-
XML and JSON
Languages used to describe serialized data being communicated to/from web services.
- XML has many additional uses as well
- Both are text-based and support a standard syntax.
- open and non-proprietary
- easier heterogeneous integration – everything text based
- really for describing data and not programming languages
- a standard syntax avoids the use of native data formats and aids the reuse of common tooling
JSON much lighter but can do much more with XML...
REST uses JSON/XML; SOAP uses XML.
-
XML in Brief
<myelement>some text data</myelement>
- XML is a language for creating other languages – it is a meta-language.
- a meta-language is a language that is used to describe other languages i.e. you define your own tags
- essentially an XML document is a text file, representing a data structure defined in terms of elements, attributes and entities etc.
XML 1.0 and 1.1 are W3C recommendations i.e. international standards.
- Two important recommendations which are used with XML to do anything useful are:-
- XML Schema
- XML Namespaces
- XML lets you define schemas for tag-based languages (thus - “markup language”).
- i.e. XML defines the syntax and you (or a standard) define the structure of these languages
- e.g. defines the allowed elements, what attributes go with what element, elelment order, allowed child elements etc. etc.
- structure is defined in a schema (schema with a small ‘s’). Several options (of which the main three are):-
- DTDs
- XML Schema (XSD)
- RelaxNG
in fact the use of any of these is optional - documents which are syntactically correct are called well-formed
- documents which additionally adhere to a given schema e.g. a XML Schema definition are called valid
XML 1.0/1.1 and JSON
- XML 1.0/1.1
- XML Declaration and Character Encoding
- XML 1.0 and 1.1
- Elements
- Attributes
- PCDATA
- Entities
- CDATA
- Processing Instructions
- Serialization of XML
- JSON
- strings, numbers, booleans, null, objects and arrays
- comparison with XML
- Serialization of JSON
X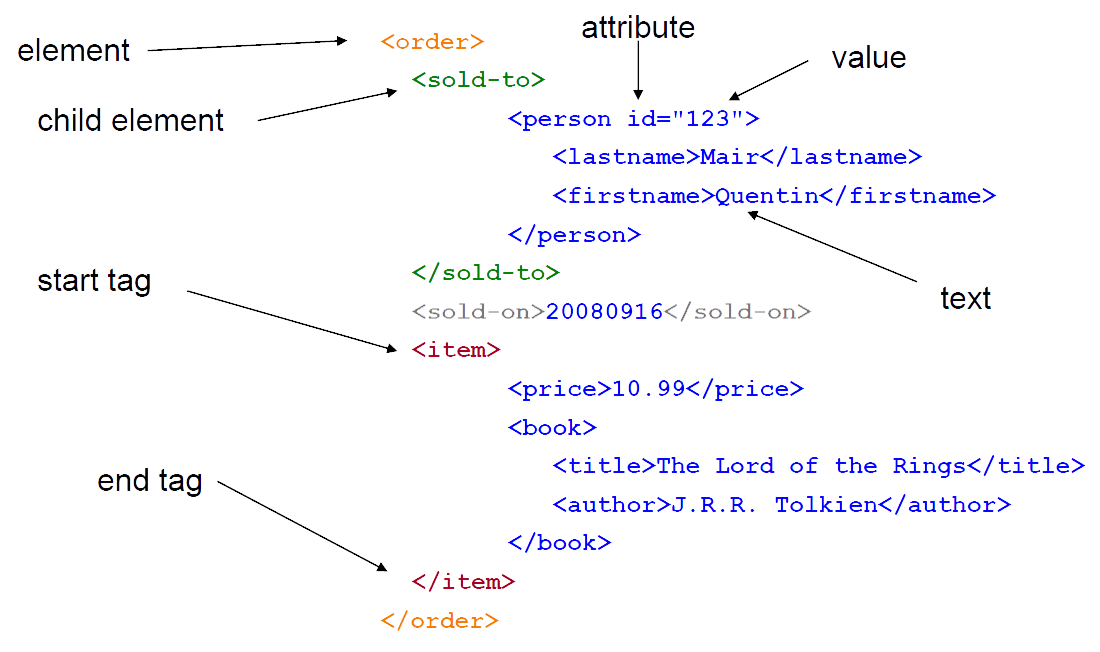
-
XML 1.0 – A Representative Document
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE students SYSTEM "student.dtd"> <!-- This is an XML document that describes students --> <?studentdb displaydesc="true"?> <students> <student id="0001"> <name>Jim Bob</name> <status>graduate</status> <residence/> <degree>Advanced Computing & Music</degree> <description>Jim Bob! Hi my name is Jim. I look like <img src="jim.jpg"> ]]> </description> </student> <student id="0002"> ... </student> </students>XML Declaration
<?xml version="1.0" encoding="UTF-8"?>
- Optional
- default implies XML 1.0 and UTF-8 assumed
- so it’s 1.0 unless you specify otherwise
A Processing Instruction (see later).
Must appear as the very first thing in an XML document.
Used to indicate the version of the specification to which the document conforms (and whether the document is “standalone” i.e. a DTD is part of the file).
- Used to indicate the character encoding of the document.
- UTF-8
- UTF-16
- iso-8859-1
- ...
XML Character Encoding
- Every character in an XML document is a unicode character.
- the encoding (which may not be unicode) is merely a convenience for representing the characters in a file
- the parser will translate this into unicode internally
- A very messy world but usually not a problem if you stick to the first 128 characters (“US-ASCII”) which are all the same:-
- iso-8859-1 (Latin characters/Western European – old but sill used)
- windows-1252 (or “ANSI”) (27 differences from iso-8859-1)
- UTF-8 (newer, recommended) “8-bit Unicode Transformation Format” (can represent any character as a sequence of 8-bit values)
You should stick to UTF-8 (default) and always use a declaration.
If you do not use UTF-8 then make sure the declaration is consistent for your character content.
XML 1.0 and XML 1.1
- XML 1.1 has:-
- better support for Unicode characters
- better support for control characters
- mandatory XML declarations
XML 1.0 and XML 1.1 are not quite upwardly compatible!
In English and European language markup this all makes little effective difference.
XML 1.1 (Second Edition) (2006) incorporates errata.
Tool/compiler support in Java is for XML 1.1.
Tool/compiler support in .NET is for XML 1.0.
DOCTYPE
<!DOCTYPE students SYSTEM "students.dtd">
References a Document Type Definition (DTD).
Can refer to an external DTD file or include some internal DTD information within the tag itself.
DTD is the original mechanism for specifying the schema of an XML document.
- Inherited in part from previous SGML standard.
- arcane syntax
- limited expressive functionality
We will consider newer XML Schema instead of DTDs.
Elements
<name>Jim Bob</name>
Main structure in an XML document.
Only one root element allowed.
everything else inside this
Start Tag
allows specification of zero or more attributes
<student id="0001" ...>
Closing Tag (or End Tag)
must match name, case, and nesting level of start tag
</student>
Name must start with letter or underscore and can contain only letters, numbers, hyphens, periods, and underscores.
Element Content
<student> <status>...</status> </student>
Parsed Character Data (aka PCDATA, aka Text)
<name>Jim Bob</name>
Mixed Content
<name>Jim <initial>J</initial> Bob</name>
No Content
<residence/>
The usual relative terms are used for adjacent elements.
parent, child, sibling
Attributes
<student id="0001">
Element properties
must be valued
- Name
- must start with letter or underscore and can contain only letters, numbers, hyphens, periods, and underscores
- must be unique in a given element
- Value
- can be of several types, but is almost always a string
- must be quoted and have the ‘=‘
- title="Lecture 2"
- match='item="baseball bat"'
- cannot contain < (at all) or & (by itself)
Elements and Attributes
- Use which where?
- “Should this data be coded as an element or an attribute?”
- XML’s great imponderable
- If data in an element:-
- easier to read (or so it’s said anyway)
- can have multiple values (i.e. sibling elements)
- can have children
- extendible
- If data in an attribute:-
- should be used as meta-data about the element
- not hierarchical
- used to distinguish between elements and has no further use
- No hard and fast answer
- a design decision
- programmatically much the same work to get at element or attribute data
PCDATA
Jim Bob
“Parsed Character Data”
Has to be parsed because it may contain child elements.
Text that appears as the content of an element.
Can reference entities.
Data within is checked for sub-elements, entities, etc.
Cannot contain either < or & (by itself).
Entities
&
Used to “escape” content or include content that is hard to enter or repeated frequently.
somewhat like macros
Five (and only five) pre-defined entities (note the trailing ‘;’).
& < > ' "
Character entities can refer to a single character by unicode number.
e.g., © is ©
- Symbolic entities must be declared to be legal (in a DTD) i.e.
- <!ENTITY mycopy "©">
- &mycopy; could then be used in the XML document
Cannot refer to themselves.
CDATA
<![CDATA[ <h1>Jim Bob!</h1> ...]]>
“Character Data”
Parsed in “one chunk” by the XML parser.
Really data for a recipient application.
Data within is not checked for sub-elements, entities, etc.
Only string you can’t have is ]]>
Allows you to include badly formed markup or character data that would cause a problem during parsing.
Example:-
including HTML tags in an XML document which use markup minimisation i.e. no closing tag
Comments
<-- This is ... -->
Can include any text inside a comment to make it easier for human readers to understand your document.
Generally not available to applications reading the document.
Always begin with <!-- and end with -->
Cannot contain --
Processing Instructions
<?studentdb displaydesc="true"?>
“Sticky notes” to applications processing an XML document that explain how to handle content.
The target portion (e.g., studentdb) of a PI indicates the application that is to process this instruction; cannot start with “xml”.
The remainder of the PI can be any text that gives instructions to the application.
- Examples:-
- XML Declaration
- instructions to an application to display different versions of an image
- instructions to an application to suppress display of certain content
XML Tools and API Libraries
- Many language bindings available with different implementations.
- Xerces/Xalan(Apache), .NET System.XML (Microsoft)…
- in the core language/framework class libraries
- will additionally check if document well-formed and valid
- Many approaches to process XML over the years:-
- stream parsers
- in memory processing e.g. DOM
- processing engines e.g. XSLT
As a case study Lab 3 contains a .NET/C# application to serialize/de-serialize a list of objects of an arbitrary class.
- uses current standard libraries
-
JSON
JavaScript Object Notation (JSON)
JSON is an alternative to XML and is the data interchange format of choice in modern web services.
- Wire format introduced for AJAX Web applications (browser-web server communication).
- specifically for data-exchange (self-documenting)
- considered simpler than XML (simple and faster parsing)
- much more compact and lightweight than XML (minimal; but still text)
- most common as representation in RESTful web services
- Data-types completely described by:-
- strings, numbers, booleans and null
- objects
- unordered collections of name/value pairs
- values themselves may be of any type including objects and arrays i.e. can be nested
- arrays
- ordered sequences of values
- can represent records, list and trees using objects and arrays etc. by nesting them to an arbitrary complexity
- Simple syntax
- objects enclosed in curly braces with colon between name and value
- arrays enclosed in square brackets
- items are separated by commas and white space is insignificant
Supported in most languages.
JSON and XML
JSON has much less expressive power than XML.
- JSON has no feature to express:-
- attributes
- namespaces
- mixed content
Although it is possible to shoehorn some of these features into JSON e.g. attributes, they are not represented in a standard manner.
XML has many more processing APIs than JSON.
- and many of them (not all) are standardised
Any translation scheme from XML to JSON should be lossless i.e. not lose any information but this is difficult to achieve and depends on the XML document.
- JSON Schema
- is a standardisation initiative for a schema representation
- an IETF draft standard
- schema are themselves defined in JSON
- 🔗 JSON Schema
- VS 2015 onwards has support for JSON Schema in its JSON editor
- Many JSON API libraries including:-
- JSON-P libraries in Java EE 8
- .NET 4.5 – Json.Net (Newtonsoft) is the current API library of choice.
- 🔗 https://www.newtonsoft.com/json
X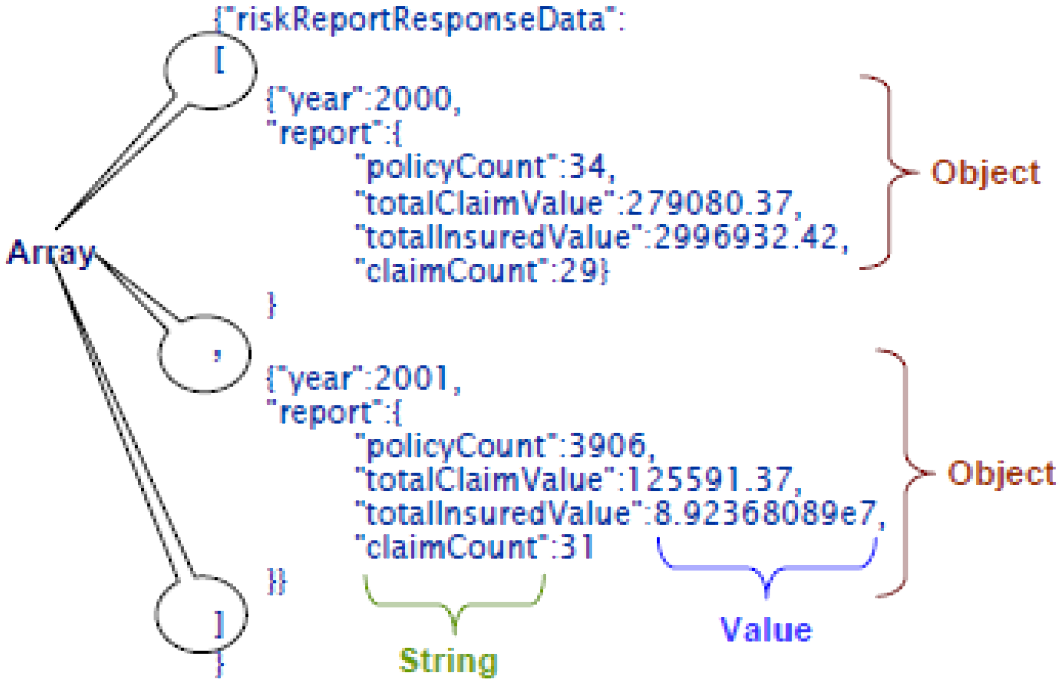
-
XML Namespaces
- XML documents:-
- are a tree of elements
- each element has a name and a set of attributes
- each attribute has a name and a value
- each element and attribute name is an unrestricted string from a set of restricted characters
- we can call such a name, as we have defined so far, a local name
- an application (a parser) will process the element based on the element and attribute name/values
- they are used extensively in WSDL which we will be studying shortly
- XML passed in web service communication will most likely use namespaces.
- If there is no control over naming in XML:-
- different programmers/standards bodies may/will pick the same names producing conflicts
- we may wish to mix different languages in the one XML document and these may use (some of) the same names (compound documents)
- the application (parser) will not be able tell elements/attributes with the same names apart and will wrongly process them
- we do not want potential name clashes to be a concern for the designer of an XML language
- see http://www.rpbourret.com/xml/NamespacesFAQ.htm#ns_2 for more reasons
- Solution:-
- introduce expanded names which are additionally scoped by a namespace
- an optional mechanism providing additional information external to the XML document
-
URIs
- URI (Uniform Resource Identifier)
- “a compact string of characters for identifying an abstract or physical resource”
- see: 🔗 http://tools.ietf.org/html/rfc3986
- URL (Uniform Resource Locator)
- subset of URIs
- its location i.e. how to find it
- “identify resources via a representation of their primary access mechanism, rather than … by name or some other attribute”
- URN (Uniform Resource Name)
- subset of URIs
- its identity e.g. urn:isbn:0451450523
- persistent and location-independent
- “required to remain globally unique and persistent even when resource ceases to exist or becomes unavailable”
-
Namespaces in XML 1.0/1.1
- Namespaces 1.1 adds support for:-
- unicodeURIs (called IRIs)
- undeclaringprefixes (and thus the current namespace)
- Java (through Xerces) has support for Namespaces 1.1
- .NET 4.5 however has support for Namespaces 1.0
An up-to-date reference for XML namespaces is at:-
🔗 http://www.rpbourret.com/xml/NamespacesFAQ.htmXML Schema
- XML Schema Definition (XSD) became an official recommendation in May 2001; Second Edition in October 2004.
- Primer
- an overview (> 150 pages alone!)
- Structures
- Data Types
- A very large standard.
- much of which should be kept as a reference rather than attempt to learn -a large and verbose standard
The Second Edition addresses only some bugs and minor loose ends of the original standard.
Main Features of XSD
- XML Syntax
- there is a schema for schemas
- you can validate the schema (in EditiX -Lab 3)
- Object-oriented type system
- with inheritance, abstract types and finals
Global(=top-level) and local(=inline) type definitions
Modularisation
- Built-in data-types
- about 40 of these
- not just positive integers etc. but dates etc.
- can add constraints to the built-in types e.g. cardinality, ranges...
Regular expressions
An Example...
config.xml and config.xsd
The XML document which is meant to be valid with respect to a given XML schema definition is referred to as the instance document.
- Notice that:
- XML instance points to schema
- XML Schema declares elements (and attributes)
- XML Schema defines types
- types come in a number of varieties:
- Built-in types (e.g., xsd:string, xsd:date)
- Simple types
- Complex types
- there is a implicit assumption of 1 embedded in many constructs e.g.
- <xsd:sequence>
- i.e. here the sequence must occur once only
- another value or range can be specified
Why?
- Data validation
- structure of elements and attributes
- order of elements
- data values of elements and attributes
- uniqueness of values
Simplifies interoperability and tooling if parties can agree acceptable data formats described in a standard way.
Documentation.
Augmentation of instance with default values.
Storage of application information.
Application can avoid error checking if it can be assumed instance already validated.
- There is a meta-schema for XML Schema documents.
- i.e. a XML Schema document’s own validity can be checked against this!
Another Example (product.xsd)
<xsd:schemaxmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:elementname="product" type="ProductType"/> <xsd:complexTypename="ProductType"> <xsd:sequence> <xsd:elementname="number" type="xsd:integer"/> <xsd:elementname="size" type="SizeType"/> </xsd:sequence> <xsd:attributename="effDate" type="xsd:date"/> </xsd:complexType> <xsd:simpleTypename="SizeType"> <xsd:restrictionbase="xsd:integer"> <xsd:minInclusivevalue="2"/> <xsd:maxInclusivevalue="18"/> </xsd:restriction> </xsd:simpleType> <product effDate="2008-04-02"> </xsd:schema> <number>557</number> <size>10</size> </product>Namespace Usage Examples
<prod:product xmlns:prod="http://example.org/prod" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://example.org/prod prod.xsd"> <prod:number>557</prod:number> <prod:size>10</prod:size> </prod:product> <order xmlns="http://example.org/ord" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> xsi:schemaLocation="http://example.org/prod prod.xsd http://example.org/ord ord.xsd" <number>123ABBCC123</number> <items> <product xmlns="http://example.org/prod"> <number>557</number> <size system="US-DRESS">10</size> </product> </items> </order>