-
Motivation
Scaling computation is only part of the story…
A cloud application’s data handling has to scale well. If it doesn’t, then the cloud’s computational scalability gets bottlenecked into uselessness.
Data has to be spread around multiple servers sometimes with geo-replication.
Often (certainly with relational data) no easy answers and dependent on both the data and the application.
Overview
- Azure Cloud Storage (non-relational)
- A Microsoft product but other cloud vendors offer similar technology often implemented as services
- semi/unstructured data
- massive scalability
- key-value stores
- blobs, queues, (non-relational) tables
- uses some features from non-relational databases
- abstractions of block storage and not a full database as such
- Non-Relational Databases (NoSQL)
- semi/unstructured data
- massive scalability
- key-value stores, column stores, document stores, graph databases...
- Relational Databases
- good for structured data - schemas
- but not so good for semi/unstructured data which has increased in prevalence
- do not scale well
- but lots of relational data about that needs to be deployed in the cloud...
- various techniques to try to make them scale
-
Key/Value Stores
Standard concept for cloud storage and non-relational databases.
and some distributed caches e.g. redis
Unique key identifies a value whilst hiding its actual location.
i.e. user does not know directly where it is in the cloud or its replication
Value is dependent on implementation.
in a column store NoSQL database this would be akin to a record
Azure Cloud Storage
A bit like “a file system for the cloud”.
i.e. always there and accessible from applications without having to start any separate service
Common storage structures include blobs, tables, and queues.
Generally do not attempt to enforce any data integrity i.e. to enforce referential integrity.
whatever integrity the application requires is the responsibility of the program developer
As a result cloud storage tends to scale very well.
- Cloud storage exposes RESTful APIs.
- so you can get or put a blob etc…
- the Azure SDK for storage is in fact a CLR wrapper around REST calls
Again a key/value store.
- Values are blobs or (non-relational) tables or queues.
- basically share the same idea
- blobs and tables exist separately to allow different optimisations
- for unstructured and semi-structured data respectively
- (on Azure) Each cloud server splits disk space into 1 or more partitions.
- a partition is a set of disk blocks’ data on one server
- implemented on an enhanced distributed file system (hidden from programmer)
- each partition can be moved between servers dynamically within the cloud according to load or size to ensure it scales
- the key includes the identity of the partition (partition key)
- in detail the keys are used differently in tables, blobs and queues
Azure Cloud Storage Structure
Blobs Tables Queues Key/Value Store - movable and resizable Partitions Distributed File System Disks Blocks Blobs
BLOB = Binary Large Object.
Storage of an unstructured binary object in a single partition.
Contents are opaque to the storage service.
Blob has settable metadata.
e.g. a name allowing one blob to be distinguished from another
Stored in blocks (optional access to this level for effective random access).
Can map file system to a blob for legacy applications.
Example of content: videos, songs, pictures, newspaper articles.
Azure Blobs or AWS Simple Storage Service (S3).
Azure Blobs
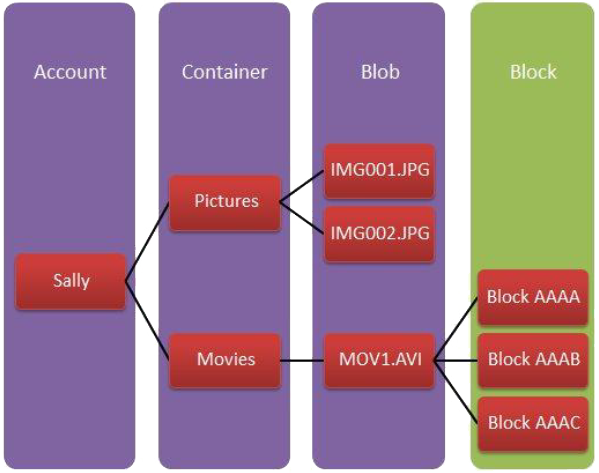
Containers (buckets in S3) facilitate an administrative breakdown of the blob space.
provides a namespace mechanism
- The key value identifying the partition is the container name + blob name.
- each blob has its own partition
- blobs can be distributed across many servers
Queues
A queue is a classic first-in, first-out data storage structure.
Primarily used for passing data from one computing job to another in a loosely-coupled fashion.
- typically between role instances
Generally not used for long-term storage.
- Scale really well.
- there are limits on the rate of message processing
- if the rate proves insufficient can be scaled by creating multiple queues
- The key for a message is the queue name.
- all messages in the same queue are grouped into a single partition and are served by a single server
- different queues may be processed by different servers i.e. to balance the load for multiple queues
Azure Queues or AWS Simple Queue Service (SQS).
- offer similar feature sets with minor differences in QoS
Azure Tables
Semi-structured data without schemas.
Basically collections of name-value pairs.
You can use them in any convenient way, like a property bag.
- each row/entity can have a different set of properties
However probably most useful in the classic row-column case.
- Primary difference from relational tables is the absence of relations and thus referential integrity checks e.g. no joins are available.
- scale much better than relational tables
- it is possible to work round the lack of relations but the functionality has to be “hand crafted”
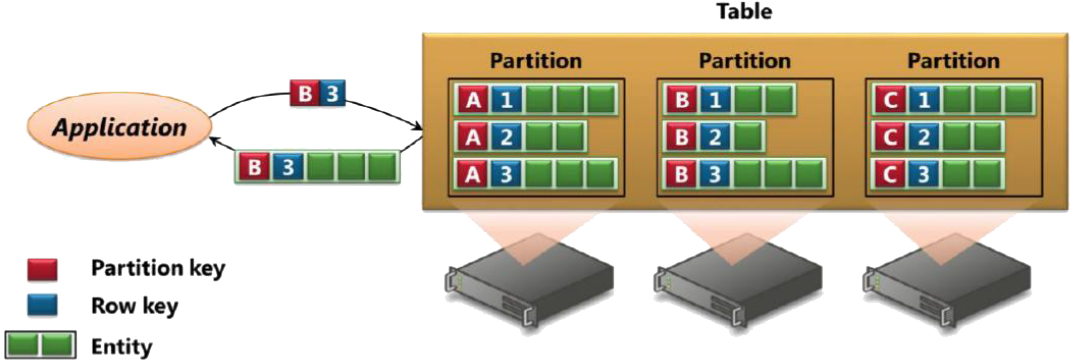
in Azure entity = row; property = column
Key is 2 parts: partition key and row key
Max entity size is 1MB
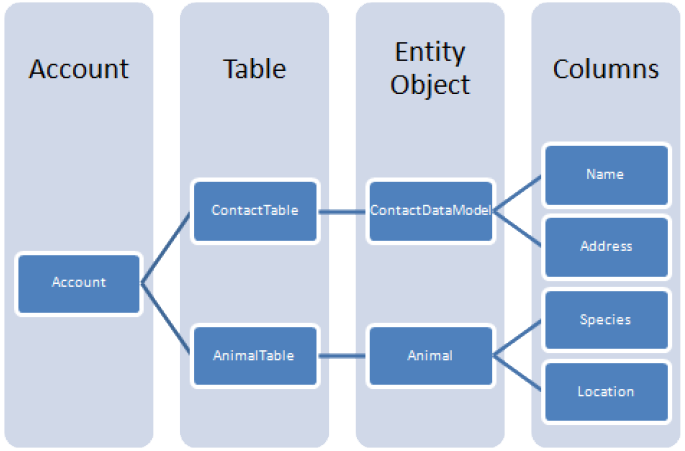
in Azure entity = row; property = column
Key is 2 parts: partition key and row key
- The programmer has control over the entity/row partitioning i.e. what partition has what entities.
- at least logically to ensure that a subset of entities can be kept together
- need to balance the scalability benefits of spreading entities across multiple partitions with the data access advantages of grouping entities in a single partition
- apart – better load balancing and scalability
- together – atomic batch operations possible e.g. limited transactional operations across multiple entities
DynamoDB is an AWS service offering similar functionality with some enhanced features but runs as a service
- Lab 4 contains code examples.
- Part 1 - TestTables - demonstrates using a console application how to carry out basic tasks on Azure tables
- Parts 3 to 5 - ProductStore - RESTful application using an Azure table to persist data
- We will always be using just one table with one partition with a fixed property (column) set.
- note that you cloud easily simulate relations by putting key values of a separate table in a property
- but you would have to code the integrity...
Useful link: 🔗 Get started with Azure Table storage and the Azure Cosmos DB Table API using .NET
X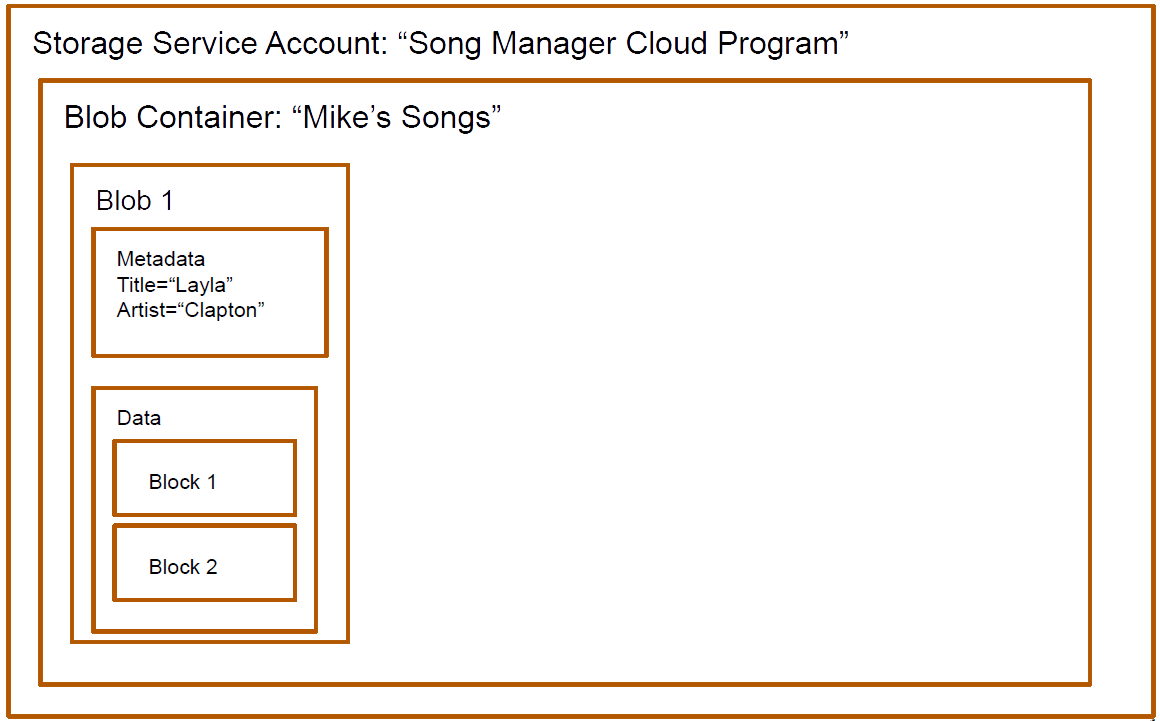 X
X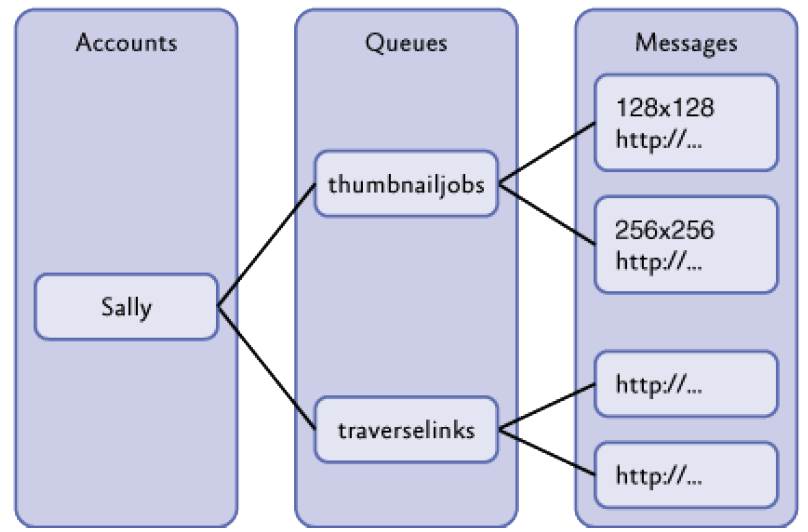 X
X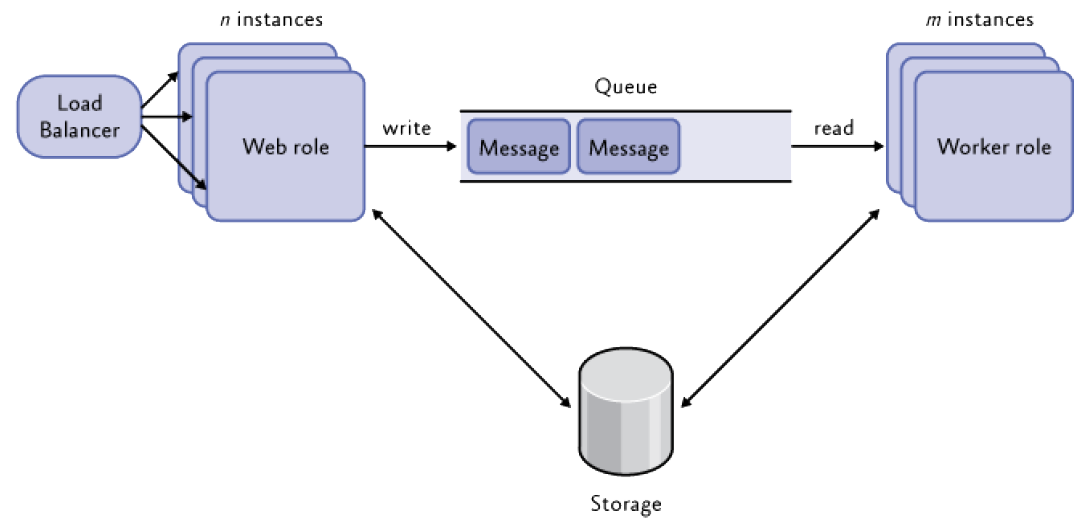 X
X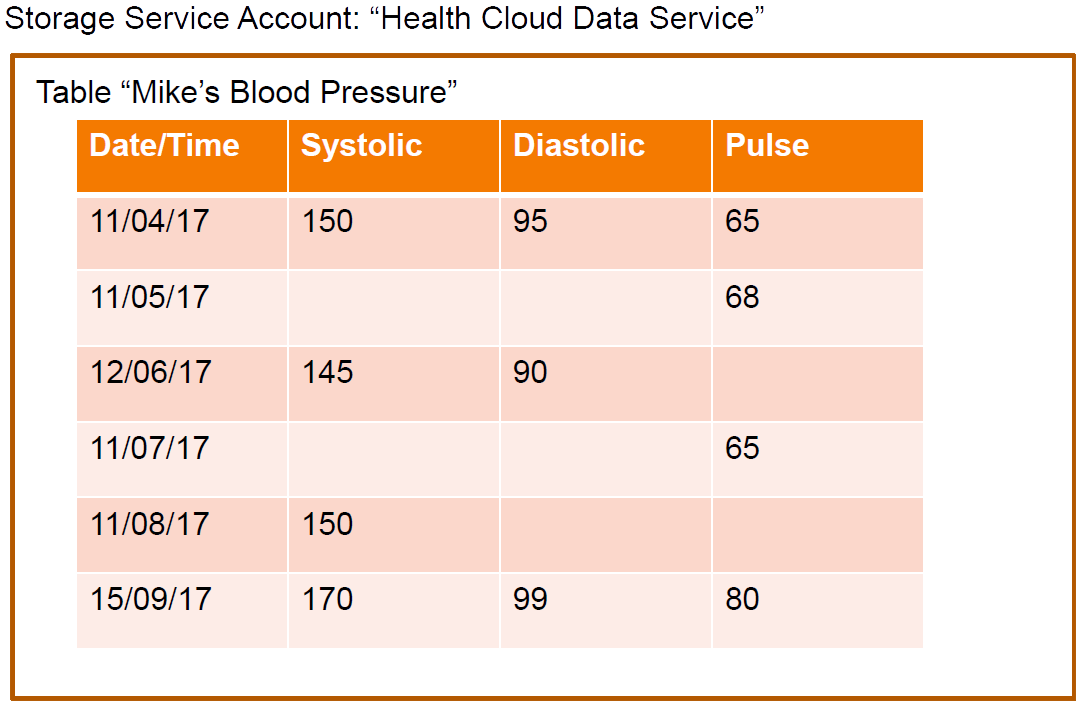
-
Non-Relational Databases
- Many different options with different characteristics.
- many available as managed services from cloud vendors
- usually have a weaker consistency model than relational databases (see later lecture)
Column Stores: data stored in schema-less records with variable columns (fields). Also wide column stores which can have very large no. of dynamic columns e.g. Cassandra
Document Stores: structured data stored as values e.g. JSON. Data can be fully indexed and queried e.g. MongoDB, MS Document DB
Azure Tables in Context
Azure tables offers basically a high performance geo-replicated column store database with a RESTful API.
- However if you require complex queries or require to manipulate richer data types you may need a full-blown NoSQL database.
- e.g. with Azure tables it is inefficient to query on values
- only the partition and row keys can be indexed
Performance and cost also have to be benchmarked for the data and data access behaviour.
Not an easy answer and a moving target...
-
Relational Databases
Q: What’s the problem?
A: Relational tables are difficult to scale out well.
by definition relational databases contain necessary and complex relations between tables- The reason these do not scale well is because of the need to enforce referential integrity.
- this check is undertaken by the dbms itself
- the dbms needs to be able to communicate between all tables involved at the same time
This ability degrades as the number of tables and relations increases and with the number of rows in each table.
- may be able to scale up to a certain degree, but scaling out difficult
Important observation: most data services are read-dominant.
- database replication works well for them
Some of the scalability techniques used predate the cloud and have been leveraged.
- we will review the common techniques:-
- 1. Functional Partitioning
- distribute complete tables
- limiting the scope of UDI queries i.e. UPDATE, DELETE, INSERT
- 2. Vertical Partitioning
- split tables by columns
- denormalisation
- 3. Horizontal Partitioning
- sharding
- split tables by rows
A relational database designed for the cloud (e.g. Azure SQL) will offer a mix of these techniques but their actual use is up to the database designer and is application dependent.
- none of this can be applied automatically…
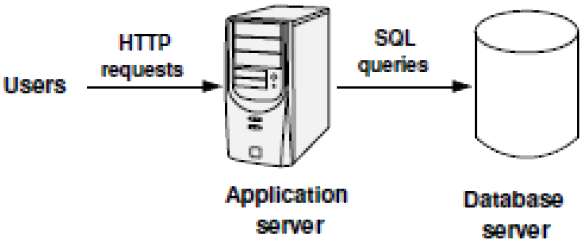
Typical Simple Web Architecture
One application server runs application code.
- assume a simple one instance web role
One database server holds the application state.
- The application code can issue any query to the database.
- SELECT (read queries)
- UPDATE, DELETE, INSERT (UDI queries)
- transactions
Scaling the Architecture
- The application server contains only the application code.
- could be a simple multi-instance web role
- it does not hold state
- different requests can be processed independently
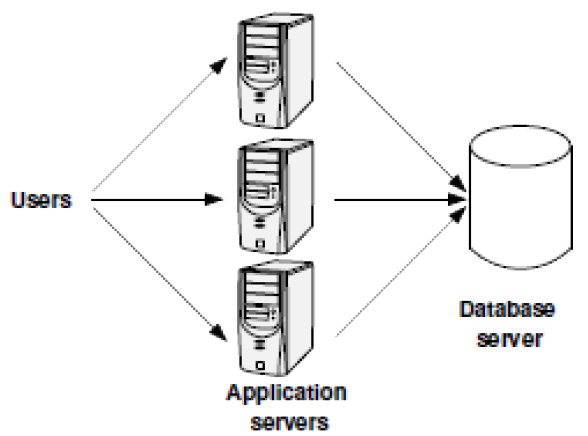
Replicating the Database
- Data is fully replicated across multiple database servers.
- read queries can be addressed at any replica
- UDIs must be issued at every replica (to ensure data consistency)
Each database server must process:-
- 1/N Read Queries + UDI Queries
- increasing N does not help when the UDIs alone saturate the server‘s capacity
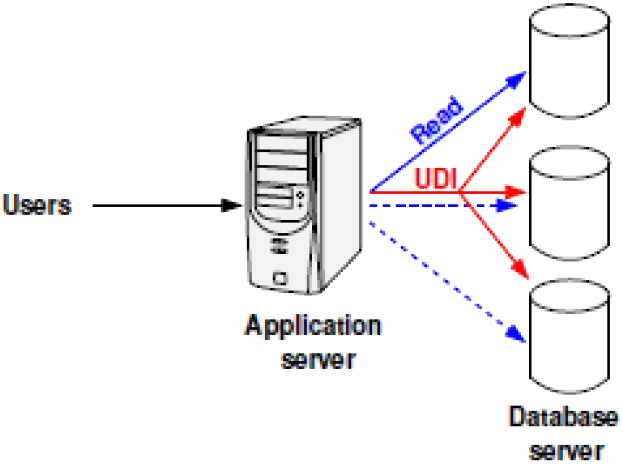
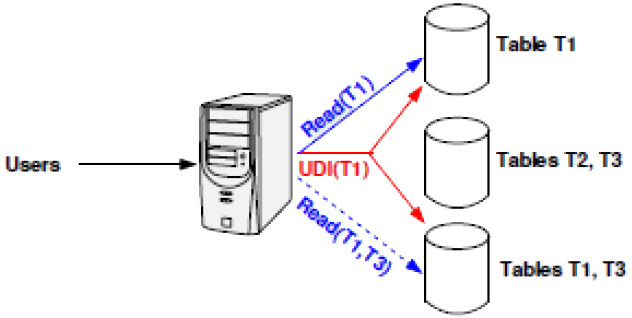
Functional Partitioning
- We must send less UDIs to each server.
- each server contains a subset of all tables
- note tables are intact here
- limits the scope of UDI queries
Updates to T1 must be addressed to only 2 servers.
We must place tables according to query templates.
- we cannot execute a query that joins T1 and T2. . .
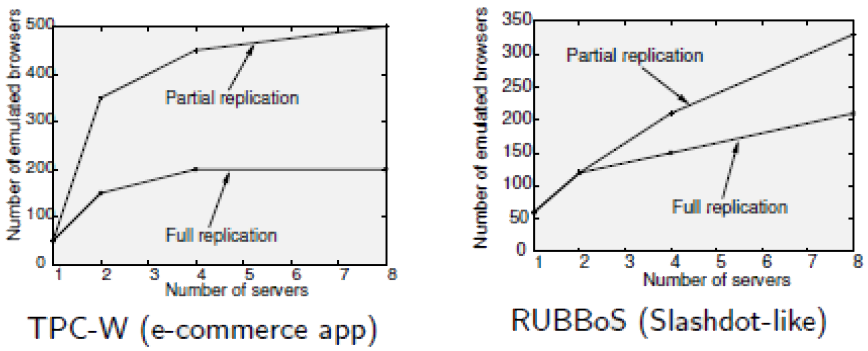
It can be shown that this can dramatically improve scalability.
- However granularity may be too coarse.
- maximum gain limited by number of tables
- whilst saying that the tables may be replicated
- we can introduce a finer granularity: column-level
Vertical Partitioning
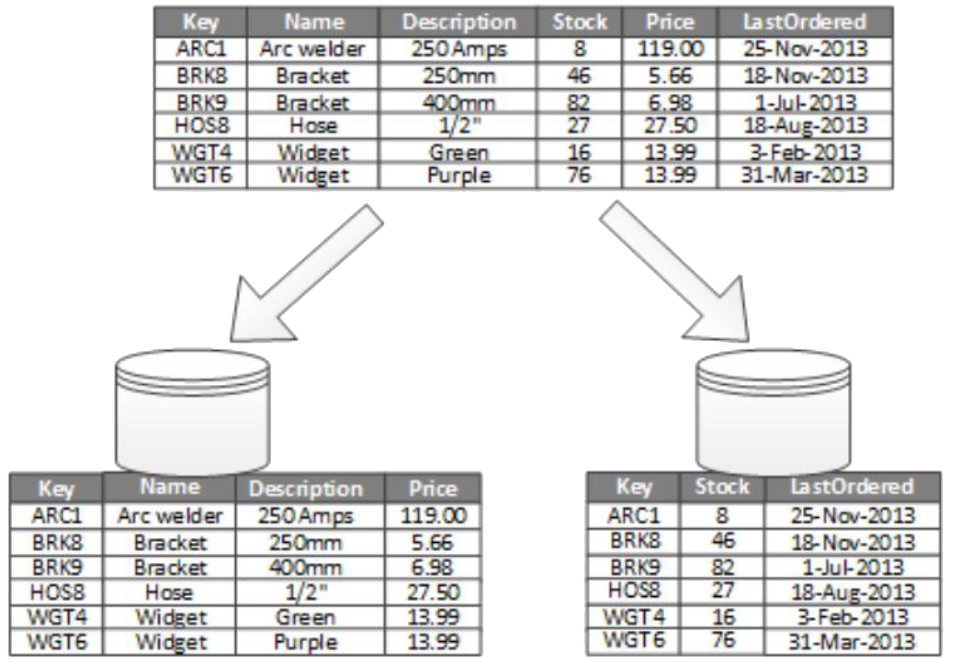
- Reduces the I/O and performance costs associated with fetching the items that are accessed most frequently.
- column-level oriented
- schema has to be reorganised
- columns with common access behaviours can be held together and optimised separately
- e.g. speeded up with the introduction of a cache
- different collections of columns can be secured separately
However now have the issue that even simple queries may have to access data from more data services.
Performance can be further improved if some partitions are read-only and can thus be easily replicated.
Denormalisation
Denormalisation is a variant of vertical partitioning.
- Intentionally duplicate columns across multiple tables.
- denormalise data into separate services
- replicate read-only columns across multiple tables and data services
Horizontal Partitioning
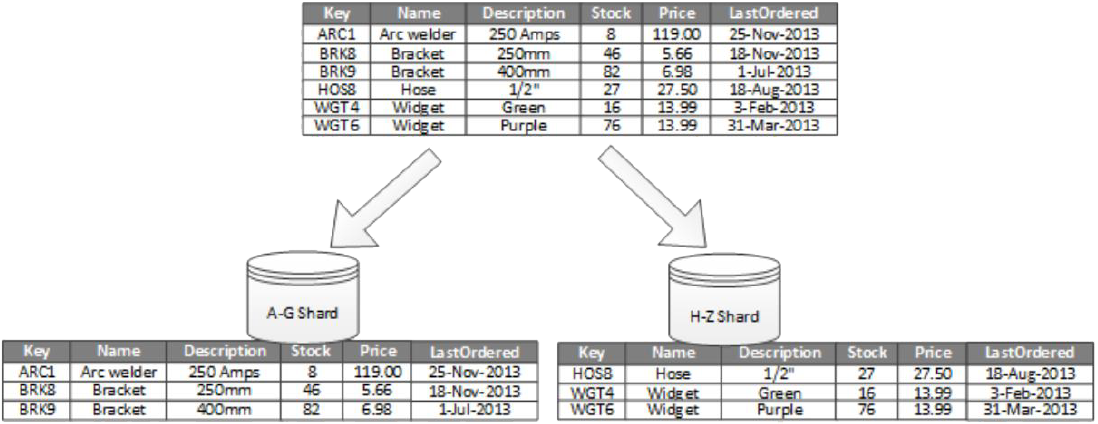
Also commonly called sharding.
Notice all shards have the same schema.
Most queries are indexed by primary key.
- Common approach is to hash table records by their primary key.
- (not shown in the diagram)
- other mathematical functions are used too e.g. modulo
- split hash space evenly between shards (i.e. servers)
- can be difficult to later rebalance the data distribution...
- as the hashed key value is random this ensures balanced distribution of rows between shards and can ensure balanced workload
- avoids “hot partitions”
However main requirement is to balance requests to shards and not to ensure they should contain same amount of data.
- important to ensure that a single shard does not exceed the scale limits (in terms of capacity and processing resources) of the data store being used to host that shard
Consistent Hashing
Problem with adding/removing servers is in rebalancing the data distribution...
- need to reorganise values across the current servers
Consistent hashing is an approach to limit changes so that only K/S values (no. possible keys/no. shards) have to be reorganised on adding or removing shard servers.
Note that in general the concept of sharding, key hashing (and consistent hashing) is used in NoSQL databases and other technologies as well.