}) table = pa.Table.from_pandas(df) # Obtaining PyArrow with parquet Support import pyarrow.parquet as pq # We write this to Parquet format pq.write_table(table, 'example.parquet') # Read single file back table2 = pq.read_table('example.parquet') table2.to_pandas()Output of this example script is:
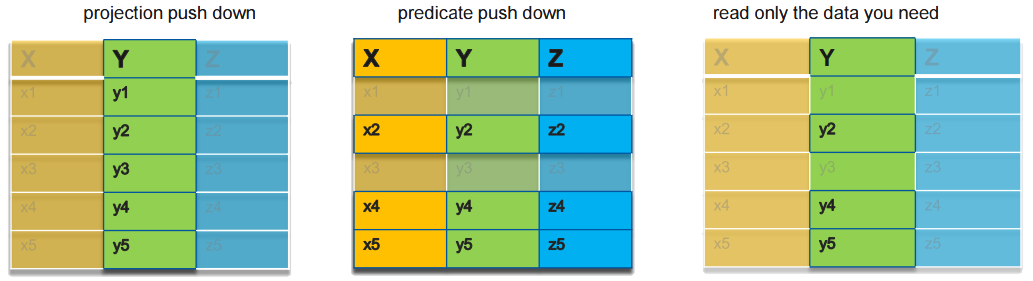
one three two 0 -0.1 True foo 1 NAN False bar 2 2.5 True bazAn analytic engine such as Spark will often query using projection (selecting columns) and predicates (selecting rows according to criteria). Databases generally apply these filters at the time of reading from disk, which is more efficient than reading the whole data set into memory and filtering there. This is known as pushdown - projection and predicate pushdown. Columnar formats such as Parquet support pushdown when reading from files.
-
Further reading
🔗 https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
🔗 https://docs.databricks.com/spark/latest/data-sources/index.html