-
Overview
- HTTP/1.1
- Architectural Styles – REST and SOAP
- REST details
- REST Architectural Constraints
- HTTP Method Semantics and POST vs. PUT
- REST MVC
- Swagger
- OData
- Lab 4
-
Hypertext Transfer Protocol
- HTTP/1.1 ubiquitous
- runs over TCP (connection oriented)
- text-based headers
- can carry HTML, XML or JSON (or any text or binary data) as message body (payload)
- A request message contains:-
- a request type
- a sequence of variable request headers
- an optional request body (e.g. for POST/PUT– see below)
- A response message contains:-
- integer status code
- a sequence of variable reply headers
- the data object (representation of a resource) if applicable
- e.g. the contents of a file or dynamically generated content
HTTP/1.1 Request Types
The HTTP/1.1 protocol is formally specified in terms of "methods," rather than simple commands. The main methods include:-
GET
Request to read a generalised resource at a given URI. The object can be HTML, XML, an image, a sound sample or a wide range of other types.HEAD
A request to return the response header only, without the content. This can contain much useful information about the requested resource, without the need to actually load it – e.g. how big it is.POST
Send some data to a specified URI. The server at the URI can do whatever it wants with this data. Used typically to upload data to the server e.g. from a form. It may create a new page at the URI. It may additionally generate a side-effect e.g. initiate an email to be sent at the serverPUT
Puts a resource at a specified URI. If a resource is already there it is replaced.DELETE
Delete the specified resource.HTTP/1.1 Status Codes
An HTTP/1.1 response will contain one of several integer status codes – the possible codes being dependent on the request type. These status codes include:-
200 OK
The client's request was successfully received, understood, and accepted.201 Created
The request has been fulfilled and resulted in a new resource being created. Usually PUT and POST. URI of new resource returned.204 No Content
The request was successful and the response has no message body.302 Moved Temporarily
Resource temporarily moved. Returns URI of new location.404 Not Found
400 Bad Request
See: 🔗 https://developer.mozilla.org/en-US/docs/Web/HTTP/Status for a more complete list of common codes.
X
-
Web Service Architectural Styles– SOAP and REST
- The challenge is to use HTTP somehow to access programmatically data and processing power at the server.
- must use HTTP and a web server (or code which emulates a web server)
- client may be a web browser (JavaScript etc.) but could be any other client type
- need structured data format e.g. XML or JSON
Industry has settled down to two architectural styles:-
- 1. SOAP-based (RPC)
- sends XML messages in SOAP envelopes inside the Request/Response bodies via POST. An application specific interface is described in WSDL (an interface definition language – also XML)
- strong typing
- “actions” or “verbs”
- methods in interface define actions
- WS-I governs interoperability standards (profiles)
- more related specifications (especially more security options) than REST
- SOAP is one technology that could be used to develop a SOA-based system but SOA $\neq$ SOAP
- 2. REST
- sends and gets JSON or XML using the HTTP methods as they were originally intended (again inside the HTTP Request/Response bodies)
- “things” or “nouns”
- resources
- HTTP method defines operation on resource
- not just POST but GET/PUT/DELETE etc.
- uses URLs extensively to access remote computing resources
- more efficient and lighter than SOAP
- more scalable
- and thus more popular in mobile computing with constrained resources and limited/expensive bandwidth
- RESTful APIs or just “APIs” becoming “a large ecosystem”
Architectural Styles
- “An architectural style is a coordinated set of architectural constraints that restricts the roles and features of architectural elements, and the allowed relationships among those elements, within any architecture that conforms to that style.”
- a style can be applied to many architectures
- an architecture can consist of many styles
WS-* (SOAP standards) and HTTP are sets of technologies; not the same thing as an architectural style which defines how you build architectures using the technologies.
REST is not a protocol stack.
REST is an architectural style, with constraints, which is appropriate when a Resource Oriented Architecture (ROA) is desirable.
ROA – hence the ideas of resource and representation.
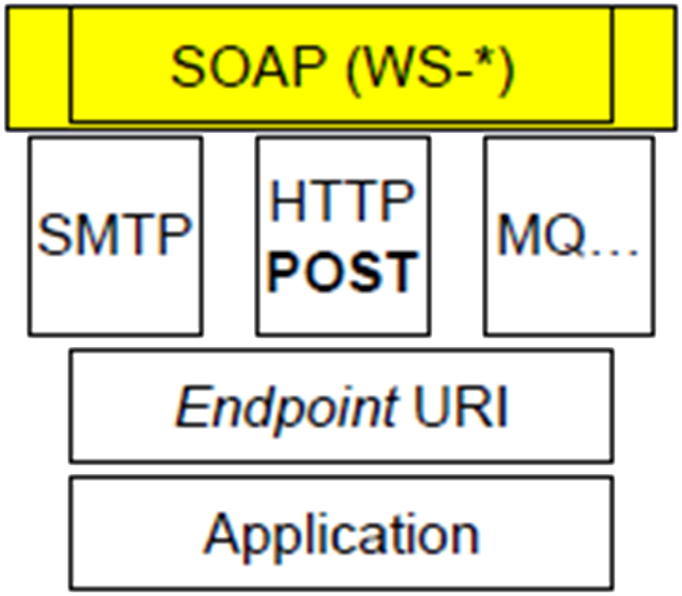
An alternative architectural style is RPC; an “action” style.
SOAP and WS-*
An application specific interface is defined.
Requests and replies compliant with the interface are tunnelled through (usually) HTTP POST.
XML in SOAP envelopes.
Largely disregards HTTP’s built-in features e.g. caching, content type negotiation…
-
REpresentational State Transfer
Defined by Roy Fielding in his PhD thesis in 2000.
Widely misunderstood.
- beware - much of what you will read on the Web about REST is wrong!
REST is an architectural style.
- resource rather than action based
- A REST web service is based on the concept of a resource. A resource is anything which has a URI.
- for example a database record
- it is possible for more than one URI to refer to the same resource
Often used to refer to any API available to clients through simple HTTP requests.
- Clients should be able to:-
- select a specific resource by accessing a URL
- specify the action to be taken on the resource using an HTTP method (GET, POST, PUT, etc.)
- send a new resource represented as body data or URL parameters
- understand the response:-
- format, or media type, for resources specified using HTTP headers
- appropriate HTTP status codes returned to inform client in a consistent way, e.g 200, 404
Not all “REST” APIs are truly RESTful.
Designing a REST API should be done carefully to follow the principles of REST.
- A resource is conceptually separate from its representations returned to a client.
- so there can be different representations of the same resource
- typically JSON or XML
- part of resource state
- passed between client and server
- when a client holds this it has enough information to modify or delete the resource on the server
- REST != HTTP
- in fact it can be any communication technology as it’s a style
- of course HTTP is the one usually associated with it
- and was the example used in Fielding’s PhD thesis
- the architectural features underlying HTTP
REST and Technology
REST is not just about web services – it could be any client-server technology.
- REST is most often associated with a back-to-basics approach to building “simplified” web services with the HTTP methods.
- HTTP is simply the transfer protocol
- the HTTP methods taken together form a single, fixed uniform interface
- all interaction is hypertext/hypermedia based
- exchanging resource representations in the way the methods originally intended
- resources (and sub-resources) are identified by URIs
-
REST Architectural Constraints
We now consider applying REST constraints, together with the consequences of doing so, to web services based on HTTP:-
1. Client Server
2. Uniform Interface
3. Hypermedia
4. Stateless Interaction
5. Caching
6. Layered System
7. Code on Demand (optional)
1. Client Server
Enables multiple organisational domains.
- assume a disconnected system
Separation of concerns.
Improves UI portability.
Simplifies server.
Characteristics of course not unique to REST.
Remember REST is not just for HTTP.
2. Uniform Interface (HTTP)
- Uniform resource identification
- Uniform access methods.
- Universal semantics.
- Manipulation of resources through the exchange of representations.
- "Self-Describing" messages with metadata carrying sufficient information to process the message.
- An immutable, generic, uniform interface which means the same for all resources:-
- GET (Get a representation of the resource, can be cached; URI in – JSON/XML out)
- POST (Create/modify a sub-resource; URI and JSON/XML in – (optionally) JSON/XML out, side effects possible)
- sends data to resource at URI; server decides what to do with it
- PUT (Create/modify a resource ; URI and JSON/XML in)
- puts a resource at the given URI; if one already there, replaces it
- DELETE (Delete a resource)
- various others e.g. HEAD, PATCH, OPTIONS
There is only one fixed interface with universal semantics – loose coupling!
Returned representation can equivalently be JSON or XML.
- negotiated through HTTP headers
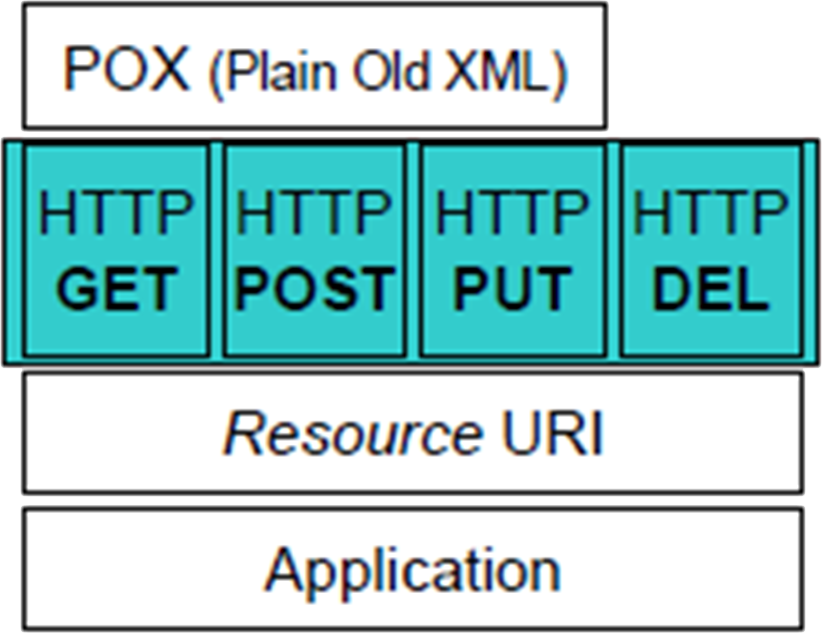
- Uniform Resource Identification through URIs.
- all important resources are identified by one uniform resource identifier mechanism, i.e. In this case URIs
- the layout of the URI is opaque to REST. Human usability is important however but a separate issue
- “Self-Describing” Messages through Metadata
- “self-describing” is rather idealised as, depending on the design/technology it may be downloadable (e.g. Swagger), available only to developers as documentation (e.g. Swagger again) or absent
- multiple resource representations (e.g. XML or JSON)
- JSON
- Atom Syndication Format (or Atom) (XML)
- “Plain Old XML” (POX) using a bespoke application-specific markup only
- certainly no SOAP envelope markup
- Other issues – Remember:
- current HTTP standard is HTTP/1.1
- HTTP has headers that can carry additional detail about the request and the response
- e.g. date/timestamps, cache control, length, content type, whether you want JSON rather than XML back etc.
- HTTP responses have status values
- e.g. 200 OK, 201 Created, 404 Not Found etc.
Uniform Resource Identification through URIs

- No rules – but some established guidelines on what these should look like:-
- on most systems they have to be < 4KB
- prefer nouns to verbs
- keep URLs short
- first example: using positional parameter context is an alternative to name/value pairs
- second example incorporating name/value pairs to support queries is a common format e.g. used by OData
- implementations require APIs to construct and parse URIs
3. Hypermedia
Also known as: HATEOAS
- Hypermedia As The Engine Of Application State
The server response to an operation (e.g. in XML) can contain hyperlinks – these can be chosen from to execute a further request, thereby changing the state of the application i.e. they describe valid state transitions.
- Dynamic as server may change available state transitions with future requests.
- extends longevity of software
- client behaviour not hard-coded in (and no WSDL) – driven by hypermedia
Response type not just JSON/XML – may be any media type supported by client which allows one of a selection of choices to be made.
Support for new media types can be downloaded from server.
- REST code on demand constraint
4. Stateless Interaction
In REST stateless interaction means that the server does not maintain session state i.e. assume the client needs a sequence of calls to the server to achieve a result; the server does not maintain any interim state for these – the client does.
- this aids system scalability
This does not mean that the state of server-side resources, i.e. the resource state, e.g. database table data, doesn’t change when executing a REST application.
Consider session state to be data that could vary by client and by individual request.
Resource state is constant across every client which requests it.
- Each request contains enough context to process the message.
- each request is independent
- self-descriptive messages
- The server should have no knowledge of client state.
- simplifies server
- improves scalability and reliability
- degrades efficiency
The client is free to use a different server to persist application state.
5. Caching
- Optional non-shared caching.
- response indicates if cachable
- especially important with mobile clients
- Advantages and disadvantages:-
- reduces average latency +
- improves efficiency +
- improves scalability +
- degrades reliability –
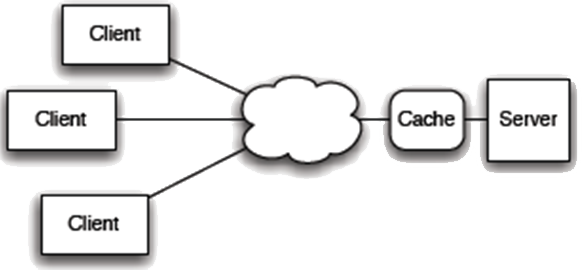
- GET is in fact highly optimised and this should be exploited.
- include appropriate validation and cache
- leave caching to a reverse proxy cache
- i.e. a cache in front of the web server
- use conditional GET on the client
Caching in the web is fundamental to its scalability.
- Three basic web cache techniques:-
- Expiration: HTTP response header can contain a
max-agefield indicating period content is considered valid for. - Validation: HTTP header can contain an
Etagfield (usually a MD5 hash of the resource). GET requests can contain anIf-None-Matchrequest header field. - Combination: a hybrid of the above
With a reverse proxy cache the proxy (acting as a client) also uses these when sending requests to the server.
6. Layered System
Shared caching
Legacy encapsulation
Simplifies client
Improves scalability
Load balancing
- However also adds latency
- there may be intermediaries…
- don’t assume direct connectivity…
7. Code on Demand
Optional
- executable code transferred as representation to client.
For example Java/JavaScript.
Simplifies clients.
Improves extensibility.
Supports the Hypermedia constraint by providing mechanism whereby software support for new media types can be downloaded dynamically later and thereby extends longevity of software.
More about the REST Constraints
- REST has simple constraints, but:-
- communication may be complex
- RESTful system design is non-trivial
- Need to consider how to use HTTP methods to support RESTful use of resources...
- ... and there are few standards for this
- AtomPub and OData are two associated ones to query structured data
-
Semantics of the HTTP Methods
Two characteristics are often discussed with the HTTP methods: safety and whether or not they are idempotent.
- An operation is deemed safe if the resource state at the server remains unchanged.
- GET and HEAD are safe
- PUT and DELETE are not safe
- POST is generally not safe but can be used in ways that the resource is unchanged e.g. to send an email
- An operation is idempotent if the effect of executing it multiple times is the same as executing it once.
- GET, HEAD, PUT and DELETE are idempotent
- POST is generally not idempotent but:-
- can be used in ways that the server state is unchanged
- can in limited circumstances be idempotent (see “Update = POST” on POST vs. PUT slide).
It is usual with database access to use the CRUD verbs.
- Create, Retrieve, Update, Delete
- Naively one might expect a one-to-one mapping to the HTTP methods
- Create = POST, Retrieve = GET, Update = PUT, Delete = DELETE
- In fact the Retrieve = GET and Delete = DELETE mappings are generally OK
- however both PUT and POST can be used to both create and update a resource
- so which do you use where?
- additional business logic (or standardisation) has to be added to correctly map PUT and POST to CRUD
This is not that difficult to do if there is awareness of the issues and care is taken.
- GET, DELETE, PUT
- generally OK but…
- HTTP methods should apply to single resources
- database CRUD operations can apply to many records at once or to cascades
- these issues are largely skipped over in practice
- e.g. a GET could return a serialized collection of sub-resources or a collection of URLs of the sub-resources but these are packaged up as a single resource
POST is a problem because the HTTP RFC only loosely defines its semantics and the server can decide itself what to do with the request.
- e.g. it can be used to send an email rather than create a resource
POST vs. PUT
What behaviour does MS WebAPI recommend?
Create = POST - you are sending a command to the server to create a subordinate of the specified container/folder and it uses some server-side algorithm. (N.B. client does not know new resource URL until creation)
Retrieve = GET
Update = PUT - you are updating the full content of the specified resource and the resource has to already exist
Delete = DELETE
- These are simple and reasonable semantics.
- but there’s no universal standard (AtomPub is another example)
- notice that PUT does not CREATE and POST does not update
- PUT is idempotent
- POST is not idempotent – a new subordinate resource is created with each POST
- Idempotent Update with PUT.
- same result if executed multiple times as executing once
- whole resource in request placed at request URL
HTTP/1.1 PUT /GrafPak/Pictures/Picture3245 ... <full content of a jpg for resource Picture3245... >
- Non-Idempotent Create with POST.
- new resource added every time request executed
- request URL is a container for these new sub-resources (i.e. Pictures)
- exactly how it is processed is up to server
HTTP/1.1 POST /GrafPak/Pictures ... <GrafPak operation="add" type="jpeg"> <[CDATA[ <full content of some picture ... > ]]> </GrafPak>
- the server should respond with appropriate HTTP responses e.g. 201 Created with the new resource’s URL (a sub-resource of Pictures)
Other HTTP methods
Two other less common methods but increasingly used in RESTful interactions:-
- OPTIONS
- OPTIONS is used with a specific resource URL and the server returns a list of the methods it will accept to manipulate the resource (e.g. GET, PUT etc.)
- OPTIONS is safe and idempotent
- PATCH
- PATCH allows for partial updates of a resource
- PUT is updating the whole resource only
- PATCH in fact provides for predictable, transactional, full and partial updates of a resource and for side-effects
- PATCH is not safe nor idempotent
Users example (1)
POST /api/users GET /api/users/4 <User> <FirstName>David</FirstName> <LastName>Coulthard</LastName> </User> 201 Created Location: /api/users/4 200 OK <User> <ID>4</ID> <FirstName>David</FirstName> <LastName>Coulthard</LastName> </User>Create a User.
Get data about specific User.
Note POST is not idempotent and its use has created a sub-resource. The HTTP response contains the location of the new resource. The resource representation is POX.
Users example (2)
GET /api/users/ 200 OK <Users> <User> <ID>1</ID> <FirstName>Fernando</FirstName> <LastName>Alonso</LastName> </User> ..... <User> <ID>4</ID> <FirstName>David</FirstName> <LastName>Coulthard</LastName> </User> </Users>GET is safe and idempotent.
Multiple resources (packaged up as a single resource) – all users.
Users example (3)
PUT /api/users/4 <User> <FirstName>Jim</FirstName> <LastName>Clark</LastName> </User> 204 No Content GET /api/users/4 200 OK <User> <ID>4</ID> <FirstName>Jim</FirstName> <LastName>Clark</LastName> </User>Update an existing resource using PUT.
204 response is correct – it worked but nothing returned
PUT is not safe but is idempotent (and the whole user resource is replaced).
Confirm its update using GET.
Users example (4)
DELETE /api/users/4 GET /api/users/4 200 OK 404 Not Found
- Delete an existing resource using DELETE.
- DELETE is not safe
- subsequent DELETE attempts result in 404 Not Found being returned but this is idempotent as far as the resource is concerned
Confirm its deletion using GET.
-
Model View Controller
WebAPI 2
MS’s REST API development SDK.
Often used and integrated with ASP.NET MVC applications.
extends these to support building REST APIs
Tooling support in VS.
- Not dependent on MVC.
- could be added to any project type…
- however often used in MVC web applications to add REST functionality as much code can be reused
Model View Controller - Review
A software architectural pattern used in many application types.
- not just web applications
Encourages but does not enforce a separation of concerns but that is whole idea...
- aids code reuse and multi-programmer software development
- IDEs like VS generate projects with the code organised along these lines.
- WebAPI can be added to an existing MVC web application to give additional REST API.
- code generation of specialised controllers for REST API
- “scaffolding”
- Models
- encapsulate objects and data
- could be entity classes
- Views
- generate user interface - e.g. forms/tables
- much easier to do JavaScript and CSS
- visually represent model
- Controllers
- interact with user actions
- controller is a set of action methods
- gets request and validates from user, takes information -> model (i.e. business logic which wraps response in model) -> response combined with view and sent to user
Where business logic goes is a moot point between developers but usually actions are lightweight and kick off business logic (but could be embedded in action).
Routing adds a set of rules which when a URL is parsed route requests to correct controller action method.
- defaults exist but under programmer control
Model View Controller – REST/WebAPI 2
Models
- code just reused
- Views
- no views are used at all as there is no rendering
- data as XML and JSON is produced
- media type specified in accept header handled automatically
- Controllers
- specialised controller is added
- no action methods
- special methods are added for HTTP methods
- Routing
- default routing generally OK but can modify routing and implement multiple APIs in same project
- gives complete control of API URLs
WebAPI 2
You could write your own controller for a REST API from scratch
or
- Scaffold a controller (a “Web API 2 Controller” ) automatically:-
- for a bespoke REST API with skeleton methods or
- creating methods for a model based on Entity Framework (EF) or
- code first or database first
- creating OData methods for a model based on entity classes (e.g. for an Entity Framework (EF) relational database or Azure tables)
-
Swagger
- Basic REST has nothing like WSDL (used with SOAP) to describe a RESTful web service.
- SOAP is self-describing through WSDL meta-data
- how do you determine the details of a REST API and of the data returned?
- always hard-code it into clients??
- Various attempts at this for REST over the years, but current most popular is Swagger:-
- uses JSON (although it supports XML) and JSON-Schema to describe REST API metadata i.e. its parameters and messages
- includes open-sourced UI (swagger-ui, entirely in HTML/javascript) double-serving as documentation and ad-hoc testing utility
- also includes open source code generators for a variety of languages to generate code to consume RESTful APIs
- see: 🔗 http://swagger.io/
-
Open Data Protocol (OData)
- OData is a protocol for building REST-based CRUD data services.
- a specific RESTful API for data queries - both access and manipulation
- allows clients to construct URIs that name an entity set, filter among the entities it contains, and traverse relationships to related entities and collections of entities
- also allows metadata of messages to be downloaded
OData is a standard to expose and create/update self-describing data supporting sophisticated queries in URLs.
- easy to expose existing data
Also in this context standardises the required REST request and response headers, status codes, HTTP methods, URL conventions, media types, payload formats and query options etc.
Messages defined in Atom or JSON.
- OData v4.0 from OASIS.
- 🔗 http://www.odata.org/
- originally a MS initiative
- Atom Syndication Format (RFC 4287) or Atom
- originally for web feeds – XML
- a set of entries and metadata
- data can be tagged with domain-specific markup
- Atom Publishing Protocol (RFC 5023) or AtomPub
- AtomPub transmits Atom - XML
- A REST-based protocol defining how to use the HTTP methods to implement the full set of CRUD operations
- OData
- OData built on AtomPub
- OData also now provides equivalent JSON formats for data
- adds sophisticated queries to URLs – OData protocol
- adds internal server OData data model abstracting from actual data implementation
-
Lab 4
Code in Lab 4 zip file.
- RacingDrivers
- REST API – ASP.NET Web Application with MVC 5 and WebAPI 2
- provided complete
- demonstrates REST, use of GET, POST PUT, DELETE, OPTIONS, XML and JSON
- no client – use Fiddler (or Chrome Postman or...)
- do not use for Part B Coursework
- Lab 4 Part 2
- ProductStore
- a Web Application with MVC and VS scaffolding
- i.e. it generates an outline REST API methods controller for you
- JSON only (but you could change it to support XML too)
- uses an Azure table for data persistence
- uses a DTO (Data Transfer Object) class
- adds automatically generated Swagger UI and metadata to service
- includes a .NET client (Console Application) to consume REST API
- uses Swagger service metadata to generate client-side classes
- uses new asynchronous client API
- also shows an additional OData controller
- Lab 4 Parts 3 to 5