-
Overview
- Consistency
- strong, weak, eventual
- ACID
- transactions
- distributed transactions, 2PC
- CAP Theorem
- what’s wrong with transactions in the cloud?
- BASE
- Internet design style
- eventual consistency revisited
- does it matter?
ACID in the cloud
-
Consistency
Strong Consistency
- after the update completes, any subsequent access will return the same updated value
Weak Consistency
- it is not guaranteed that subsequent accesses will return the updated value
- Eventual Consistency
- specific form of weak consistency
- it is guaranteed that if no new updates are made to object, eventually all accesses will return the last updated value (e.g., propagate updates to replicas in a lazy, asynchronous fashion)
We’ll review what all this means and what the impact is on cloud computing.
Problems of Large-Scale Distributed Systems
- Latency is zero.
- no it isn’t - this is the 2nd fallacy of distributed computing. See: 🔗 http://rgoarchitects.com/Files/fallacies.pdf
- data propagation is limited to a fraction of the speed of light (~30ms across Atlantic)
- note that an architecture that is tolerant of high latency will operate perfectly well with low latency
Data is geographically distributed.
Customers demand reasonably consistent performance around the world.
Latency tolerance can only be achieved by introducing asynchronous interactions.
- a shift from the familiar synchronous interactions
A Specific Problem
Imagine M clients and N server replicas (labelled C1-M and S1-N).
- Imagine x has value 3 (in all server replicas)
- C1 requests write(x, 5) from S4
- C2 requests read(x) from S3
- what should occur?
- With strong consistency, the distributed system behaves as if there is no replication present: -
- i.e. in above, C2 should get the value 5
- requires coordination between all servers
- With weak consistency, C2 may get 3 or 5 (or …?)
- less satisfactory, but much easier to implement
- but in reality not much good for most applications, consider:
With eventual consistency, C2 may get 3 and if it asks again at some later time 5
- more suitable for geo-distribution between cloud regions
However this is an issue not just confined to replication.
- also an issue for distribution
- Imagine 2 bank accounts, the accounts are on different servers and we’re moving money between them.
- the credit to one balance must happen as well as the debit in the other
- if one fails the other must fail too – the whole operation must be atomic and you must be able to roll-back the state of the entire system
- e.g. if there isn’t enough money in the account to be debited the other update must fail too and both values must be rolled-back
- This is traditionally implemented by using distributed transaction processing.
- composite operations which execute atomically
- this strong consistency is called ACID in this context
- ACID consistency is usually achieved using locking
- but does distributed transaction processing scale in the cloud?
Two-Phase Commit Protocol (2PC)
In terms of replication we need to ensure any update propagates to all replicas before allowing any subsequent reads.
- One solution:-
- Ca requests Sa to update x
- when Sa receives request to update x, first locks x at all replicas including self (Sa ... Sn )
- once locking successful, Sa makes update and propagates update to all other replicas to apply and then acknowledge it has been applied
- finally, Sa instructs all replicas to unlock
- once Ca has an acknowledgement for its write (i.e. the commit has succeeded everywhere) , all C (including Ca) will see update
Need also to handle application errors (e.g. not enough money...)
- add step to tentatively apply update, and only actually apply (“commit”) update at each replica if all replicas are in agreement otherwise send abort and unlock
2PC is a standard way to implement distributed transactions.
Notice 2PC is synchronous as “subsequent reads” wait until the commit happens.
-
ACID
- Transactions in general implement ACID semantics:-
- Atomicity: either the operation (e.g. a write) is performed on all replicas or is not performed on any of them
- Consistency: after each operation all replicas reach the same state
- Isolation: no operation (e.g., read) can see the data from another operation (e.g. a write) in an intermediate state
- the point of this is to allow transactions accessing the same data to execute concurrently
- Durability: once a write has been successful, that write will persist indefinitely
Modern relational database systems e.g. Oracle, DB2, MS SQL Server, implement transaction processing.
or Use a transaction monitor e.g. Microsoft Distributed Transaction Coordinator (MSDTC).
Transactions in the Cloud
In a limited sense, in a single data-centre, transactions can be used.
- However distributed transaction processing does not scale well to many nodes.
- synchronous
- system will just grind to a halt...
- It won’t work across geographically distributed data-centres.
- e.g. AWS latency across USA is 10ms - which is too high to make it work
- system will also just grind to a halt...
It does not tolerate node faults or network partitions.
- in the cloud at scale these are a fact of life...
To better identify the problem we use the CAP theorem.
-
CAP Theorem
Brewer 2000
- What goals might you want from a distributed system?
- Consistency: by this it means strong consistency
- Availability: a guarantee that every request receives a response about whether it was successful or failed
- Partition-tolerance: the system continues to operate despite arbitrary message loss (nodes or network faults or outage)
Brewer proposed that in any distributed system we can satisfy any two of these guarantees at the same time, but not all three.
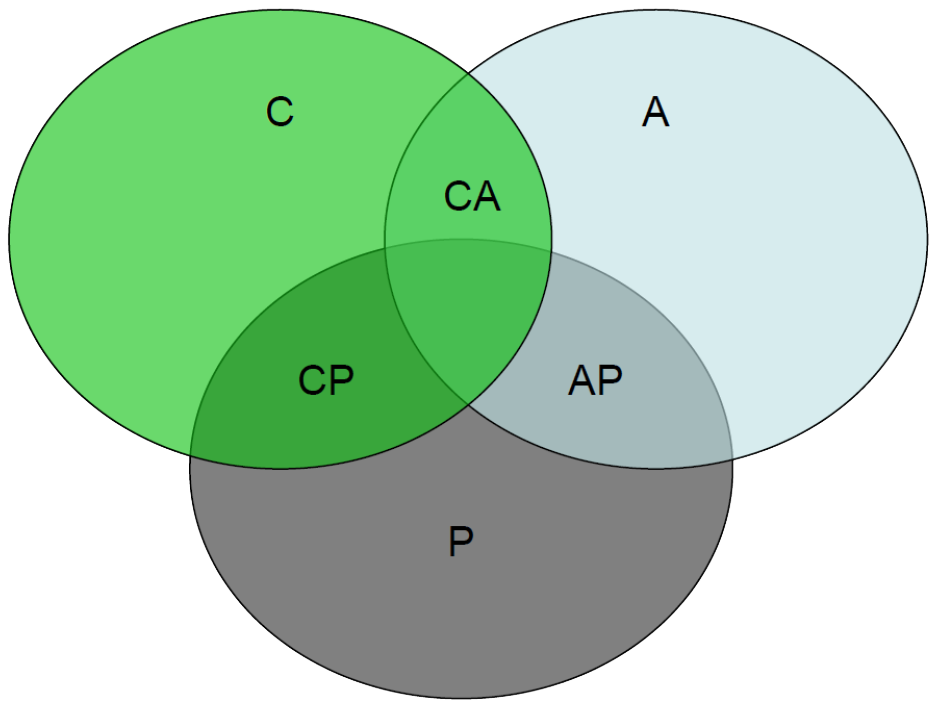
CAP with Distributed Transactions
Consistency: strong consistency is the big thing about transactions.
Availability: users need a response so dbms guarantee good availability.
- so partition-tolerance has to be dropped...
- but if in 2PC you can't connect to a node after acquiring a lock then the resource remains locked and the system is not available...
- therefore distributed transaction implementations are not a class of applications which exhibit partition-tolerance
- transaction processing systems are “CA systems”
This is OK in a lan-based distributed system where you can sometimes drop the partition-tolerance requirement by using redundant networks.
- but it won’t work scaled out in the cloud...
CAP in the Cloud
- Availability: with web applications the end user will not tolerate response times above a certain level.
- prioritise availability over consistency
- AWS say: “even the slightest outage has significant financial consequences and impacts customer trust”
Partition-tolerance: at scale faults will occur all the time .
- all cloud applications should be architected to tolerate partitions
so consistency has to give...
- the cloud is (largely) an “AP system”
Cloud based systems usually use weaker eventual consistency.
- However you should note that both consistency and availability are more continuous quantities than suggested on the first “CAP Theorem” slide.
- many real-world use cases simply do not require strong consistency
- availability is not all or nothing - has to be traded off against the appropriate level of consistency guarantees needed by a particular application
CAP Theorem (an alternative view)
“Provide a consistent view of distributed data at the cost of blocking access to that data while any inconsistencies are resolved. This may take an indeterminate time, especially in systems that exhibit a high degree of latency or if a network failure [fault] causes loss of connectivity to one or more partitions.”
or
“Provide immediate access to the data at the risk of it being inconsistent across sites. Traditional database management systems focus on providing strong consistency, whereas cloud-based solutions that utilize partitioned data stores are typically motivated by ensuring higher availability, and are therefore more oriented towards eventual consistency.”
-
BASE
- An alternative to ACID is BASE:-
- Basically Available: the system is available and can provide a fast response, but not necessarily all replicas are available at any given point in time
- Soft-state: data only in memory (not durable)
- if replica disconnected asynchronously resync
- if a replica crashes, reboot it to a clean state
- improved with a distributed cache or
- pass data to third party service to persist
- Eventually consistent: after a certain time all replicas are consistent, but at any given time this might not be the case
An “AP system” – “Internet design style”.
- Consequences:-
- code proves to be much more concurrent, hence faster
- encourages asynchronous communication
- send a response to the user before you have complete response yourself from elsewhere
- elimination of locking and early responses to users make end-user experience fast and positive
- so this is a lot more scalable
- however it is more work and harder for the application developer
- in effect we have weakened the semantics of operations and have to code the application to work correctly anyhow
- the functionality given by transactions has to implemented
- need to modify the end-user application to mask any asynchronous side-effects that might be noticeable
But in different classes of applications, does it matter?
Implementing Eventual Consistency
- Can be implemented with two steps:-
- all writes eventually propagate to all replicas
- writes, when they arrive, are written to a log and applied in the same order at all replicas
Therefore consistency does happen (eventually...).
Easily done with timestamps.
Same technique can be applied to separate cloud regions during disaster recovery.
BASE – does it matter?
- Suppose an eBay auction is running fast and furious.
- does every single bidder necessarily see every bid?
- and do they see them in the identical order?
Clearly, everyone needs to see the winning bid.
But slightly different bidding histories shouldn’t hurt much, and if this makes eBay 10x faster, the speed may be worth the slight change in behaviour!
- Upload a YouTube video, then search for it
- you may not see it immediately
- change the “initial frame” (they let you pick)
- update might not be visible for an hour
Access a FaceBook page when your friend says she’s posted a photo from the party
you may see an

- OneDrive/DropBox are examples of one of the first classic cloud applications.
- local computers keep local copies of the files
- also support region replication
- you change/create a file locally but OneDrive/DropBox syncs asynchronously
- other local copies will be out of step for a few minutes…
-
ACID in the cloud
Various ways to make ACID transactions run better for cloud deployment.
Sagas: remove need for a distributed transaction by splitting it up into smaller local transactions. An additional set of compensating transactions are implemented to be executed on error conditions to undo the work and rewind.
see: - 🔗 Sagas
Early release: modifications to the 2PC protocol to release locks early. However this may shift a system bottlenecks somewhere else dependent on application behaviour. It may also cause many cascaded aborts.