-
Processing Frameworks/Engines
Data processing frameworks and processing engines are responsible for computing over data in a data system, to increase understanding, surface patterns, and gain insight into complex interactions. Data processing engines are the actual component responsible for operating on data. And Data processing frameworks can be defined as a set of components designed to do the operation on data. While, from another point of view, there is no authoritative definition setting apart "engines" from "frameworks”: engines and frameworks can often be swapped out or used in tandem.
Apache Hadoop can be considered a processing framework with MapReduce as its default processing engine. Apache Spark, another framework, can hook into Hadoop to replace MapReduce.
- There are many Big Data techniques that can be used to store data, to increase the speed of processing and to analyse the data. There are also a number of data processing systems that can process Big Data in real-time or near real-time, which include the following top 5 Apache Big Data Processing Frameworks:
- Apache Hadoop
- Apache Spark
- Apache Storm
- Apache Samza
- Apache Flink
-
Types of big data frameworks
- Big data processing frameworks can be grouped into three types by the state of the data they are designed to handle:
- Batch-only frameworks
e.g. Apache Hadoop - Stream-only frameworks
e.g. Apache Storm, Apache Samza - Hybrid frameworks
e.g. Apache Spark (mainly batch processing, can do a good job emulating near-real-time processing via very short batch intervals), Apache Flink (real-time-first processing)
Batch-only frameworks
Batch processing involves operating over a large, static dataset and returning the result at a later time when the computation is complete.
- The datasets in batch processing are typically:
- bounded: batch datasets represent a finite collection of data
- persistent: data is almost always backed by some type of permanent storage
- large: batch operations are often the only option for processing extremely large sets of data
Batch processing is well-suited for calculations where access to a complete set of records is required, e.g., calculating totals and averages. Tasks that require very large volumes of data are often best handled by batch operations.
Batch processing is not appropriate in situations where processing time is especially significant.
Stream-only frameworks
- Stream processing systems compute over data as it enters the system. The datasets in stream processing are considered "unbounded":
- The total dataset is only defined as the amount of data that has entered the system so far.
- The working dataset is perhaps more relevant, and is limited to a single item at a time.
- Stream processing is event-based and does not "end" until explicitly stopped.
- Results in stream processing are immediately available and will be continually updated as new data arrives.
Stream processing systems can handle a nearly unlimited amount of data, but they only process one (true stream processing) or very few (micro-batch processing) items at a time, with minimal state being maintained in between records. Steam processing is highly optimized for more functional processing with few side effects.
Processing with near real-time requirements is well served by the streaming model.
Hybrid frameworks
Hybrid frameworks can handle both batch and stream workloads. These frameworks simplify diverse processing requirements by allowing the same or related components and APIs to be used for both types of data.
Hybrid frameworks attempt to offer a general solution for data processing.
-
Apache Hadoop
Apache Hadoop is currently the most common single Big Data platform, and almost become synonymous with Big Data. However, still other techniques play a role in the scene.
Hadoop Ecosystem provides an integrated environment for Big Data, which includes a set of tools that function near MapReduce and HDFS (the two main Hadoop core components) and help the two store and manage data, as well as perform the analytic tasks. There is an increasing number of new technologies that encircle Hadoop, it is important to realize that certain products maybe more appropriate to fulfil certain requirements than others.
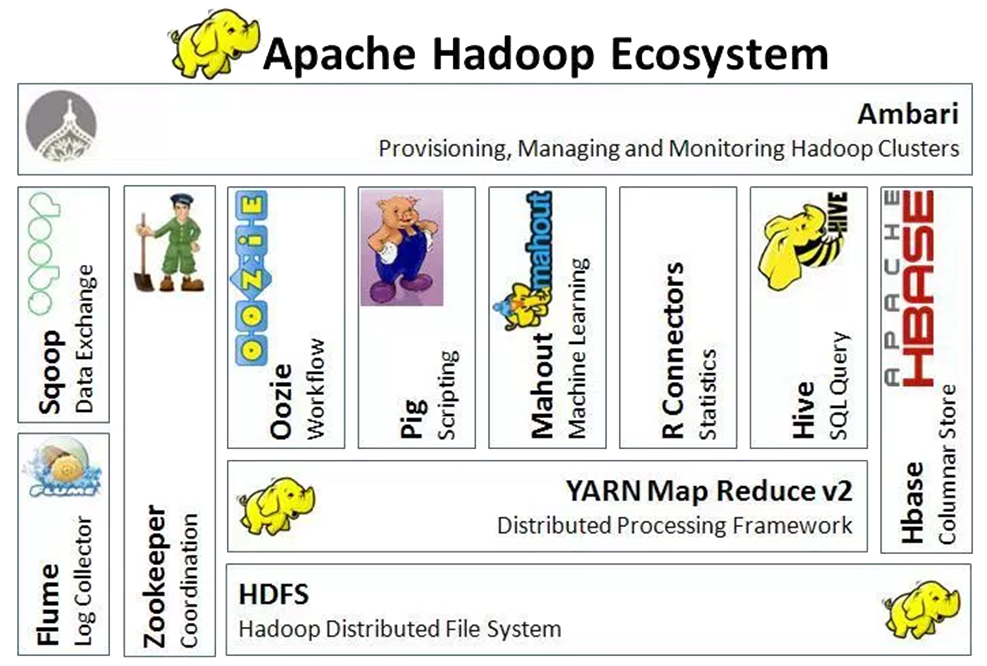
The two major core technologies of Hadoop are HDFS (where data are stored) and MapReduce (a paradigm to process data).
HDFS (Hadoop Distributed File System) is a reliable distributed file system with a fault tolerance mechanism to store large datasets and provide high-throughput access to data. In HDFS, data files are broken into blocks and are distributed over the servers. HDFS is designed to run on several clusters and to be resilient to failures since it makes several copies of its data blocks.
MapReduce is the first programming method to develop applications in Hadoop. It provides a framework for performing high performance distributed data processing. MapReduce comprises of two programs written in java: Mappers, to extract data from HDFS and put into maps, and Reducers to aggregate the results produced by the mappers.
- Other main technologies in Hadoop ecosystem includes:
- Apache Mahout – a distributed linear algebra framework for creating scalable performant Machine Learning applications.
- Pig - a platform for analysing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs.
- Apache Flume - a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data into HDFS.
- Sqoop (SQL to Hadoop) - a connectivity tool designed for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases and data warehouses.
Hadoop Architecture
Hadoop has a master/slave architecture for both storage and processing.
1. HDFS architecture
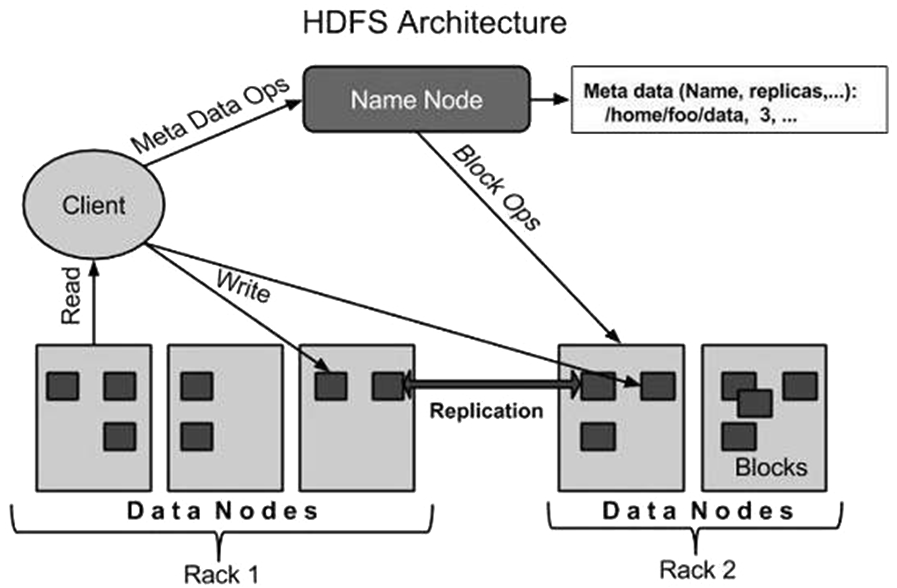
- An HDFS cluster consists of a single NameNode and a number of DataNodes.
- NameNode - master server
The Namenode in an HDFS cluster manages the file system namespace and regulates client’s access to files; executes file system namespace operations like opening, closing, and renaming files; and directories and determines the mapping of blocks to DataNodes. - DataNode - usually for every node in a cluster, there is a Datanode
Datenodes in an HDFS cluster manage storage attached to the nodes that they run on; serve read and write requests from the file system’s clients, and perform block creation, deletion, and replication upon instruction from the NameNode
HDFS is highly failure tolerant and highly available. HDFS divides data into blocks and creates multiple copies of blocks on different machines in the cluster. if any machine in the cluster goes down, a client can easily access their data from the other machine which contains the same copy of data blocks.
HDFS is scalable. HDFS stores data on multiple nodes in the cluster, when requirements increase we can scale the cluster either vertically or horizontally. The vertical scalability is achieved by adding more resources (CPU, Memory, Disk) on the existing nodes of the cluster. The horizontal scalability is done by adding more machines in the cluster.
HDFS pairs well with MapReduce and is a generally accepted industry standard. Lots of other distributed applications build on top of HDFS, e.g., HBase, Map-Reduce, Spark, etc.
2. MapReduce architecture
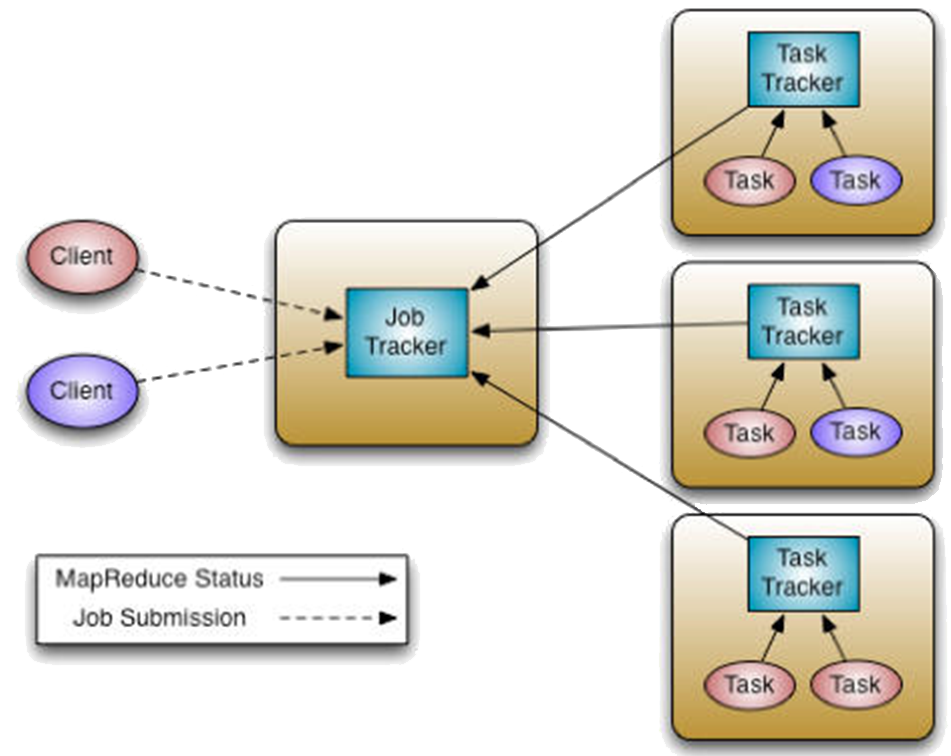
A MapReduce engine consists of one JobTracker and a number of TaskTrackers.
A JobTracker is the master of a MapReduce engine which manages the jobs and resources in the cluster. The job tracker tries to schedule each map as close to the actual data being processes, i.e. on the task tracker which is running on the same datanode as the underlying block. If the work cannot be hosted on the actual node where the data resides, priority is given to nodes in the same rack. If a TaskTracker fails or times out, that part of the job is rescheduled.
TaskTrackers are the slaves which are deployed on each machine. They are responsible for running the map and reduce tasks as instructured by the Jobtracker.
Hadoop Environment
- Hadoop can be configured in three modes:
- Standalone mode
Default mode of Hadoop. It uses local file system for input and output operations. This mode is mainly used for debugging purpose, and it does not support the use of HDFS. - Pseudo-Distributed Mode (Single Node Cluster)
In this mode, each Hadoop deamons runs in different JVM, as a separate process, but all processes running on a single machine. - Fully Distributed Mode (Multiple Cluster Node)
This is the production phase of Hadoop (what Hadoop is known for) where data is used and distributed across several nodes on a Hadoop cluster. Separate nodes are allotted as Master and Slave.
Apache Hadoop and its MapReduce processing engine offer a well-tested batch processing model that is best suited for handling very large data sets where time is not a significant factor.
If your data can be processed in batch, and split into smaller processing jobs, spread across a cluster, and their efforts recombined, all in a logical manner, Hadoop will probably work just fine for you.
A number of tools in the Hadoop ecosystem are useful far beyond supporting the original MapReduce algorithm that Hadoop started as. Of particular note, and of a foreshadowing nature, is YARN, the resource management layer for the Apache Hadoop ecosystem. It can be used by systems beyond Hadoop, including Apache Spark.
-
Apache Spark
Apache Spark is a lightning-fast unified analytics engine for big data and machine learning. It was originally developed at UC Berkeley in 2009. With over 1000 contributors from 250+ organizations, Apache Spark project is the most active project listed by the ASF (Apache software Foundation) under the “Big Data” category.
Apache Spark is the heir apparent to the Big Data processing kingdom. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. Apache Spark provides a next generation batch processing framework with stream processing capabilities.
Apache Spark is based on in-memory computation, which is a big advantage of Apache Spark over several other big data Frameworks. Apache Spark can run tasks up to 100 times faster, when it utilizes the in-memory computations and 10 times faster when it uses disk than traditional map-reduce tasks. In Hadoop, tasks are distributed among the nodes of a cluster, which in turn save data on disk. When that data is required for processing, each node has to load the data from the disk and save the data into disk after performing operation.
Spark Ecosystem
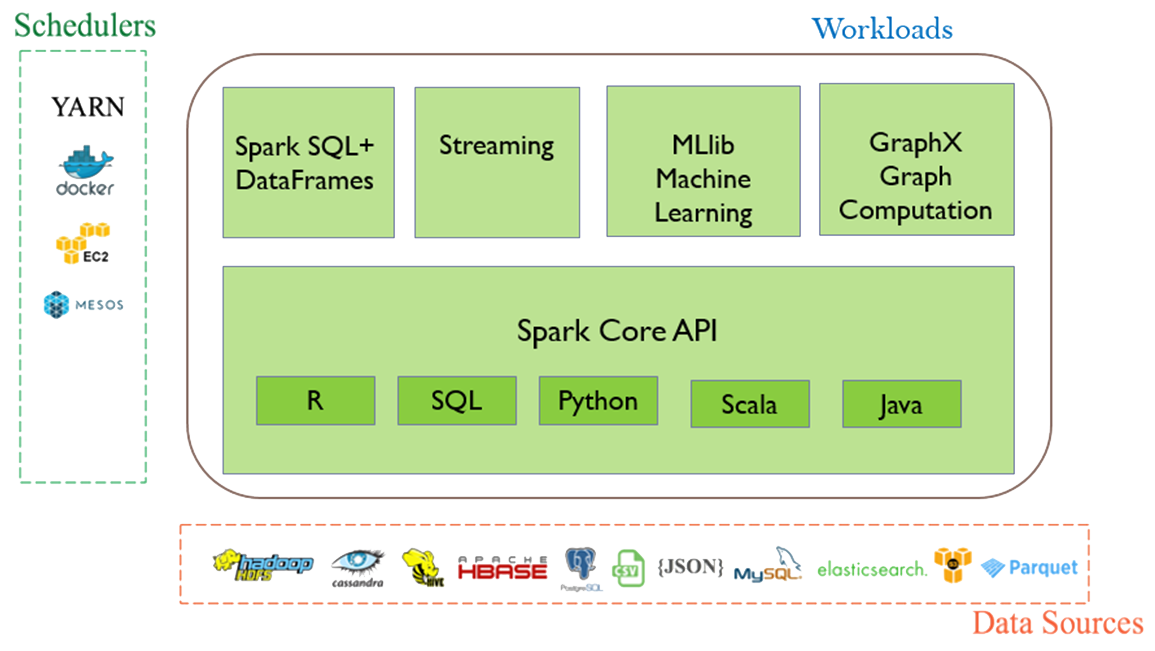
- There are 5 major components in Apache Spark Ecosystem: Spark Core, Spark SQL+, Spark Streaming, Spark MLlib, and Spark GraphX. Let us now learn about these Apache Spark ecosystem components in details below.
- Spark Core
Spark core is the underlying general execution engine for the Spark platform. All the functionalities being provided by Apache Spark are built on the top of Spark core. Spark core provides in-memory computing capabilities. It supports Java, Scala, and Python APIs for ease of development.
Spark Core makes use of a special data structure known as RDD (Resilient Distributed Datasets). Spark RDD handles partitioning data across all the nodes in a cluster. It holds them in the memory pool of the cluster as a single unit. - Spark SQL
Spark SQL, originally known as Shark, is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as distributed SQL query engine. Alongside standard SQL support, Spark SQL provides a standard interface for reading from and writing to other data stores including JSON, HDFS, Apache Hive, JDBC, Apache ORC, and Apache Parquet. Spark SQL eases the process of extracting and merging various datasets so that the datasets are ready to use for machine learning.
Behind the scenes, Apache Spark uses a query optimizer called Catalyst that examines data and queries in order to produce an efficient query plan for data locality and computation that will perform the required calculations across the cluster. - Spark streaming
Spark streaming enables powerful interactive and analytical applications across both streaming and historical data, while inheriting Spark’s ease of use and fault tolerance characteristics. Data in Spark Streaming is ingested from various data sources and live streams like Twitter, Apache Kafka, Akka Actors, IoT Sensors, Amazon Kinesis, Apache Flume, etc.
Spark Streaming extended the Apache Spark concept of batch processing into streaming by breaking the stream down into a continuous series of microbatches, which could then be manipulated using the Apache Spark API. In this way, code in batch and streaming operations can share (mostly) the same code, running on the same framework, thus reducing both developer and operator overhead. - MLlib
MLlib is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. It delivers both high-quality algorithms (e.g., multiple iterations to increase accuracy) and blazing speed (up to 100x faster than MapReduce).
Spark MLlib covers basic machine learning including classification, regression, clustering, and filtering. It is a low-level machine learning library that can be called from Scala, Python and Java as part of Spark applications - GraphX
GraphX is a graph computation engine. It provides a selection of distributed algorithms for processing graph structures. It enables users to interactively build, transform and reason about graph structured data at scale. It comes complete with a library of common algorithms.
Schedulers (cluster managers)
- When running on a cluster, each Spark application gets an independent set of executor JVMs that only run tasks and store data for that application. If multiple users need to share your cluster, there are different options to manage allocation, depending on the cluster manager (or scheduler). Spark has its own standalone cluster manager, but real-world applications are typically built on other widely-used cluster managers, such as, Apache YARN, MESOS, etc.
- Standalone mode
By default, applications submitted to the standalone mode cluster will run in FIFO (first-in-first-out) order, and each application will try to use all available nodes. You can limit the number of nodes an application uses or change the default for applications - Apache YARN (Yet Another Resource Negotiator)
Hadoop originally included scheduling as part of Map-Reduce. Hadoop 2 decouples MapReduce's resource management and scheduling capabilities, as YARN, from the data processing component. YARN supports more varied processing approaches and a broader array of applications on Hadoop clusters, including Spark. - Apache Mesos
Apache Mesos sits between the application layer and the operating system and makes it easier to deploy and manage applications in large-scale clustered environments more efficiently. Both static partition of resources and dynamic sharing of CPU course are available on Mesos.
In the dynamic sharing mode, each Spark application still has a fixed and independent memory allocation, but when the application is not running tasks on a machine, other applications may run tasks on those cores. This mode is useful when you expect large numbers of not overly active applications, such as shell sessions from separate users. However, it comes with a risk of less predictable latency, because it may take a while for an application to gain back cores on one node when it has work to do.
Components in cluster mode
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program, i.e., driver program (Python, Scala, Java, R). SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN), which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
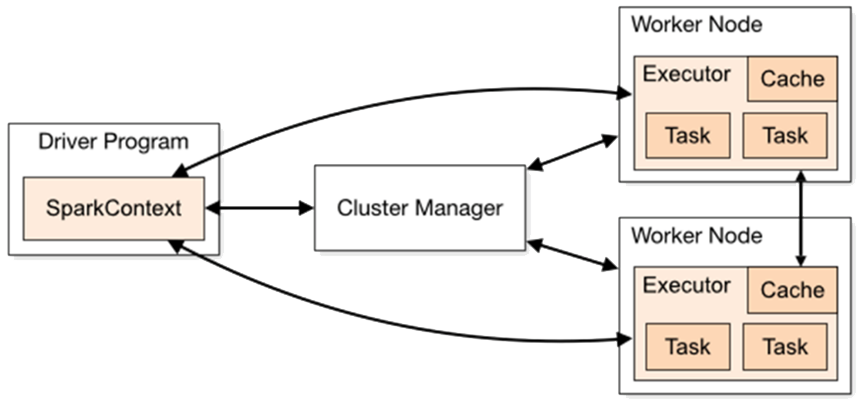
Each Spark application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. Data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
Spark is agnostic to the underlying cluster manager. The driver program must listen for and accept incoming connections from its executors throughout its lifetime. Because the driver schedules tasks on the cluster, it should be run close to the worker nodes, preferably on the same local area network.
-
Apache Spark cont...
Resilient Distributed Datasets (RDDs)
RDD is the primary data abstraction in Apache Spark and the core of Spark. You can write programs in terms of operations on RDDs. Each dataset in RDD is divided into one or many logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
Spark makes use of the concept of RDD to achieve faster and efficient MapReduce operations. The original paper of RDD:
🔗 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing by Matei Zaharia, et al., 2012
Both Iterative and Interactive applications require faster data sharing across parallel jobs. Data sharing is slow in MapReduce due to replication, serialization, and disk IO. Regarding storage system, most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operations.
- RDD supports in-memory processing computation. This means, it stores the state of memory as an object across the jobs and the object is sharable between those jobs. Data sharing in memory is 10 to 100 times faster than network and Disk.
- Iterative Operations on Spark RDD
The illustration given below shows the iterative operations on Spark RDD. It stores intermediate results (State of the Job) in a distributed memory (RAM) instead of Stable storage (Disk) and make the system faster. While if the distributed memory is not sufficient to store intermediate results, RDD will store those results on the disk.
- Interactive Operations on Spark RDD
The figure below shows interactive operations on Spark RDD. If different queries are run on the same set of data repeatedly, this particular data can be kept in memory for better execution times.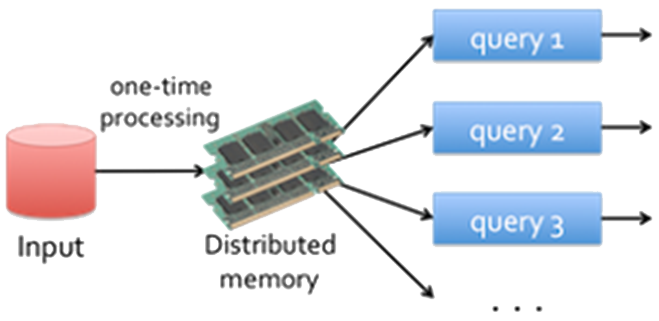
There are two ways to create RDDs: parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
There are various types of RDDs, including 3rd party types, and you can write your own. These are typically created as a result of calling methods or applying transformations to other RDDs.
Spark RDD Operations
Apache Spark RDD supports two types of operations: Transformations and Actions. A Transformations are kind of operations which will transform your RDD data from one form to another. When you apply a transformation on any RDD, you will get a new RDD with transformed data. The so input RDDS, cannot be changed since RDDs in Spark are immutable.
However, transformations are lazy in nature - they are not computed immediately. Two most basic type of transformations is a map(), filter(). After the transformation, the resultant RDD is always different from its parent RDD, although it can be smaller, bigger or the same size.
An action will trigger all the lined up transformations on the base RDD and then execute the action operation on the last RDD. Operations persist (cache) distributed data in memory or disk. When the action is triggered after the result, new RDD is not formed like transformation. Thus, Actions are Spark RDD operations that give non-RDD values.
Running a Spark job
A Spark job is defined by a piece of code which reads some input from HDFS or local, performs some computation on the data and writes some output data. Spark Jobs are divided into stages which are classified as map or reduce stages and are divided based on computational boundaries. Each stage has some tasks, one task per partition - one task is executed on one partition of data on one executor (machine).
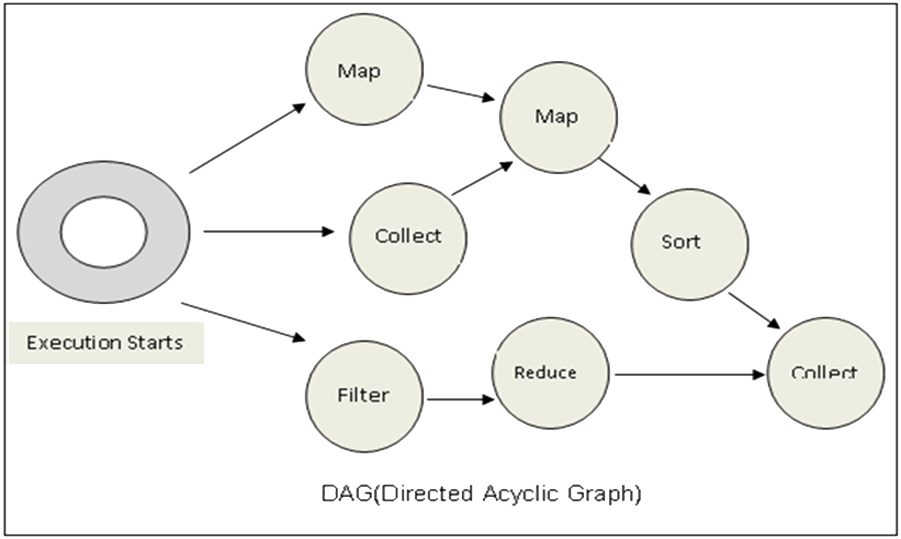
A job comprises a series of operators (transformations/actions) and run on a set of data. All the operators in a job are used to construct a DAG (Directed Acyclic Graph).
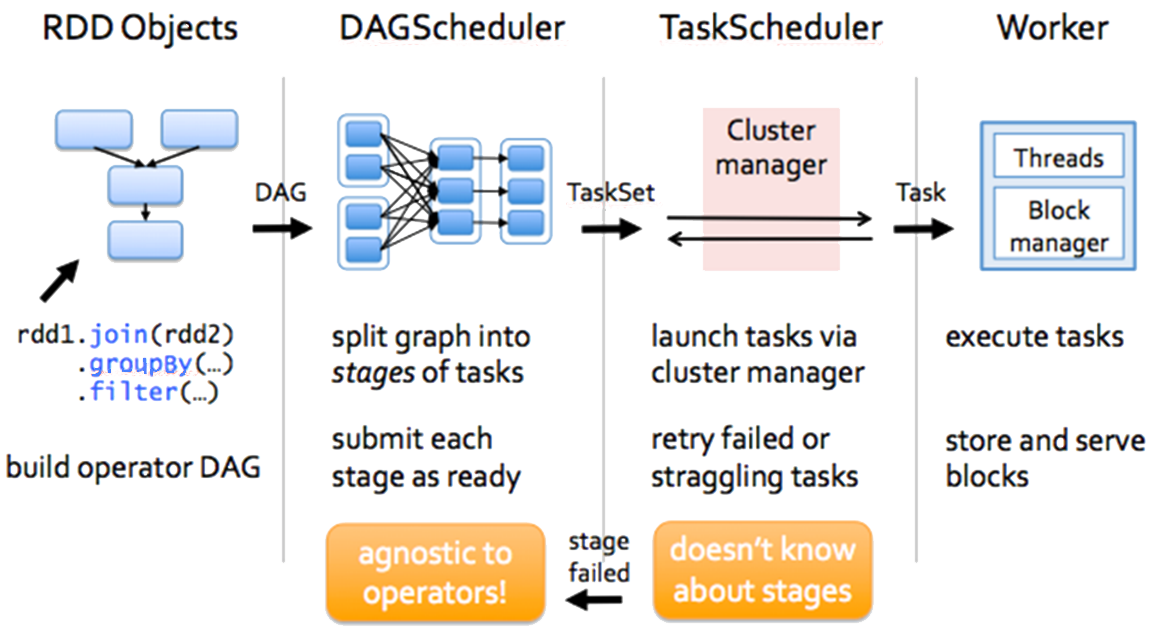
DAGs and optimisation
A DAG (Directed Acyclic Graph) in Apache Spark represents all operations in a job. A DAG is a finite direct graph with no directed cycles. It includes a set of Vertices and Edges (as illustrated in the example below), where vertices represent the RDDs and the edges represent the Operation to be applied on RDD. In Spark DAG, every edge directs from earlier to later in the sequence. On the calling of Action, the created DAG submits to DAG Scheduler which further splits the graph into the stages of the task. Spark DAG is a strict generalization of MapReduce model.
A DAG can be optimized by rearranging and combining operators where possible. The DAG optimizer rearranges the order of operators to maintain the number of records of further operations. For instance, let’s assume that you have to submit a Spark job which contains a map operation followed by a filter operation. Spark DAG optimizer would rearrange the order of these operators, as filtering would reduce the number of records to undergo map operation.
DataBricks
Apache Spark provides a unified framework for building data pipelines. Databricks takes this further by providing a zero-management cloud platform built around Spark. Databricks offers a web-based platform for working with Spark in the cloud. It provides automated cluster management which makes it very easy to create a cluster with no need to install/configure Hadoop/Spark. Databricks is a Unified Analytics Platform on top of Apache Spark that accelerates innovation by unifying data science, engineering and business.
Databricks provides IPython style notebooks for working interactively with Spark. It is useful for learning, data science exploration and prototyping for driver programs. A notebook is attached to a cluster - limited to a single node in the Community edition, but scalable on demand in paid versions
Spark 2
Spark is evolving rapidly, with version 2.4.0 released recently. There are some significant changes to some APIs, e.g.,
Unifying DataFrames and Datasets in Scala/Java. Starting in Spark 2.0, DataFrame is just a type alias for Dataset of Row.
Spark 2.0 provides a new API called Structured Streaming. Compared to existing streaming systems, Structured Streaming provides Integrated API with batch jobs, transactional interaction with storage systems and rich integration with the rest of Spark.
We focus on learning the basic concepts through the older, stable APIs for now, as used in version 1.6 and earlier (can still be used with version 2). However, it is important to be aware of new developments in Spark.
-
Further reading