-
Overview
- Distribution
- Three-Layer “Monolithic” Architecture
- Service Oriented Architecture
- Microservices
- Replication
- Elasticity, Automation and Load Balancing
- Scaling Techniques
- Synchronous and Asynchronous Communication
- Session State
- Caching
-
Distribution
- “An application is distributed when it is provided by multiple nodes each capable of handling a subset of the requests to the application”
- split the application into smaller services
- the smaller services provide different parts of the application
- the data is split into smaller parts
- possible to place each service at a different node
- better to add a distribution function to decide which request should be addressed where
- but may be set at deployment in configuration files
- spreads the load across multiple nodes
- does not directly address availability issues
- as the functionality is split up
- aids service reuse as it may be common across applications
Designing for Distribution
How should we split up the functionality of applications to achieve effective distribution?
- Industry has been through several architecture approach iterations:-
- Three-Layer “Monolithic”
- Service Oriented Architecture (SOA)
- Microservices
Today for cloud applications we are somewhat between SOA approaches and the adoption of microservices.
Three-Layer “Monolithic” Architecture
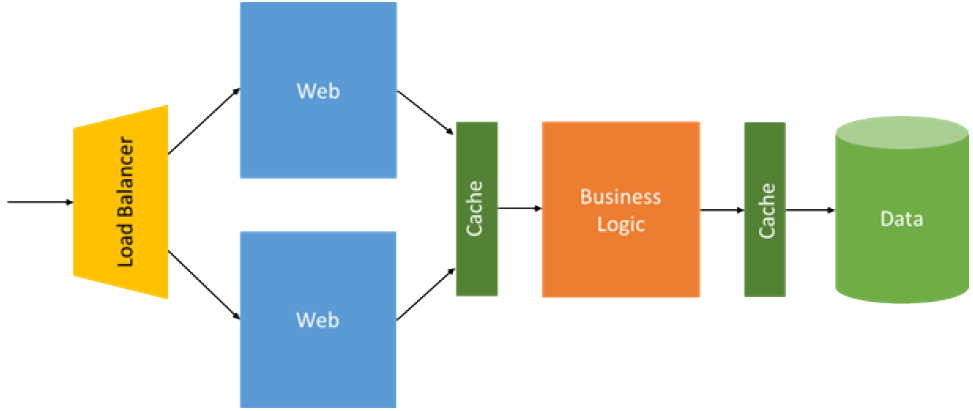
Web application - receives the HTTP request and returns the HTML response (or some associated technology).
Business logic - handles data validation, business rules and task-specific behaviour.
Data - a relational database executing SQL queries called from an API exposed to the business logic.
Classic way to architect such systems from 20 years ago.
Hardware infrastructure largely static (except web layer) i.e. mostly vertical scalability.
different layers on different servers
Complex software layers with long development cycles.
tightly coupled layers
A change to any application service, even a small one, requires its entire layer to be retested and redeployed with application outage as a result.
Dependence on statically-assigned resources and highly-available hardware makes applications susceptible to variations in load and hardware performance.
Intermediate caches to mitigate performance inefficiencies caused by separating compute and data but this adds cost and complexity.
Not generally scalable and only suitable in the cloud for simple applications.
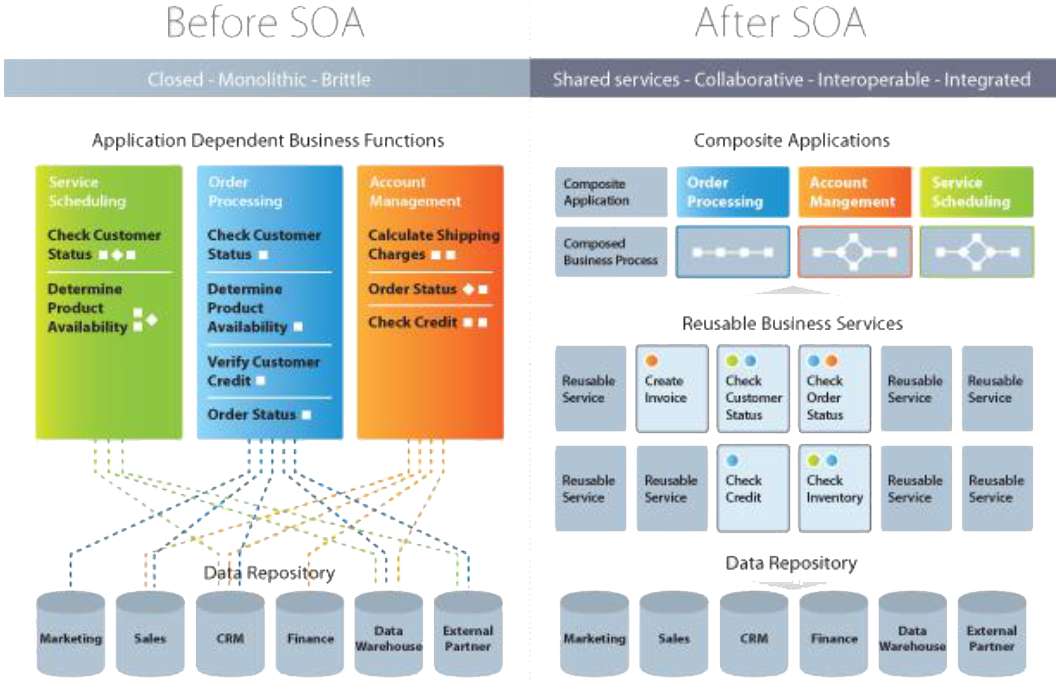
Service Oriented Architecture
A revised approach (set of principles and patterns) to architect complex distributed systems from 10 years ago.
before the advent of the cloud but because this approach was prevalent when the cloud appeared it has been leveraged.
- Service Oriented Architecture = SOA
- originally for enterprise distributed systems but ideas applicable to the cloud
- SOA in the cloud a key area for NIST
- Break monolithic applications into coarse-grained, loosely coupled, reusable services, each exposing a contract as a well-defined interface.
- i.e. coarse grained but finer than previous monolithic layers
- in SOA using a contract to expose a discrete service located through an endpoint is called the edge component pattern
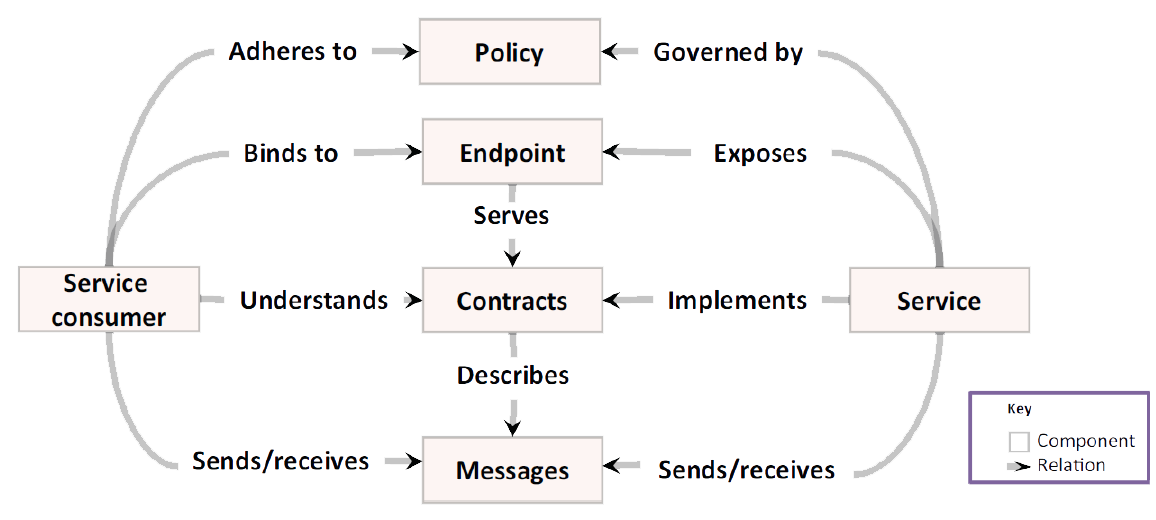
SOA in the Cloud
- A service is a function that is well-defined, self-contained and does not depend on the context or state of other services.
- a bit like an object but at a much coarser granularity
- think of a service as a process which offers a well-defined interface to consumers
- Services should be wrapped in an infrastructure managing their lifecycle.
- e.g. Azure cloud services
- or a WCF service (see later lectures)
- in SOA this is called the service host pattern
- Separation of interface and implementation
- service interface is a formal contract and should change infrequently
- termed loosely coupled as its consumers are minimally impacted by changes to that service or its environment
- if interface needs to change, version it so customers isolated from changes
- implementation may change – that’s ok
- typically communicate by SOAP web services or queues
- queues are better in the cloud – asynchronous
- in SOA this is called the decoupled invocation pattern
- Policies
- updated at runtime and externalized from business logic
- security
- encryption, authentication, authorization
- auditing, service level agreements (SLAs)
- Platform independence
- technology agnostic
- can change infrastructure without affecting consumers
- Location transparency
- consumers do not know location of service
- can move service as platform reconfigured
- hide service instances behind load balancer
- better if located at run-time
- in SOA this is called the virtual endpoint pattern
Microservices
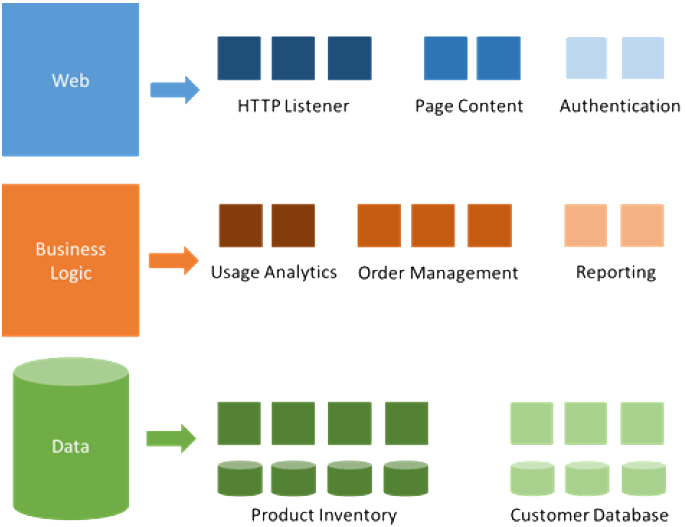
Microservices are independent components that work in concert to deliver the application’s overall functionality.
Each small enough to truly reflect independent concerns such that each implements a single function.
- Microservices is a current approach at the stage of being adopted by cloud applications architects. This has emerged in concert with:-
- DevOps culture (integrating software development and IT to achieve rapid building, testing and reliable releases)
- container technologies and their associated clustering and orchestration tooling
- Microservices are functionally smaller than SOA services but many of the principles remain.
- i.e. a single application is developed as a suite of small autonomous and independently deployable services, each running in its own process and communicating using lightweight mechanisms
- often use RESTful APIs to communicate and are loosely coupled
- in fact many people consider microservices just to be an evolution of SOA but “done right”!
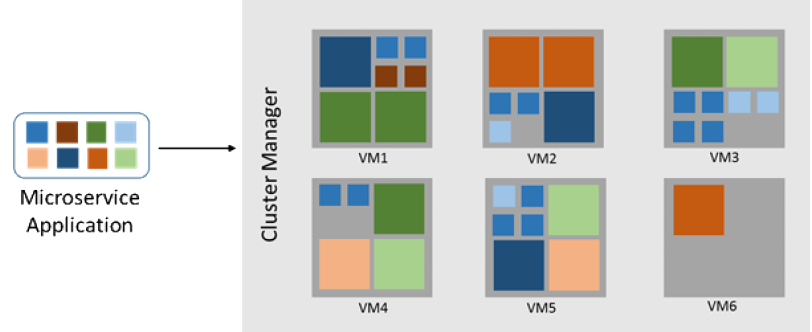
Deployed in containers so fast and efficient deployment to VMs.
Small, independent services that are versioned, deployed, upgraded and easily scaled separately.
Rolling updates, where only a subset of the instances of a single microservice will update at any given time; can also be easily rolled back should problems occur.
Microservices - Application Platforms
- Some additional infrastructure needs to be added to containers (and Docker) to provide a microservices runtime environment:-
- packaging: definition of applications composed of multiple microservices
- service discovery (naming): a repository allowing microservices to find each other at runtime
- cluster management (orchestration): automatic deployment, update operations and scaling etc.
- health checking and metrics collection
- hot migration: transparently moves microservice instances to healthy VMs or servers when the software or hardware on which they are running fails or must be restarted for upgrades
Microservices in the Cloud
- We can split a modern cloud application into three tiers, the first 2 implemented with a set of microservices.
- Presentation Tier
- Business Logic Tier
- Data Tier
Functionality to process the data is implemented in the Business Logic Tier - it is too CPU and memory intensive to embed this as stored procedures directly in the data tier.
Each microservice instance does not have access to any shared data and must communicate with HTTP or queues.
data that it does have to persist is done so locally on the same server to avoid network I/O.
- It is best that microservices in the cloud are stateless i.e. all calls are self contained and thus devoid of context (see later). However this may not be possible:-
- Presentation Tier: depends on web application design
- Business Logic Tier: agreement may be required to update data from 2 or more microservice instances
- note that this introduces distributed transactions which are bad for cloud scalability (see later lecture).
- for one thing it needs locks which introduces state
- and this is ironically exacerbated by having code fine grained...
-
Replication
- “A service is replicated when it has logically identical instances appearing on different nodes of the system”
- copy the service to multiple places
- requests can be addressed at any replica
- whenever the service state is updated, you must maintain consistency (more later but this can be hard – see CAP)
- in systems where any replica can receive updates, this is even harder
- replication can improve performance
- less client-to-server distance, less load on the service
- it is important to place replicas close to the users
- replication improves availability
- should spread nodes to different fault domains to make sure they do not get all disconnected together
- can have servers close in network terms to clients
Elasticity and Automation
- Two aspects:-
- load monitoring: set up some criteria to determine under what conditions the number of service instances is increased or decreased (or number of queues etc.)
- load balancing: share the load fairly between running service instances thereby maximising throughput
- Load monitoring to set instance numbers:-
- based on daily time or date
- after manually watching system
- automatically according to some performance metric of current instances
- CPU utilisation
- memory utilisation
- latency
- queue message processing rate
Load Balancing
- Various approaches are used based on:-
- performance – directs client to the best load balanced node based on its latency or current connection count
- failover – directs client to the primary node unless the primary node is down and then redirects to a backup node.
- round robin – directs client to the nodes in a cyclic fashion
- hash function – uses a hash of the protocol characteristics (e.g. client TCP connection) to determine the node
The load balancer includes some functionality to probe the nodes to discover the appropriate metric.
TCP/HTTP/DNS latency
liveness
Azure and AWS incorporate load balancers
more sophisticated functionality available from 3rd parties
Kemp, Barracuda, Citrix…
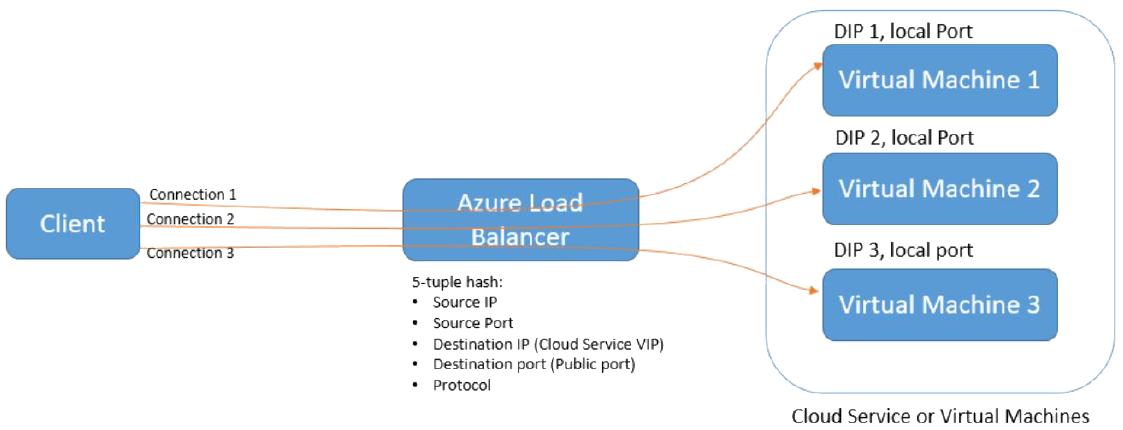
Load Balancing - Azure
A few options but the basic one is a Transport Layer load balancer based on hash based distribution.
Internet facing
- Uses is a 5 field (source IP, source port, destination IP, destination port, protocol type) hash to map traffic to available servers.
- all traffic from same client in a TCP connection goes to same server
- sticky sessions
- but for a new connection with same values goes to another
- so in a sense incorporates some round-robin features
More is at: 🔗 What is Azure Load Balancer?
A discussion on AWS Elastic Load Balancing is at: 🔗 Best Practices in Evaluating Elastic Load Balancing
-
Issues related to Scalability
- Other issues which affect scalability :-
- Synchronous/asynchronous communication
- State Management
- Caching
All three are in fact interrelated.
Synchronous Communication
- If we work synchronously, Client C calls Service S and waits for the response before continuing.
- this is the call semantics we are all familiar with
- these are roles as C may itself be a service
If we scale C (by adding more instances) then we must scale S.
otherwise S cannot cope and performance degrades
If S fails, C will fail as well.
they have a single availability characteristic
Asynchronous Communication
If we can decouple C and S somehow we can work asynchronously and not wait for the result.
- A standard way is to introduce a queue between C and S.
- C and S can scale independently
- web role/worker role pattern
- C can continue if S is down
- have independent availability characteristics
- queue can buffer messages at peak times allowing S to catch up
- may have to scale the queue...
- see lecture on "Data in the Cloud"
State Management
Stateless interaction means that the server does not maintain session state i.e. assume the client needs a sequence of calls to the server to achieve a result; the server does not maintain any interim state for these.
This does not mean that the state of server-side resources, i.e. the resource state (or application state), e.g. table data, doesn’t change when executing a request.
Consider the session state associated with stateful interaction to be data that could vary by client and by individual request.
Resource state is constant across every client which requests it.
State often discussed in terms of the web but it could be any server software.
The HTTP example
- HTTP by itself is stateless.
- it uses client-side session state management
- e.g. cookies which carry the session state in each HTTP call
- HTTP calls are therefore independent and self-contained
So if you have several web servers you can easily send any request to any web server and scale simply behind a simple (round-robin) load balancer.
also much more resilient to faults – send requests simply to another instance
This is the basis of the SOA service instance pattern.
HTTP Session State Management
- However several technologies have introduced server-side state management.
- ASP.NET sessions, Java servlets...
- not so easy to load balance and scale...
Need a distributed cache to share session state between instances.
the worst solution in the cloud, from a performance and scalability standpoint, is to use a relational database backed session state provider
- Stateful interactions are best avoided in cloud applications.
- if possible – e.g. it may be a web app requirement
- and as we saw previously microservices in the Business Logic Tier often use it
The Stateless Cloud
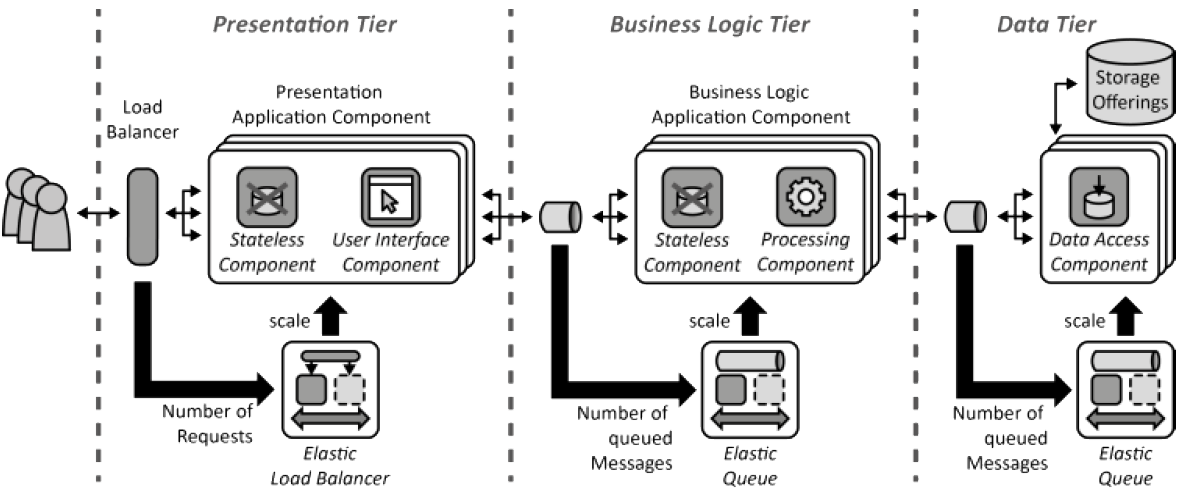
AWS goes stateless...🔗 Three-Tier Cloud Application
Caching
- “The results of a query are cached by saving them at the requesting or intermediate node so that they may be reused instead of repeating the query”.
- this will reduce the number of queries addressed to the actual service/data store
- you must maintain the consistency of cached queries
- usually: do not update them, simply delete them when they become invalid
- how do you decide when to delete?
- expiration – timeout set
- validation – cache management checks whether cache is still valid
- but … studies show over 50% of all HTTP requests are uncacheable
- security, web services, dynamic data…
- however can have a big impact overall on cloud scalability…
Caching in the Cloud
Aim to provide high throughput, low-latency access to commonly accessed application data (and especially static content), by storing the data in memory.
In the cloud the most useful type of cache is a distributed cache, which means the data is not stored in an individual VM server's memory but in another cloud resource.
i.e. in a set of separate specialised VM instances – “cache cluster”
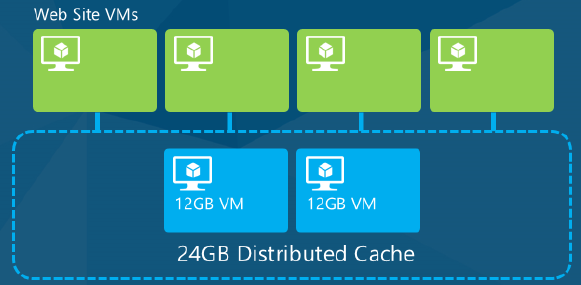
- Advantages:-
- avoids high latency data access to a persistent data store thereby to dramatically improve application responsiveness
- benefits increase the more an application scales, as the throughput limits and latency delays of the persistent data store become more of a limit on overall application performance
- can share session state between web server instances
- the cached data remains accessible through faults and upgrades to the main instances
- acts as a circuit breaker
- can facilitate replicated soft-state in BASE (see later)
- Best used when:-
- do more reads than writes
- a lot of data is shared that does not frequently change
- e.g. for product data rather than for data unique to a user
Cache Population Strategies
On Demand / Cache Aside: The application tries to retrieve data from cache, and when the cache doesn't have the data (a "miss"), the application stores the data in the cache so that it will be available the next time. The next time the application tries to get the same data, it finds what it's looking for in the cache (a "hit"). To prevent fetching cached data that has changed, you invalidate the cache when making changes to the data store.
Background Data Push: Background services push data into the cache on a regular schedule, and the application always pulls from the cache. Works well with high latency data sources that are not required to always return the latest data.
Cloud Caching for real
Distributed in-memory caching been around for a while.
Memcached, NCache...
- Redis now more popular in cloud architectures
- see: 🔗 Introduction to Redis
- a persistent key/value store (see "Data in the Cloud" lecture)
- there is an API
- basically you provide key and value and later the key can be used to retrieve the value
- asynchronous replication between multiple cache servers
- see: 🔗 Replication
- resynchronisation mechanism after recovered network partitions
Redis now both in Azure and AWS ElastiCache.
open source - Linux with a MS port to Windows Server